Assess the Performance Improvement
After resolving the memory access issue, run the HPC Performance Characterization analysis. This is another recommendation from your Performance Snapshot result.
Run HPC Performance Characterization Analysis
- In the Intel® VTune™ Profiler welcome screen, click Configure Analysis.
- Click anywhere in the HOW pane to open the Analysis Tree.
- In the Parallelism group, select HPC Performance Characterization.
- Click Start to run the analysis.
Depending on your compiler and IDE, when configuring the analysis, you may need to browse to a different executable that was generated during recompilation in the previous step.
Interpret Your Result
Once the HPC Performance Characterization analysis is completed, the result displays in the Summary window.
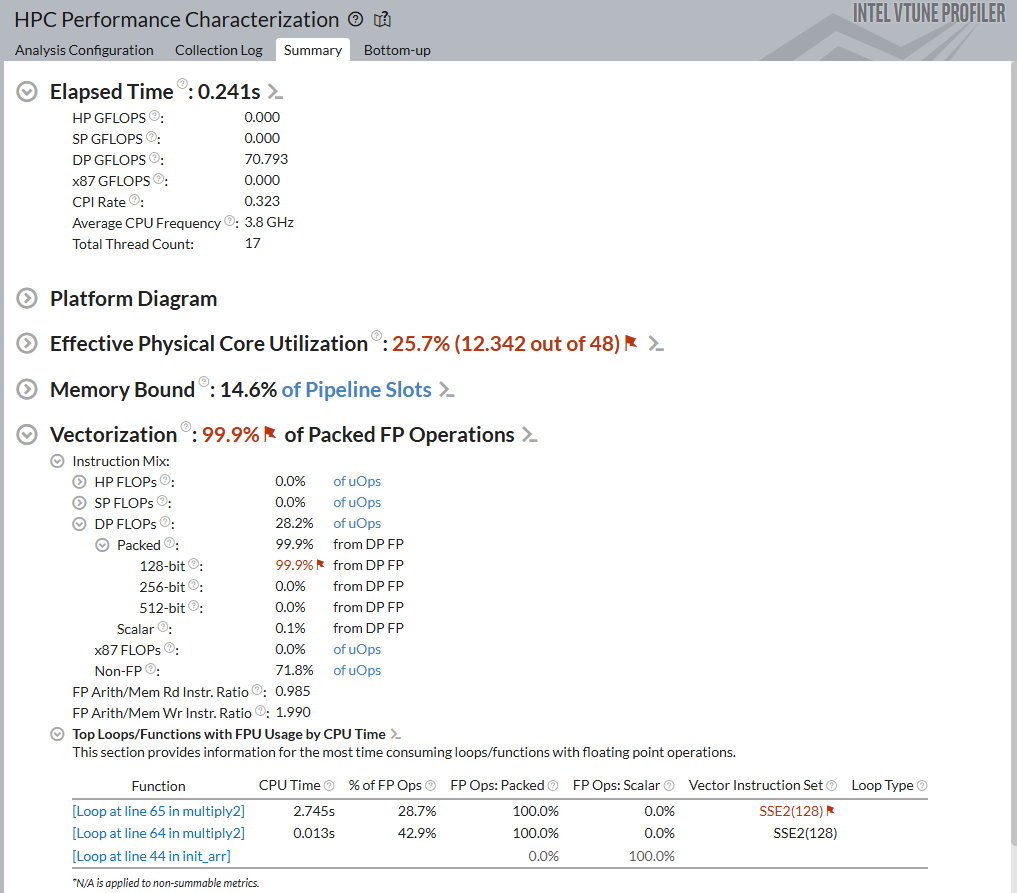
In the Summary window, you can observe that:
The Elapsed Time has reduced significantly. This improvement happened because you removed the memory access bottleneck.
The overall Vectorization metric is equal to 99.9%, which indicates that the code was vectorized. However, the metric is still flagged in red as a bottleneck because the vectorization was not optimal. This analysis ran on a machine that used an Intel® processor capable of using the AVX512 instruction set. The Vectorization metric indicates that 99.9% of instructions were executed using 128-bit registers. This implies that none of the 256-bit and 512-bit wide registers were used. Therefore, Intel® VTune™ Profiler flags the 99.9% utilization of 128-bit vector registers as an issue.
In the Vectorization section, focus on the Top Loops/Functions with FPU Usage by CPU Time subsection.
Note that the main loop of the multiply2 function was vectorized using the older SSE2 instruction set, while compilation and analysis were performed on a processor that supports AVX512. Therefore, a portion of hardware resources remains underutilized.
The next step is to enable platform-appropriate vectorization.