Visible to Intel only — GUID: GUID-AE09A031-E095-4BCD-B2DF-ADEEDFE28B67
Package Contents
Parallelizing Simple Loops
Parallelizing Complex Loops
Parallelizing Data Flow and Dependence Graphs
Work Isolation
Exceptions and Cancellation
Containers
Mutual Exclusion
Timing
Memory Allocation
The Task Scheduler
Design Patterns
Migrating from Threading Building Blocks (TBB)
Constrained APIs
Invoke a Callable Object
Appendix A Costs of Time Slicing
Appendix B Mixing With Other Threading Packages
References
parallel_for_each Body semantics and requirements
parallel_sort ranges interface extension
TBB_malloc_replacement_log Function
Parallel Reduction for rvalues
Type-specified message keys for join_node
Scalable Memory Pools
Helper Functions for Expressing Graphs
concurrent_lru_cache
task_group extensions
The customizing mutex type for concurrent_hash_map
Waiting for Single Messages in Flow Graph
Visible to Intel only — GUID: GUID-AE09A031-E095-4BCD-B2DF-ADEEDFE28B67
Non-Linear Pipelines
Template function parallel_pipeline supports only linear pipelines. It does not directly handle more baroque plumbing, such as in the diagram below.
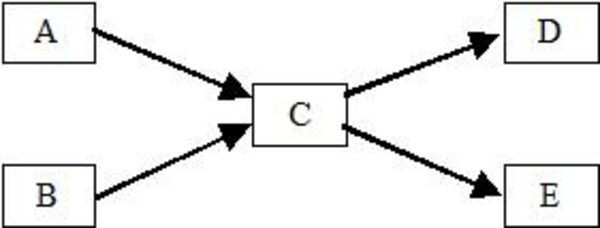
However, you can still use a pipeline for this. Just topologically sort the filters into a linear order, like this:
The light gray arrows are the original arrows that are now implied by transitive closure of the other arrows. It might seem that lot of parallelism is lost by forcing a linear order on the filters, but in fact the only loss is in the latency of the pipeline, not the throughput. The latency is the time it takes a token to flow from the beginning to the end of the pipeline. Given a sufficient number of processors, the latency of the original non-linear pipeline is three filters. This is because filters A and B could process the token concurrently, and likewise filters D and E could process the token concurrently.
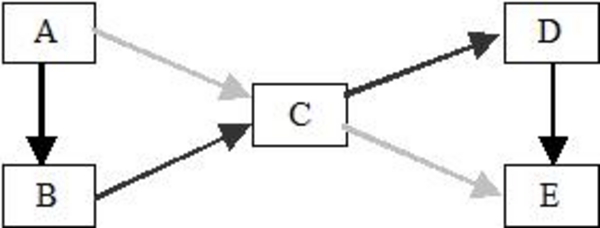
In the linear pipeline, the latency is five filters. The behavior of filters A, B, D and E above may need to be modified in order to properly handle objects that don’t need to be acted upon by the filter other than to be passed along to the next filter in the pipeline.
The throughput remains the same, because regardless of the topology, the throughput is still limited by the throughput of the slowest serial filter. If parallel_pipeline supported non-linear pipelines, it would add a lot of programming complexity, and not improve throughput. The linear limitation of parallel_pipeline is a good tradeoff of gain versus pain.