Visible to Intel only — GUID: GUID-15941821-F66D-483D-931D-DE70AD1EFF14
Package Contents
Parallelizing Simple Loops
Parallelizing Complex Loops
Parallelizing Data Flow and Dependence Graphs
Work Isolation
Exceptions and Cancellation
Floating-point Settings
Containers
Mutual Exclusion
Timing
Memory Allocation
The Task Scheduler
Design Patterns
Migrating from Threading Building Blocks (TBB)
Constrained APIs
Appendix A Costs of Time Slicing
Appendix B Mixing With Other Threading Packages
References
parallel_for_each Body semantics and requirements
parallel_sort ranges interface extension
TBB_malloc_replacement_log Function
Type-specified message keys for join_node
Scalable Memory Pools
Helper Functions for Expressing Graphs
concurrent_lru_cache
task_group extensions
The customizing mutex type for concurrent_hash_map
Visible to Intel only — GUID: GUID-15941821-F66D-483D-931D-DE70AD1EFF14
parallel_reduce
A loop can do a reduction, as in this summation:
float SerialSumFoo( float a[], size_t n ) {
float sum = 0;
for( size_t i=0; i!=n; ++i )
sum += Foo(a[i]);
return sum;
}
If the iterations are independent, you can parallelize this loop using the template class parallel_reduce as follows:
float ParallelSumFoo( const float a[], size_t n ) {
SumFoo sf(a);
parallel_reduce( blocked_range<size_t>(0,n), sf );
return sf.my_sum;
}
The class SumFoo specifies details of the reduction, such as how to accumulate subsums and combine them. Here is the definition of class SumFoo:
class SumFoo {
float* my_a;
public:
float my_sum;
void operator()( const blocked_range<size_t>& r ) {
float *a = my_a;
float sum = my_sum;
size_t end = r.end();
for( size_t i=r.begin(); i!=end; ++i )
sum += Foo(a[i]);
my_sum = sum;
}
SumFoo( SumFoo& x, split ) : my_a(x.my_a), my_sum(0) {}
void join( const SumFoo& y ) {my_sum+=y.my_sum;}
SumFoo(float a[] ) :
my_a(a), my_sum(0)
{}
};
Note the differences with class ApplyFoo from parallel_for. First, operator() is notconst. This is because it must update SumFoo::my_sum. Second, SumFoo has a splitting constructor and a method join that must be present for parallel_reduce to work. The splitting constructor takes as arguments a reference to the original object, and a dummy argument of type split, which is defined by the library. The dummy argument distinguishes the splitting constructor from a copy constructor.
TIP:
In the example, the definition of operator() uses local temporary variables (a, sum, end) for scalar values accessed inside the loop. This technique can improve performance by making it obvious to the compiler that the values can be held in registers instead of memory. If the values are too large to fit in registers, or have their address taken in a way the compiler cannot track, the technique might not help. With a typical optimizing compiler, using local temporaries for only written variables (such as sum in the example) can suffice, because then the compiler can deduce that the loop does not write to any of the other locations, and hoist the other reads to outside the loop.
When a worker thread is available, as decided by the task scheduler, parallel_reduce invokes the splitting constructor to create a subtask for the worker. When the subtask completes, parallel_reduce uses method join to accumulate the result of the subtask. The graph at the top of the following figure shows the split-join sequence that happens when a worker is available:
Graph of the Split-join Sequence 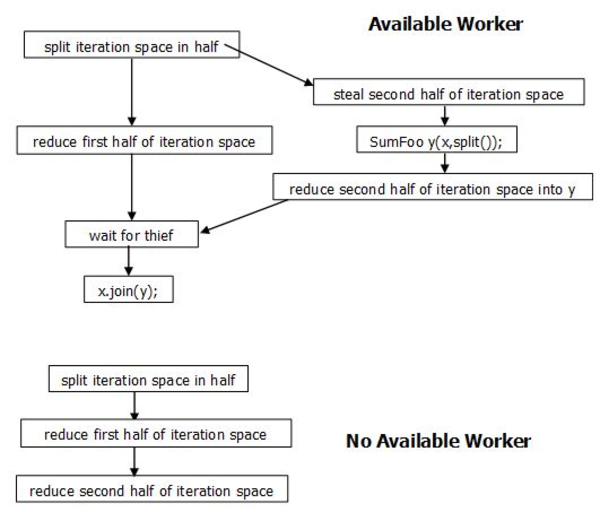
An arrows in the above figure indicate order in time. The splitting constructor might run concurrently while object x is being used for the first half of the reduction. Therefore, all actions of the splitting constructor that creates y must be made thread safe with respect to x. So if the splitting constructor needs to increment a reference count shared with other objects, it should use an atomic increment.
If a worker is not available, the second half of the iteration is reduced using the same body object that reduced the first half. That is the reduction of the second half starts where reduction of the first half finished.
CAUTION:
Since split/join are not used if workers are unavailable, parallel_reduce does not necessarily do recursive splitting.
CAUTION:
Since the same body might be used to accumulate multiple subranges, it is critical that operator() not discard earlier accumulations. The code below shows an incorrect definition of SumFoo::operator().
class SumFoo {
...
public:
float my_sum;
void operator()( const blocked_range<size_t>& r ) {
...
float sum = 0; // WRONG – should be 'sum = my_sum".
...
for( ... )
sum += Foo(a[i]);
my_sum = sum;
}
...
};
With the mistake, the body returns a partial sum for the last subrange instead of all subranges to which parallel_reduce applies it.
The rules for partitioners and grain sizes for parallel_reduce are the same as for parallel_for.
parallel_reduce generalizes to any associative operation. In general, the splitting constructor does two things:
Copy read-only information necessary to run the loop body.
Initialize the reduction variable(s) to the identity element of the operation(s).
The join method should do the corresponding merge(s). You can do more than one reduction at the same time: you can gather the min and max with a single parallel_reduce.
NOTE:
The reduction operation can be non-commutative. The example still works if floating-point addition is replaced by string concatenation.