Visible to Intel only — GUID: GUID-C77D53C8-250F-4058-B086-69A7A824EF3C
Package Contents
Parallelizing Simple Loops
Parallelizing Complex Loops
Parallelizing Data Flow and Dependence Graphs
Work Isolation
Exceptions and Cancellation
Containers
Mutual Exclusion
Timing
Memory Allocation
The Task Scheduler
Design Patterns
Migrating from Threading Building Blocks (TBB)
Constrained APIs
Appendix A Costs of Time Slicing
Appendix B Mixing With Other Threading Packages
References
oneapi::tbb::info namespace
parallel_for_each Body semantics and requirements
parallel_sort ranges interface extension
Type-specified message keys for join_node
Scalable Memory Pools
Helper Functions for Expressing Graphs
concurrent_lru_cache
task_arena::constraints extensions
oneapi::tbb::info namespace extensions
task_group extensions
The customizing mutex type for concurrent_hash_map
Visible to Intel only — GUID: GUID-C77D53C8-250F-4058-B086-69A7A824EF3C
Controlling Chunking
Chunking is controlled by a partitioner and a grainsize. To gain the most control over chunking, you specify both.
Specify simple_partitioner() as the third argument to parallel_for. Doing so turns off automatic chunking.
Specify the grainsize when constructing the range. The thread argument form of the constructor is blocked_range<T>(begin,end,grainsize). The default value of grainsize is 1. It is in units of loop iterations per chunk.
If the chunks are too small, the overhead may exceed the performance advantage.
The following code is the last example from parallel_for, modified to use an explicit grainsize G.
#include "oneapi/tbb.h"
void ParallelApplyFoo( float a[], size_t n ) {
parallel_for(blocked_range<size_t>(0,n,G), ApplyFoo(a),
simple_partitioner());
}
The grainsize sets a minimum threshold for parallelization. The parallel_for in the example invokes ApplyFoo::operator() on chunks, possibly of different sizes. Let chunksize be the number of iterations in a chunk. Using simple_partitioner guarantees that [G/2] <= chunksize <= G.
There is also an intermediate level of control where you specify the grainsize for the range, but use an auto_partitioner and affinity_partitioner. An auto_partitioner is the default partitioner. Both partitioners implement the automatic grainsize heuristic described in Automatic Chunking. An affinity_partitioner implies an additional hint, as explained later in Section Bandwidth and Cache Affinity. Though these partitioners may cause chunks to have more than G iterations, they never generate chunks with less than [G/2] iterations. Specifying a range with an explicit grainsize may occasionally be useful to prevent these partitioners from generating wastefully small chunks if their heuristics fail.
Because of the impact of grainsize on parallel loops, it is worth reading the following material even if you rely on auto_partitioner and affinity_partitioner to choose the grainsize automatically.
|
|
|---|---|
Case A |
Case B |


The above figure illustrates the impact of grainsize by showing the useful work as the gray area inside a brown border that represents overhead. Both Case A and Case B have the same total gray area. Case A shows how too small a grainsize leads to a relatively high proportion of overhead. Case B shows how a large grainsize reduces this proportion, at the cost of reducing potential parallelism. The overhead as a fraction of useful work depends upon the grainsize, not on the number of grains. Consider this relationship and not the total number of iterations or number of processors when setting a grainsize.
A rule of thumb is that grainsize iterations of operator() should take at least 100,000 clock cycles to execute. For example, if a single iteration takes 100 clocks, then the grainsize needs to be at least 1000 iterations. When in doubt, do the following experiment:
Set the grainsize parameter higher than necessary. The grainsize is specified in units of loop iterations. If you have no idea of how many clock cycles an iteration might take, start with grainsize=100,000. The rationale is that each iteration normally requires at least one clock per iteration. In most cases, step 3 will guide you to a much smaller value.
Run your algorithm.
Iteratively halve the grainsize parameter and see how much the algorithm slows down or speeds up as the value decreases.
A drawback of setting a grainsize too high is that it can reduce parallelism. For example, if the grainsize is 1000 and the loop has 2000 iterations, the parallel_for distributes the loop across only two processors, even if more are available. However, if you are unsure, err on the side of being a little too high instead of a little too low, because too low a value hurts serial performance, which in turns hurts parallel performance if there is other parallelism available higher up in the call tree.
TIP:
You do not have to set the grainsize too precisely.
The next figure shows the typical “bathtub curve” for execution time versus grainsize, based on the floating point a[i]=b[i]*c computation over a million indices. There is little work per iteration. The times were collected on a four-socket machine with eight hardware threads.
Wall Clock Time Versus Grainsize 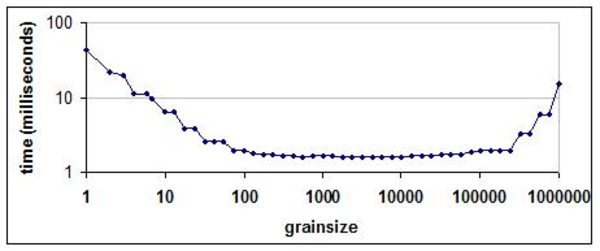
The scale is logarithmic. The downward slope on the left side indicates that with a grainsize of one, most of the overhead is parallel scheduling overhead, not useful work. An increase in grainsize brings a proportional decrease in parallel overhead. Then the curve flattens out because the parallel overhead becomes insignificant for a sufficiently large grainsize. At the end on the right, the curve turns up because the chunks are so large that there are fewer chunks than available hardware threads. Notice that a grainsize over the wide range 100-100,000 works quite well.
TIP:
A general rule of thumb for parallelizing loop nests is to parallelize the outermost one possible. The reason is that each iteration of an outer loop is likely to provide a bigger grain of work than an iteration of an inner loop.
NOTE:
Product and Performance Information
Performance varies by use, configuration and other factors. Learn more at www.intel.com/PerformanceIndex. Notice revision #20201201