Intel® oneAPI Collective Communications Library (oneCCL) Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-AEDF3B5C-F5B2-468C-83E0-0F5A34D37A97
Device Communication
The communication operations between devices are provided by Communicator.
The example below demonstrates the main concepts of communication on device memory buffers.
Example
Consider a simple oneCCL allreduce example for GPU:
Create oneCCL communicator objects with user-supplied size, rank <-> SYCL device mapping, SYCL context and key-value store:
auto ccl_context = ccl::create_context(sycl_context); auto ccl_device = ccl::create_device(sycl_device); auto comms = ccl::create_communicators( size, vector_class<pair_class<size_t, device>>{ { rank, ccl_device } }, ccl_context, kvs);Create oneCCL stream object from user-supplied sycl::queue object:
auto stream = ccl::create_stream(sycl_queue);Initialize send_buf (in real scenario it is supplied by the user):
const size_t elem_count = <N>; /* using SYCL buffer and accessor */ auto send_buf_host_acc = send_buf.get_host_access(h, sycl::write_only); for (idx = 0; idx < elem_count; idx++) { send_buf_host_acc[idx] = rank; }/* or using SYCL USM */ for (idx = 0; idx < elem_count; idx++) { send_buf[idx] = rank; }For demonstration purposes, modify the send_buf on the GPU side:
/* using SYCL buffer and accessor */ sycl_queue.submit([&](sycl::handler& h) { auto send_buf_dev_acc = send_buf.get_access<mode::write>(h); h.parallel_for(range<1>{elem_count}, [=](item<1> idx) { send_buf_dev_acc[idx] += 1; }); });/* or using SYCL USM */ for (idx = 0; idx < elem_count; idx++) { send_buf[idx]+ = 1; }allreduce invocation performs reduction of values from all processes and then distributes the result to all processes. In this case, the result is an array with elem_count elements, where all elements are equal to the sum of arithmetical progression:
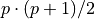
std::vector<event> events; for (auto& comm : comms) { events.push_back(ccl::allreduce(send_buf, recv_buf, elem_count, reduction::sum, comm, streams[comm.rank()])); } for (auto& e : events) { e.wait(); }Check the correctness of allreduce operation on the GPU:
/* using SYCL buffer and accessor */ auto comm_size = comm.size(); auto expected = comm_size * (comm_size + 1) / 2; sycl_queue.submit([&](handler& h) { auto recv_buf_dev_acc = recv_buf.get_access<mode::write>(h); h.parallel_for(range<1>{elem_count}, [=](item<1> idx) { if (recv_buf_dev_acc[idx] != expected) { recv_buf_dev_acc[idx] = -1; } }); }); ... auto recv_buf_host_acc = recv_buf.get_host_access(sycl::read_only); for (idx = 0; idx < elem_count; idx++) { if (recv_buf_host_acc[idx] == -1) { std::count << "unexpected value at index " << idx << std::endl; break; } }/* or using SYCL USM */ auto comm_size = comm.size(); auto expected = comm_size * (comm_size + 1) / 2; for (idx = 0; idx < elem_count; idx++) { if (recv_buf[idx] != expected) { std::count << "unexpected value at index " << idx << std::endl; break; } }