Visible to Intel only — GUID: GUID-625F9FBB-1A89-4266-88B8-909E678EC6DF
Single-Source Compilation
Invoke the Compiler
Standard Intel® oneAPI DPC++/C++ Compiler Options
Example Compilation
Compilation Flow Overview
Traditional Compilation Flow (Host-only Application)
Compilation Flow for SYCL Offload Code
JIT Compilation Flow
AOT Compilation Flow
Fat Binary
CPU Flow
GPU Flow
FPGA Flow
Visible to Intel only — GUID: GUID-625F9FBB-1A89-4266-88B8-909E678EC6DF
Compilation Flow Overview
When you create a program with offload, the compiler must generate code for both the host and the device. oneAPI tries to hide this complexity from the developer. The developer simply compiles a SYCL* application using the Intel® oneAPI DPC++ Compiler with icpx -fsycl, and the same compile command generates both host and device code.
NOTE:
In addition to Intel® processors listed in the System Requirements, AMD* (Linux* only) and NVIDIA* (Linux and Windows*) GPUs may also be targeted:
To use an AMD* GPU with the Intel® oneAPI DPC++ Compiler, install the oneAPI for AMD GPUs plugin from Codeplay.
To use an NVIDIA* GPU with the Intel® oneAPI DPC++ Compiler, install the oneAPI for NVIDIA GPUs plugin from Codeplay.
For device code, two options are available: Just-in-Time (JIT) compilation and Ahead-of-Time (AOT) compilation, with JIT being the default. This section describes how host code is compiled, and the two options for generating device code. Additional details are available in Chapter 13 of the Data Parallel C++ book.
Traditional Compilation Flow (Host-only Application)
The traditional compilation flow is a standard compilation like the one used for C, C++, or other languages, used when there is no offload to a device.
The traditional compilation phases are shown in the following diagram:
Traditional compilation phases

The front end translates the source into an intermediate representation and then passes that representation to the back end.
The back end translates the intermediate representation to object code and emits an object file (host.obj on Windows*, host.o on Linux*).
One or more object files are passed to the linker.
The linker creates an executable.
The application runs.
Compilation Flow for SYCL Offload Code
The compilation flow for SYCL offload code adds steps for device code to the traditional compilation flow, with JIT and AOT options for device code. In this flow, the developer compiles a SYCL application with icpx -fsycl, and the output is an executable containing both host and device code.
The basic compilation phases for SYCL offload code are shown in the following diagram:
Basic compilation phases for SYCL offload code
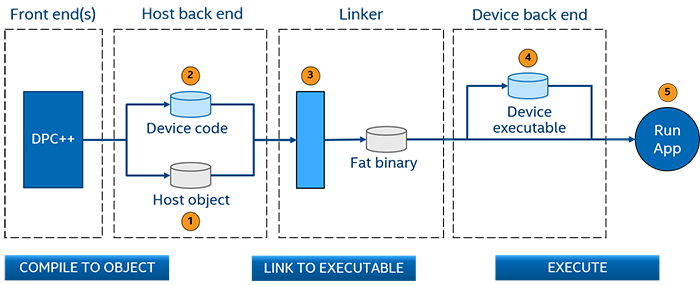
The host code is translated to object code by the back end.
The device code is translated to either a SPIR-V* or device binary.
The linker combines the host object code and the device code (SPIR-V or device binary) into an executable containing the host binary with the device code embedded in it. This process is known as a fat binary.
At runtime, the operating system starts the host application. If it has offload, the runtime loads the device code (converting the SPIR-V to device binary if needed).
The application runs on the host and a specified device.
JIT Compilation Flow
In the JIT compilation flow, the code for the device is translated to SPIR-V intermediate code by the back-end, embedded in the fat binary as SPRI-V, and translated from SPIR-V to device code by the runtime. When the application is run, the runtime determines the available devices and generates the code specific to that device. This allows for more flexibility in where the application runs and how it performs than the AOT flow, which must specify a device at compile time. However, performance may be worse because compilation occurs when the application runs. Larger applications with significant amounts of device code may notice performance impacts.
TIP:
The JIT compilation flow is useful when you do not know what the target device will be.
NOTE:
JIT compilation is not supported for FPGA devices.
The compilation phases are shown in the following diagram:
JIT compilation phases
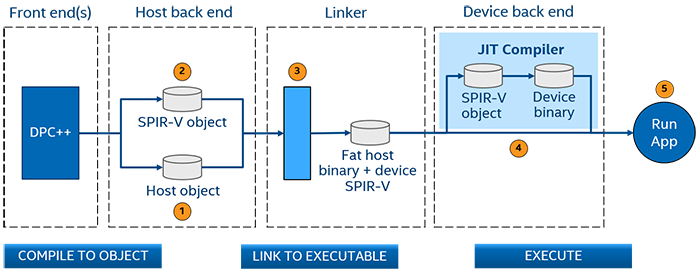
The host code is translated to object code by the back end.
The device code is translated to SPIR-V.
The linker combines the host object code and the device SPIR-V into a fat binary containing host executable code with SPIR-V device code embedded in it.
At runtime:
The device runtime on the host translates the SPIR-V for the device into device binary code.
The device code is loaded onto the device.
The application runs on the host and device available at runtime.
AOT Compilation Flow
In the AOT compilation flow, the code for the device is translated to SPIR-V and then device code in the host back-end and the resulting device code is embedded in the generated fat binary. The AOT flow provides less flexibility than the JIT flow because the target device must be specified at compilation time. However, executable start-up time is faster than the JIT flow.
TIP:
- The AOT compilation flow is good when you know exactly which device you are targeting.
The AOT flow is recommended when debugging your application as it speeds up the debugging cycle.
The compilation phases are shown in the following diagram:
AOT compilation phases
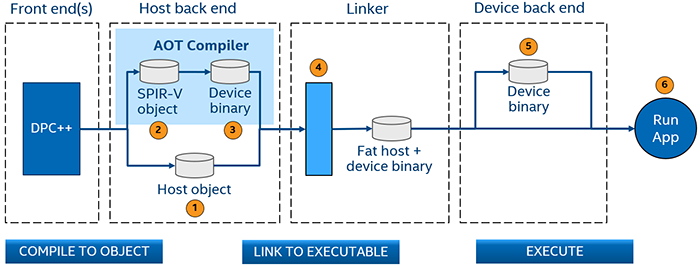
The host code is translated to object code by the back end.
The device code is translated to SPIR-V.
The SPIR-V for the device is translated to a device code object using the device specified by the user on the command line.
The linker combines the host object code and the device object code into a fat binary containing host executable code with device executable code embedded in it.
At runtime, the device executable code is loaded onto the device.
The application runs on a host and specified device.
Fat Binary
A fat binary is generated from the JIT and AOT compilation flows. It is a host binary that includes embedded device code. The contents of the device code vary based on the compilation flow.
FAT binary

The host code is an executable in either the ELF (Linux) or PE (Windows) format.
The device code is a SPIR-V for the JIT flow or an executable for the AOT flow. Executables are in one of the following formats:
CPU: ELF (Linux), PE (Windows)
GPU: ELF (Windows, Linux)
FPGA: ELF (Linux), PE (Windows)