Visible to Intel only — GUID: GUID-5F834CD8-7D73-4F44-BD7B-0D6FB8D27828
SYCL* Execution and Memory Hierarchy
Execution Hierarchy
The SYCL* execution model exposes an abstract view of GPU execution. The SYCL execution hierarchy consists of a 1-, 2-, or 3-dimensional grid of work-items. These work-items are grouped into equal sized groups called work-groups. Work-items in a work-group are further divided into equal sized groups called sub-groups.

To learn more about how this hierarchy works with a GPUor a CPU with Intel® UHD Graphics, see SYCL* Mapping and GPU Occupancy in the oneAPI GPU Optimization Guide.
Optimizing Memory Access
Using Intel® VTune Profiler, you can identify memory bottlenecks that are hindering performance. For more information, see the Memory Allocation APIs section of the Intel VTune User Guide.
Once the problem areas are identified, utilize the tools described in the Intel® oneAPI GPU Optimization Guide to learn how work-items in a kernel can synchronize to exchange data, update data, or cooperate with each other to accomplish a task. For more information, see these sections in the GPU Optimization Guide:
Memory Hierarchy
The General Purpose GPU (GPGPU) compute model consists of a host connected to one or more compute devices. Each compute device consists of many GPU Compute Engines (CE), also known as Execution Units (EU) or Xe Vector Engines (XVE). The compute devices may also include caches, shared local memory (SLM), high-bandwidth memory (HBM), and so on, as shown in the figure below. Applications are then built as a combination of host software (per the host framework) and kernels submitted by the host to run on the VEs with a predefined decoupling point.
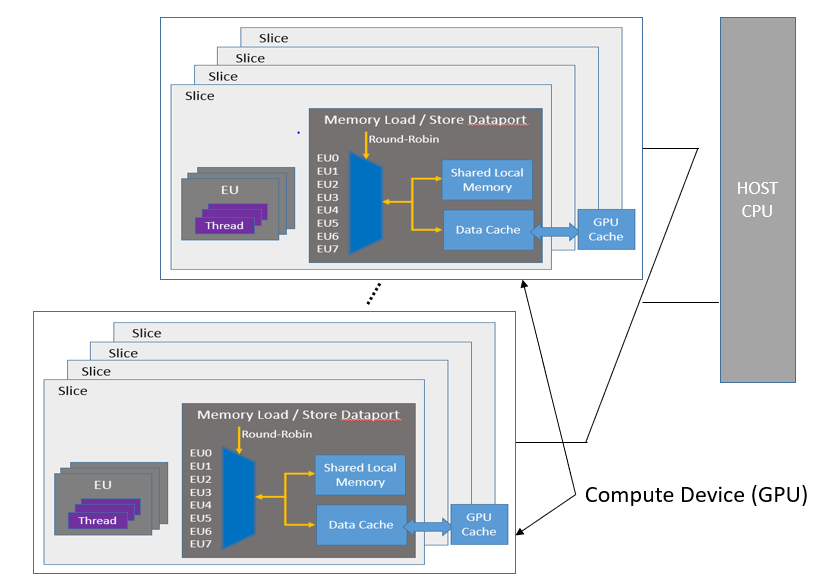
To learn more about memory hierarchy within the General Purpose GPU (GPGPU) compute model, see Execution Model Overview in the oneAPI GPU Optimization Guide.
Using Data Prefetching to Reduce Memory Latency in GPUs
Utilizing data prefetching can reduce the amount of write backs, reduce latency, and improve performance in Intel® GPUs.
To learn more about how prefetching works with oneAPI, see Prefetching in the oneAPI GPU Optimization Guide.