Visible to Intel only — GUID: GUID-A1C8223C-B78D-4CE2-8275-F7BADFBC47EA
CPU Offload Flow
By default, if you are offloading to a CPU device, it goes through an OpenCL™ runtime, which also uses Intel oneAPI Threading Building Blocks for parallelism.
When offloading to a CPU, workgroups map to different logical cores and these workgroups can execute in parallel. Each work-item in the workgroup can map to a CPU SIMD lane. Work-items (sub-groups) execute together in a SIMD fashion.
CPU workgroups
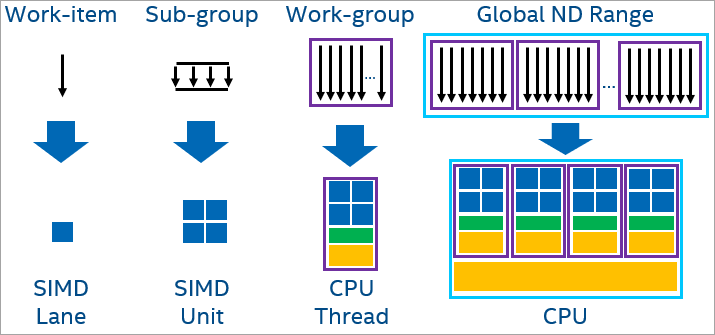
To learn more about CPU execution, see Compare Benefits of CPUs, GPUs, and FPGAs for Different oneAPI Compute Workloads.
Set Up for CPU Offload
Make sure you have followed all steps in the oneAPI Development Environment Setup section, including running the setvars or oneapi-vars script.
Check if you have the required OpenCL runtime associated with the CPU using the sycl-ls command. For example:
$sycl-ls CPU : OpenCL 2.1 (Build 0)[ 2020.11.12.0.14_160000 ] GPU : OpenCL 3.0 NEO [ 21.33.20678 ] GPU : 1.1[ 1.2.20939 ]Use one of the following code samples to verify that your code is running on the CPU. The code sample adds scalar to large vectors of integers and verifies the results.
SYCL*
To run on a CPU, SYCL provides built-in device selectors for convenience. They use device_selector as a base class. cpu_selector selects a CPU device.
Alternatively, you could also use the following environment variable when using default_selector to select a device according to implementation-defined heuristics.
export ONEAPI_DEVICE_SELECTOR=cpu
SYCL code sample:
#include <CL/sycl.hpp> #include#include <iostream> using namespace sycl; using namespace std; constexpr size_t array_size = 10000; int main(){ constexpr int value = 100000; try{ cpu_selector d_selector; queue q(d_selector); int *sequential = malloc_shared<int>(array_size, q); int *parallel = malloc_shared<int>(array_size, q); //Sequential iota for (size_t i = 0; i < array_size; i++) sequential[i] = value + i; //Parallel iota in SYCL auto e = q.parallel_for(range{array_size}, [=](auto i) { parallel[i] = value + i; }); e.wait(); // Verify two results are equal. for (size_t i = 0; i < array_size; i++) { if (parallel[i] != sequential[i]) { cout << "Failed on device.\n"; return -1; } } free(sequential, q); free(parallel, q); }catch (std::exception const &e) { cout << "An exception is caught while computing on device.\n"; terminate(); } cout << "Successfully completed on device.\n"; return 0; }
To compile the code sample, use:
dpcpp simple-iota-dp.cpp -o simple-iota.
Additional commands are available from Example CPU Commands.
Results after compilation:
./simple-iota Running on device: Intel® Core™ i7-8700 CPU @ 3.20GHz Successfully completed on device.
OpenMP*
OpenMP code sample:
#include<iostream> #include<omp.h> #define N 1024 int main(){ float *a = (float *)malloc(sizeof(float)*N); for(int i = 0; i < N; i++) a[i] = i; #pragma omp target teams distribute parallel for simd map(tofrom: a[:N]) for(int i = 0; i < 1024; i++) a[i]++; std::cout << "Successfully completed on device.\n"; return 0; }
To compile the code sample, use:
icpx simple-ompoffload.cpp -fiopenmp -fopenmp-targets=spir64 -o simple-ompoffload
Setup the following environment variables before executing the binary to run the offload regions on the CPU:
export LIBOMPTARGET_DEVICETYPE=cpu export LIBOMPTARGET_PLUGIN=opencl
Results after execution:
./simple-ompoffload Successfully completed on device
Offload Code to CPU
When offloading your application, it is important to identify the bottlenecks and which code will benefit from offloading. If you have a code that is compute intensive or a highly data parallel kernel, offloading your code would be something to look into.
To find opportunities to offload your code, use the Intel Advisor for Offload Modeling.
Debug Offloaded Code
The following list has some basic debugging tips for offloaded code.
Check host target to verify the correctness of your code.
Use printf to debug your application. Both SYCL and OpenMP offload support printf in kernel code.
Use environment variables to control verbose log information.
For SYCL, the following debug environment variables are recommended. A full list of environment variables is available from GitHub.
SYCL Recommended Debug Environment Variables Name
Value
Description
ONEAPI_DEVICE_SELECTOR
backend:device_type:device_num
SYCL_PI_TRACE
1|2|-1
1: print out the basic trace log of the SYCL/DPC++ runtime plugin
2: print out all API traces of SYCL/DPC++ runtime plugin
-1: all of “2” including more debug messages
For OpenMP, the following debug environment variables are recommended. A full list is available from the LLVM/OpenMP documentation.
OpenMP Recommended Debug Environment Variables Name
Value
Description
LIBOMPTARGET_DEVICETYPE
cpu|gpu|host
Select
LIBOMPTARGET_DEBUG
1
Print out verbose debug information
LIBOMPTARGET_INFO
Allows the user to request different types of runtime information from libomptarget
Use Ahead of Time (AOT) to move Just-in-Time (JIT) compilations to AOT compilation issues. For more information, see Ahead-of-Time Compilation for CPU Architectures.
See Debugging the SYCL and OpenMP Offload Process for more information on debug techniques and debugging tools available with oneAPI.
Optimize CPU Code
There are many factors that can affect the performance of CPU offload code. The number of work-items, workgroups, and amount of work done depends on the number of cores in your CPU.
If the amount of work being done by the core is not compute-intensive, then this could hurt performance. This is because of the scheduling overhead and thread context switching.
On a CPU, there is no need for data transfer through PCIe, resulting in lower latency because the offload region does not have to wait long for the data.
Based on the nature of your application, thread affinity could affect the performance on CPU. For details, see Control Binary Execution on Multiple Cores.
Offloaded code uses JIT compilation by default. Use AOT compilation (offline compilation) instead. With offline compilation, you could target your code to specific CPU architecture. Refer to Optimization Flags for CPU Architectures for details.
Additional recommendations are available from Optimize Offload Performance.