A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-1AC7FF16-436A-4E49-BDBC-E29F840EF587
Visible to Intel only — GUID: GUID-1AC7FF16-436A-4E49-BDBC-E29F840EF587
Boost Matrix Multiplication Performance with Intel® Xe Matrix Extensions
The increasing popularity of Artificial Intelligence (AI) in today’s world demands the introduction of low precision data types and hardware support for these data types to boost application performance. Low precision models are faster in computation and have smaller memory footprints. For the same reason low precision data types are getting highly used for both training and inference in AI / machine learning (ML) even though float32 is the default data type. To optimize and support these low precision data types, special hardware features and instructions are required. Intel provides those in the form of Intel® Xe Matrix Extensions (Intel® XMX) in its GPUs. Some of the most used 16-bit formats and 8-bit formats are float16 (fp16), bfloat16 (bf16), 16-bit integer (int16), 8-bit integer (int8) etc. The figure below visualizes the differences between some of these formats.
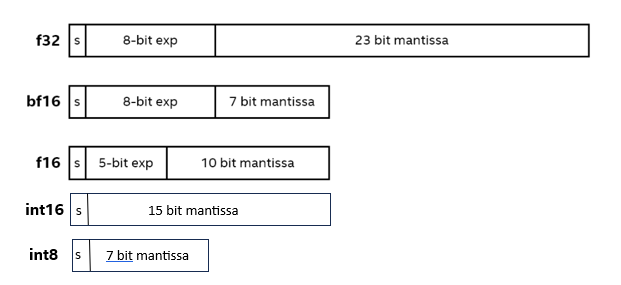
In the above figure, s is the signed bit(the first digit of the binary presentation, 0 implies positive number and 1 implies negative number) and exp is the exponent.
Intel® Xe Matrix Extensions
Intel® Xe Matrix Extensions (Intel® XMX) specializes in executing Dot Product Accumulate Systolic (DPAS) instructions on 2D systolic arrays. A systolic array in parallel computer architecture is a homogeneous network of tightly coupled data processing units. Each unit computes a partial result as a function of data received from its upstream neighbors, stores the result within itself and passes it downstream. Intel® XMX supports numerous data types, depending on hardware generation, such as int8, fp16, bf16, and tf32. To understand Intel® XMX inside Intel® Data Center GPU Max Series, please refer to Intel® Intel® Iris® Xe GPU Architecture section.
Programming Intel® XMX
Users can interact with XMX at many different levels: from deep learning frameworks, dedicated libraries, custom SYCL kernels, down to low-level intrinsics. Programming and running applications using Intel® XMX requires Intel® oneAPI Base Toolkit.
Using Intel® oneAPI Deep Neural Network Library (oneDNN)
To take the maximum advantage of the hardware, oneDNN has enabled Intel® XMX support on Intel GPUs (Intel® Xe 4th Generation Scalable processors and later) by default. To uses the data types supported by XMX and oneDNN, the applications needs to be built with GPU support enabled.
The Matrix Multiplication Performance bundled with oneDNN is a good example to learn how to use oneDNN to program Intel® XMX.
Using Intel® oneAPI Math Kernel Library (oneMKL)
Like oneDNN, oneMKL also enables Intel® XMX by default if we use the supported data types and the code is compiled using the Intel® oneAPI DPC++ Compiler.
oneMKL supports several algorithms for accelerating single-precision gemm and gemm_batch using XMX. The bf16x2 and bf16x3 are 2 such algorithms using bf16 to approximate single-precision gemm.
Internally single-precision input data is converted into bf16 and multiplied with the systolic array. The three variants – bf16, bf16x2, and bf16x3 – allow you to make a tradeoff between accuracy and performance, with bf16 being the fastest and bf16x3 the most accurate (similar to the accuracy of standard single-precision gemm). The example Matrix Multiplication shows how to use these algorithms and the table below compares the performance difference.
Precision |
Data type/ Algorithm |
Peak (TF) |
Performance relative totheoretical peak ofsingle precision(%) |
|---|---|---|---|
Single |
fp32 |
26 |
98 |
Single |
bf16 |
151 |
577 |
Single |
bf16x2 |
74 |
280 |
Single |
bf16x3 |
42 |
161 |
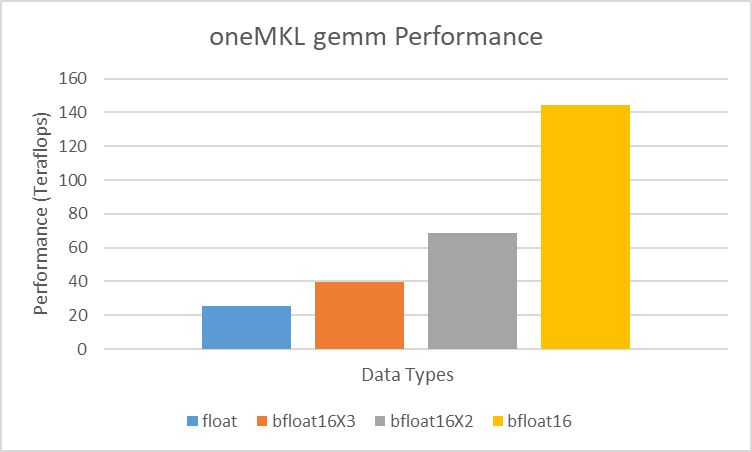
The test is performed on a Intel® Xeon® 8480+ with512 GB DDR5-4800 + Intel® Data Center GPU Max 1550 running Ubuntu 22.04.
This table shows the Performance of bf16, bf16x2 and bf16x3 far outweigh the theoretical peak of single precision. If the accuracy tradeoff is acceptable, bf16, followed by bf16x2 and then bf16x3, is highly recommended.