Enhance Your AI Skills
Supercharge your generative AI (GenAI) solutions with LLM fine-tuning and inference. At the end of this article, make sure to review our resource collection.
Overview
LLMs are at the core of GenAI, enabling us to build powerful, innovative applications. However, like any advanced technology, unlocking their full potential comes with its own set of challenges. Fine-tuning and deploying these models for inference can be complex. This article gives you five tips to guide you through these hurdles.
Preprocess Your Data Thoroughly
Effective data preprocessing is foundational for model performance. Ensuring your dataset is clean and well-labeled can significantly enhance training outcomes. Challenges include noisy data, imbalanced classes, proper task-specific formatting, and nonstandard datatypes.
Expert Tips
- Determine if you will be performing instruction, chat, or open-ended text generation training and fine-tuning, as this will dictate the columns and format of your dataset.
- Augment your data by generating synthetic data from a significantly larger LLM. For example, use a 70B parameter model to generate data for fine-tuning a smaller 1B parameter model.
- You've heard it before: garbage in/garbage out. This is still true for language models, and it can have significant impacts on the hallucination and quality of your models. Try manually evaluating 10% of your data at random.
Fine-Tune Hyperparameters Systematically
Hyperparameter tuning is crucial for achieving optimal performance. This involves selecting the right learning rate, batch size, and number of epochs, which can be daunting due to the vast search space. Automating this with LLMs is challenging and typically requires access to two or more accelerators to optimize.
Expert Tips
- Use grid search or random search methods to explore the hyperparameter space.
- For unique LLM tasks, build a custom benchmark based on your dataset by synthetically or manually creating a smaller subset of data. Alternatively, use standard benchmarks from language modeling harnesses like the EleutherAI Language Model Evaluation Harness.
- Monitor training metrics closely to avoid overfitting or underfitting. Check for situations where your training loss continues to decrease while validation loss increases—this is a clear sign of overfitting.
Use Advanced Techniques
Advanced techniques like mixed precision, distributed training, and parameter-efficient fine-tuning (PEFT) can significantly reduce training time and memory. These techniques are well accepted and implemented by production and research teams developing GenAI applications.
Expert Tips
- Regularly validate your model's performance to maintain accuracy across mixed and non-mixed precision model training runs.
- Use libraries that support mixed precision natively to simplify implementation. Most notably, PyTorch* supports automatic mixed precision with very few changes to the training code.
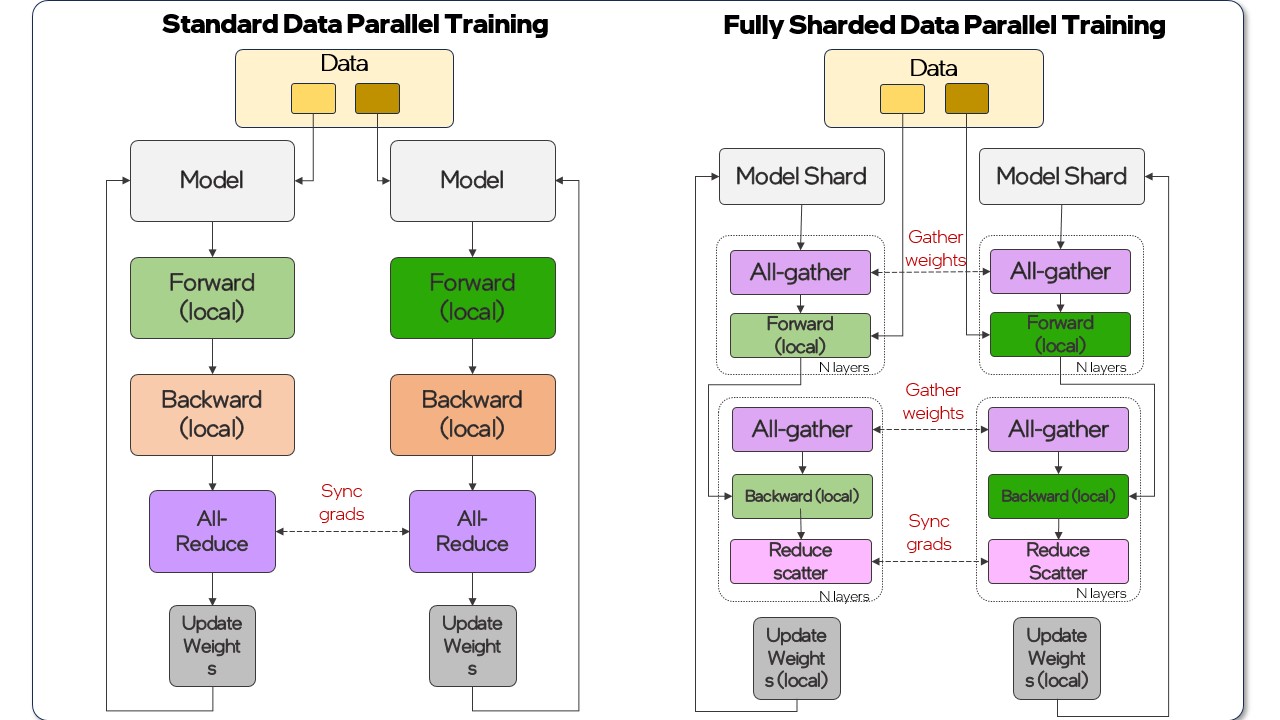
- Model sharding is more advanced and resource-efficient than traditional data parallel distributed methods. It splits up the model and the data across multiple processors. Popular software options include PyTorch Fully Sharded Data Parallel (FSDP) and Microsoft DeepSpeed* ZeRO.
- Using PEFT techniques like low-rank adaptations (LoRA) allows you to create "mini-models" or adapters for various domains and tasks. LoRA also reduces the total trainable parameters, thereby decreasing the memory and compute complexity of the fine-tuning process. Deploying these adapters efficiently lets you support many use cases without needing multiple large model files.
Optimize for Inference Speed
Deploying LLMs efficiently requires minimizing inference latency, which is challenging due to their large size and complexity. This aspect of AI most closely impacts user experience and system latency.
Expert Tips
- Use model compression techniques like low-bit quantization to compress models to 16-bit and 8-bit representations.
- Regularly validate your model's performance to ensure accuracy is maintained as you test lower precisions quantization recipes.
- Use pruning techniques to eliminate redundant weights, reducing the computational load.
- Consider model distillation to create a smaller, faster model that approximates the original.
Scale Deployment with Robust Infrastructure
Deploying LLMs at scale presents challenges such as load balancing, fault tolerance, and maintaining low latency. Effective infrastructure setup is key.
Expert Tips
- Use Docker* software to create consistent deployments of LLM inference environments. This makes it easier to manage dependencies and configurations across different deployment stages.
- Use container management technologies like Kubernetes* or AI and machine learning tools like Ray to orchestrate multiple instances of models deployed across a data center cluster.
- Employ autoscaling to handle varying loads and maintain performance under peak traffic when language models receive abnormally high or low request volumes. This can help save costs and ensure the deployment correctly supports the application's business requirements.
Fine-tuning and deploying LLMs might seem like a daunting task, but with the right strategies, you can overcome any challenge that comes your way. The tips and tricks outlined above can go a long way to overcoming common pitfalls.
Resource Library
In this section, we provide expertly authored and curated content on LLM fine-tuning and inference for aspiring and current AI developers. We cover techniques and tools like LoRA fine-tuning of Llama* 7B, distributed training, Hugging Face* for the Optimum for Intel Gaudi library, and more.
What you'll learn:
- Implement LoRA PEFT of state-of-the-art models.
- Identify opportunities to use Hugging Face tools to train and perform inference with LLMs.
- Recognize opportunities to use distributed training techniques like PyTorch FSDP to accelerate model training.
- Configure an Intel® Gaudi® processor node on the Intel® Tiber™ Developer Cloud.
Get Started
Step 1: Watch the video on using Hugging Face on Intel Tiber Developer Cloud.
Step 2: Read up on the technology and run the code.
Senior AI solutions engineer Eduardo Alvarez shares this comprehensive guide to efficiently fine-tune Llama 2 using LoRA on Intel Gaudi 2 processors. The guide covers how to set up the development environment and details steps to fine-tune and perform inference—all aimed at reducing costs and speeding up the optimization of LLMs. Then go to the Intel Tiber Developer Cloud, where you'll be able to use the free Jupyter* servers for Intel Gaudi 2 processors to fine-tune your LLM.
Step 3: Learn about advanced fine-tuning techniques with PyTorch FSDP on Intel Gaudi accelerators.
Discover how to implement scalable model development using FSDP training with PyTorch on Intel Gaudi accelerators. This course emphasizes Intel Gaudi software support and optimizations for major frameworks, which provides developers with robust tools to develop GenAI models at scale.
Step 4: Learn more about how models perform on Intel Gaudi accelerators.
Get detailed performance data for Intel Gaudi AI accelerators, including latency, throughput, and time-to-train metrics for top models like Llama, Mistral AI*, and Falcon. This data is an essential resource for planning resource allocation and deployment, helping developers optimize their AI workloads.
Additional Resources
Intel Gaudi Al Accelerators
PyTorch Optimizations from Intel
Developer Resources from Intel and Hugging Face
Sign Up for Intel Tiber Developer Cloud