The Intel® oneAPI Math Kernel Library (oneMKL) binary distribution is the fastest and most-used math library for Intel®-based systems1, just as the binary distribution only math libraries included in the CUDA* Toolkit are the most used set of libraries for NVIDIA* GPUs.
The oneAPI Math Kernel Library (oneMKL) Interfaces and its SYCL* API, on the other hand, are defined by the oneAPI Specification for oneMKL, oneAPI being an open, cross-industry, standards-based, unified, multiarchitecture, multi-vendor programming model.
Thus, the oneAPI Math Kernel Library (oneMKL) Interfaces project is an open source specification implementation. The project illustrates how the SYCL interfaces documented in the oneMKL specification can be implemented for any math library and work for any target hardware. While the implementation provided may not yet be the full implementation of the specification, the goal is to build it out over time.
This allows oneMKL to share in the vision of oneAPI and provide freedom of choice for targeted hardware platform configurations. Using a common codebase for different accelerated compute platforms through source code portability and performance portability.
It is not sufficient to simply translate CUDA calling conventions into SYCL. Commonly used libraries and their APIs also need to be matched and migrated. To ease the migration of an existing codebase from CUDA to SYCL so that it can run on not only NVIDIA GPUs but a wide range of possible GPUs and accelerators, functionality and capabilities need to be mapped and well-understood for CUDA-based as well as SYCL-based library implementations.
This article will provide a snapshot highlighting the overlap in the current random number generation library function implementations of cuRAND* and oneMKL.
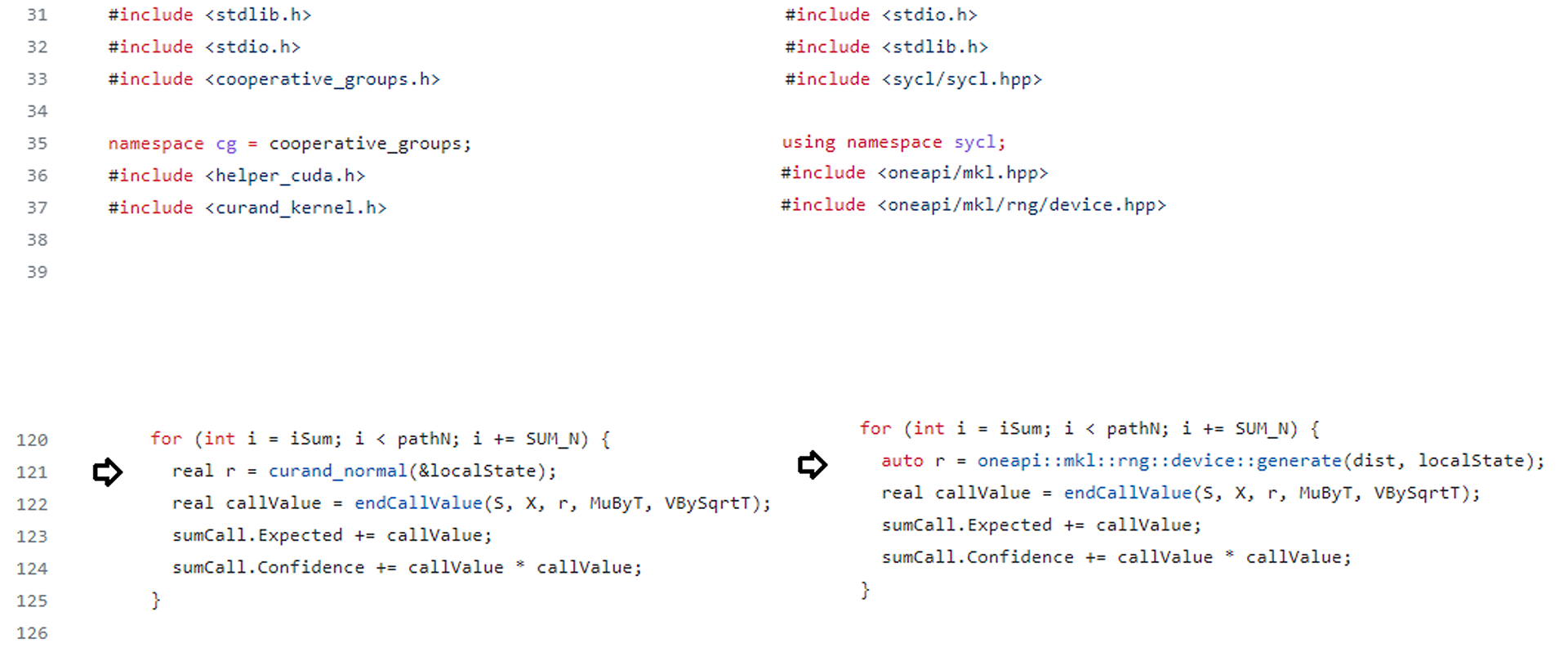
Figure 1. Assigning Sets of Random Numbers using cuRAND and oneMKL Device API
The code comparison in Figure 1 shows the differences in the header files required and the use of curand_normal() versus generate() for assigning a random number in a loop.
Similar function call mapping will have to be used across the board. Here, we will not go into the details of the calling conventions but only provide a brief summary for context.
Detailed documentation can be found at these locations:
- oneMKL - SYCL Developer Reference – Random Number Generators
- API reference guide for cuRAND, the CUDA random number generation library
Let us consider a simple, complete, and reusable code sample for random number generation using Host API as well as Device API implemented in CUDA and oneMKL, providing us with a good overview of the similarities and differences in the usage model:
| oneMKL | cuRAND |
|---|---|
Figure 2. Side-by-side code comparison using Host API
| oneMKL | cuRAND |
|---|---|
Figure 3. Side-by-side code comparison using Device API
oneMKL RNG SYCL API for Host and Target
oneMKL provides SYCL interfaces for the Vector Statistics Random Number Generators (RNG) routines implementing commonly used pseudorandom, quasi-random, and non-deterministic generators with continuous and discrete distributions. oneMKs RNG SYCL API follows the C++ standard, an additional advantage for C++ users.
The SYCL API consists of a host-side and device-side API. In addition, there are two APIs for storing data on a device and sharing data between devices and the host: the buffer API and the unified shared memory (USM) API.
Most of oneMKL RNG functions can be executed on a CPU or a GPU, often using the same device API.
The device-side communication is handled via a oneAPI compliant backend runtime library for the targeted device, which could be a CPU or a GPU from vendors like Intel, AMD, or NVIDIA. The compute device could even be other compute accelerators that such a runtime library had been developed for using OpenCL or oneAPI Level Zero backend framework.
RNG API calls support explicit manual offload (Host API) as well as the ability to call a set of functions directly from SYCL kernels (Device API) with Random Number Generators Device Routines.
The oneMKL RNG device API represents generators as classes, which may be called directly in the kernel or allocated on the host.
A typical sequence of operations using Host API looks as follows:
- Create and initialize the object for a basic random number generator.
- Create and initialize the object for the distribution generator.
- Call the generate() routine to get random numbers with the appropriate statistical distribution.
- Cleanup is handled automatically by the RNG object’s destructor.
The example in Figure 2 and Figure 3 demonstrates the generation of random numbers by the basic generator (engine) PHILOX4X32X10. The seed is equal to 777. The generator is used to generate 4096 normally distributed random numbers with default parameters a = 0 and sigma= 1. The purpose of examples is to calculate the sample mean for normal distribution with the given parameters.
cuRAND API for Host and Target
Although cuRAND’s focus is on NVIDIA’s GPUs, there are a few software architectural similarities. It also has a library on the host (CPU) side and a device (GPU) header file. Random numbers can be generated on the device or the host CPU. It includes support for commonly used pseudorandom and quasi-random generators.
If random number generation happens on the GPU, the calls to the GPU are initiated from the host CPU, and the created random numbers are stored in global device memory. The resulting number can be reused on the GPU using CUDA kernels or copied back to the host memory for additional processing.
cuRAND represents different device API generators as pointers to a structure.
A typical sequence of operations looks as follows:
- Create a new generator of the desired type.
- Allocate memory on the device.
- Generate random numbers with curandGenerate().
- Clean up with curandDestroyGenerator().
For a detailed overview of the cuRAND usage model, please consult its online CUDA Toolkit Documentation.
Functional Coverage
The tables below provide a functional map of the current oneMKL RNG host API and device API to its CUDA equivalent and help you identify current gaps in respective coverage.
Development is ongoing. Thus, the data presented in these tables currently will change over time. Please check the oneMKL RNG SYCL API Implementation on GitHub frequently or ensure to always use the latest Intel oneAPI Math Kernel Library product release for your software development.
The columns show the cuRAND API name (if available) followed by the equivalent oneMKL construct. The “not supported” entry indicates that cuRAND and oneMKL, respectively, don’t support a specific functionality.
Both tables cover RNG generators and distributions.
NOTE: All oneMKL APIs in tables 5 and 6 support CPU and GPU both, except the following generators that support only CPU: ars5, niederreiter, wichman_hill, sfmt19937, r250 and nondeterministic.
RNG Host API Functionality Map
The following table, namespace oneapi::mkl::rng is used for oneMKL RNG Host API.
|
cuRAND API support |
oneMKL API support |
|---|---|
|
Generators |
|
|
CURAND_RNG_PSEUDO_DEFAULT |
philox4x32x10 |
|
CURAND_RNG_PSEUDO_XORWOW |
not supported |
|
CURAND_RNG_PSEUDO_MRG32K3A |
mrg32k3a |
|
CURAND_RNG_PSEUDO_MTGP32 |
Intel oneMKL provides mt2203 counterpart |
|
CURAND_RNG_PSEUDO_MT19937 |
mt19937 |
|
CURAND_RNG_PSEUDO_PHILOX4_32_10 |
philox4x32x10 |
|
CURAND_RNG_QUASI_SOBOL32 |
sobol |
|
CURAND_RNG_QUASI_SCRAMBLED_SOBOL32 |
can be supported by sobol |
|
CURAND_RNG_QUASI_SOBOL64 |
not supported |
|
CURAND_RNG_QUASI_SCRAMBLED_SOBOL64 |
not supported |
|
not supported |
ars5 |
|
not supported |
mcg59 |
|
not supported |
niederreiter |
|
not supported |
mcg31m1 |
|
not supported |
wichmann_hill |
|
not supported |
sfmt19937 |
|
not supported |
r250 |
|
not supported |
nondeterministic |
|
Distributions |
|
|
curandGenerate |
generate(uniform_bits<>{}, …); |
|
curandGenerateLogNormal curandGenerateLogNormalDouble |
generate(lognormal<>{}, …); |
|
curandGenerateNormal curandGenerateNormalDouble |
generate(gaussian<>{}, …); |
|
curandGeneratePoisson |
generate(poisson<>{}, …); |
|
curandGenerateUniform |
generate(uniform<>{}, …); |
|
not supported |
bits |
|
not supported |
bernoulli |
|
not supported |
beta |
|
not supported |
binomial |
|
not supported |
chi_square |
|
not supported |
exponential |
|
not supported |
gamma |
|
not supported |
geometric |
|
not supported |
gumbel |
|
not supported |
hypergeometric |
|
not supported |
laplace |
|
not supported |
multinomial |
|
not supported |
negative_binomial |
Figure 4. Random Number Generation Host API Functionality Map
RNG Device API Functionality Map
In the following table namespace oneapi::mkl::rng::device is used for oneMKL RNG Device API.
|
cuRAND API support |
oneMKL API support |
|---|---|
|
Generators |
|
|
curandStateMtgp32_t |
not supported |
|
curandStateScrambledSobol64_t |
not supported |
|
curandStateSobol64_t |
not supported |
|
curandStateMRG32k3a_t |
mrg32k3a |
|
curandStatePhilox4_32_10_t |
philox4x32x10 |
|
__device__ void curand_init (unsigned long long seed, |
mrg32k3a<vec_size>(uint32_t seed, uint64_t offset) |
|
__device__ void curand_init (unsigned long long seed, |
philox4x32x10<vec_size>(uint64_t seed, uint64_t offset) |
|
QUALIFIERS_MTGP32 float curand_mtgp32_single |
not supported |
|
QUALIFIERS_MTGP32 unsigned int |
not supported |
|
__device__ unsigned int curand (generator_state_t* generator) |
uint32_t generate(bits<>& distr, generator& gen) |
|
__device__ uint4 curand4 (generator_state_t* generator) |
sycl::vec<uint32_t, 4> generate(bits<>{}, generator<4>& gen) |
|
Distributions |
|
|
__device__ float curand_normal
|
sycl::vec<float, vec_size> generate(gaussian<float>{}, generator<vec_size>); |
|
__device__ float curand_uniform
|
sycl::vec<float, vec_size> generate(uniform<float>{}, generator<vec_size>); |
|
__device__ float curand_log_normal(generator_state_t *state, float mean, float stddev)
|
sycl::vec<float, vec_size> generate(lognormal<float>(mean, stddev), generator<vec_size>); |
|
__device__ unsigned int curand_poisson |
sycl::vec<int32_t, vec_size> generate(poisson<int32_t>(lambda), generator<vec_size>); |
|
__device__ unsigned int |
not supported |
|
Not supported |
bits |
|
Not supported |
exponential |
Figure 5. Random Number Generation Device API Functionality Map
As you might expect, oneMKL RNG has considerably more extensive coverage using its host API and device API, whereas cuRAND offers slightly more coverage with its device API.
Portability Across Compute Devices
SYCLomatic and the Intel DPC++ Compatibility Tool will assist in automatically migrating cuRAND function calls into oneMKL RNG calls for increased code portability and flexibility in targeted offload compute accelerators. The migrated code can be run not only on Intel HW but also on NVIDIA GPUs using oneMKL Interfaces Github project.
Many implementations have a direct match between the two APIs, whether you use CUDA or SYCL.
Some, however, do currently not have this direct match in either direction. In some areas, oneMKL provides more functionality; in others, cuRAND does. We are actively working on increasing the functional overlap where feasible, prioritized by frequency of use in developers’ applications. This implies that functional portability and performance portability is easily accessible in most cases.
If there is a scenario where the oneMKL implementation details are not obvious, please contact our community forum or our Priority Support team of consulting engineers.
Join Us and Get Started with oneMKL RNG SYCL Interfaces
Become part of the effort to make high-performance cross-architecture compute transparent, portable, and flexible. Include SYCL as the accelerator and GPU offload solution in your code path. Adopt oneAPI as the means to implementations free from vendor lock.
You can install oneMKL as a part of the Intel® oneAPI Base Toolkit or download its stand-alone version, both for free!
Additional Resources
- oneMKL Landing Page
- oneMKL Documentation
- oneAPI Specification Documentation for oneMKL
- Intel® oneAPI Base Toolkit
- oneMKL Interfaces: GitHub Repository
- oneMKL Code Samples on GitHub
- How to Move from CUDA* Math Library Calls to oneMKL
- CUDA-to-SYCL Migration Tools: SYCLomatic and Intel® DPC++ Compatibility Tool