
Quantum chromodynamics (QCD) is the theory/study of strong force interaction between subatomic particles. Lattice QCD solves QCD problems by representing the particles and forces as a lattice discretized on space and time domains. HotQCD is a C++ hybrid MPI/OpenMP* lattice QCD simulation framework widely used by the high energy physics research community.
This article describes the performance tuning techniques applied to HotQCD to achieve optimal performance on the Intel® Xeon® CPU Max Series. The key differentiator of the Intel Xeon CPU Max Series over other Intel Xeon processors is the addition of high bandwidth memory (HBM) (Figure 1a). In simple terms, HBM is a 3D stacked DRAM interface that delivers higher memory bandwidth performance than DDR memory (single stack DRAM). The Intel Xeon CPU Max Series features up to 56 cores (per CPU socket) with HBM2e in the form of four stacks of eight high DRAM dies per socket, with each DRAM die in the stack having a capacity of 2 GB (4 x 8 x 2 = 64 GB HBM per socket).
Performance Analysis
Intel® processors with HBM have many configuration modes: memory (Flat, Cache, HBM-only) and NUMA (SNC1, SNC4). The details of each mode are beyond the scope of this article, but you can find more information in the Intel Xeon CPU Max Series Configuration and Tuning Guide. The system used for this article was configured in HBM-only memory mode (no DDR5) with SNC4 (Sub-NUMA Clustering-4) (Figure 1b).

Figure 1. (a) Intel® Xeon® CPU Max Series; (b) Intel Xeon CPU Max Series in HBM-only + SNC4 mode
The performance snapshot of HotQCD [benchmarked with a lattice size of 324 (x=y=z=t=32) with one RHS (right-hand side) vector] shows that the most time-consuming function (dslash, which consumes 90% of the total execution time) is memory bandwidth-bound (i.e., the processor was stalled ~50% of the time waiting for memory operations) (Figure 2).

Figure 2. Baseline performance snapshot from the Intel® VTune™ Profiler using microarchitecture exploration analysis
The OpenMP parallel region of dslash is shown in Figure 3. At each point in the lattice, a set of four dense matrix-vector products is performed through operator overloading. The function is fully vectorized with Intel® AVX-512 intrinsics with no synchronization among threads. Link_std has two matrix-vector products with each matrix and vector comprised of nine and three cache lines, making a total of 4 x 2 x (9 + 3) = 96 cache lines read. Link_naik is like link_std except that its matrix is populated by loading only seven cache lines, for a total of 4 x 2 x (7 + 3) = 80 cache lines read. All the memory accesses are cache line-aligned with a negligible amount of data reuse, which clearly shows that this function is memory bandwidth-bound (with a FLOP:byte ratio of ~0.9) with heavy read traffic [for every 176 (96 + 80) cache lines read, only three cache lines are written to memory]. In other words, the processor needs to continuously read data from memory to perform the floating-point calculations.

Figure 3. HotQCD dslash code
Memory Access Patterns
Figure 4 shows the operation sequence in the link_std block (lines 1517 and 1518) over the inner (each point in a 4-D lattice) and outer (lattice points) loops with the same color indicating a contiguous memory region and a different color indicating a large stride in memory (relative to the temporal memory access requests). Each matrix (nine cache lines, denoted CL) is loaded from contiguous memory with a constant stride of 1,172 elements across the outer loop. A stride of 1,172 FP32 elements (1,172 x 32 bytes = 4,688 bytes) leads to accessing a new 4 KB page at each outer loop iteration. The successive vectors loaded (in the inner loop) are separated by large strides as well. However, they form a contiguous address stream over the outer loop iteration space. When compared to the matrices, the vectors have better access pattern because there is no jumping across 4 KB pages. Finally, each matrix-vector product is fully unrolled with 27 AVX-512/ZMM registers. The matrix needs 3 x 3 x 2 (for the real and imaginary parts of the complex numbers) = 18 ZMM registers. The vector needs 3 x 1 x 2 = 6 ZMM registers plus three ZMM for accumulation of results across the inner loop.

Figure 4. Dslash memory access patterns
Software Prefetching
Intel processors have various hardware prefetchers (L1$, L2$) capable of detecting both streaming and striding access patterns (see the Intel 64 and IA-32 Architectures Optimization Reference Manual for more details), but they all prefetch within a 4 KB page boundary and do not fetch data across pages. Because the matrices in HotQCD are accessed in strides that cross the page boundary, the effectiveness hardware prefetching is reduced. This is further compounded by the fact that there are multiple strided access streams in the loop body, which can further stress the hardware prefetcher. This led us to investigate the performance impact of using explicit software prefetching to mitigate the effects of large access strides. In other words, we aim to enhance the effectiveness of hardware prefetchers by issuing prefetch instructions (available in the x86 ISA) to preemptively fetch the data from memory before being consumed in corresponding computation operations (Figure 5).

Figure 5. Dslash with software prefetching
The effectiveness of software prefetching is mainly driven by two factors:
- Prefetch distance: The ideal prefetch distance is determined by factors such as the size of working set, the latency of instructions in the loop body, and the location of data (memory/cache) that is being fetched. Prefetching too far ahead can cause the prefetched data to be evicted from caches by the intermediate iteration working sets, whereas prefetching too near would not hide the latency of memory hierarchy. In either case, it reduces the usefulness of software prefetching and can even degrade performance because of the additional memory access requests generated by the prefetch instructions, which is an additional burden on the already saturated memory pipeline queues.
- Cache hierarchy: This controls the cache level to which the requested data is to be placed. x86 ISA has prefetch instructions that can place data in L1, L2, and last level cache with additional control available to minimize cache pollution at lower level for non-temporal accesses. In some applications, it would be beneficial to have a multilevel prefetching mechanism as well, wherein a larger prefetch distance is used to prefetch data from memory to L2 cache, and a shorter distance for prefetching from L2 to L1 cache.
There are two primary mechanisms to use software prefetching in applications: Intel® compiler flags or prefetch intrinsic functions. We chose the latter because it gives us finer control. Figure 6 shows the speedup from software prefetching + hardware prefetchers over the baseline performance (using only hardware prefetchers) with different distance and cache hierarchy. We get 1.13x speedup by prefetching data from 10 iterations ahead (site) to L2 cache.

Figure 6. Performance improvement from software prefetching
Memory Layout
In HotQCD, the key operation is to calculate the inverse of a large matrix using the indirect, iterative conjugate gradient (CG) method to solve the linear system. The CG takes approximately 2,000 iterations to converge. Each CG iteration computes the updated vector by computing four matrix-vector products (discussed previously) followed by halo exchange among MPI ranks. Across the CG iterations, the matrices remain unmodified with only the vectors getting updated. We can take advantage of this pattern wherein the first CG iteration copies the matrices to a more performant non-strided/packet format. In the subsequent iterations, we load the matrices from the packed buffer (Figures 7 and 8).

Figure 7. Dslash packed matrix layout

Figure 8. Matrix packed layout code
By having a contiguous matrix memory layout, we avoid strided accesses across both inner and outer loops. This is especially beneficial because the hardware prefetcher is heavily stressed by striding >4 KB in the native matrix layout (baseline). The CG takes ~2,000 iterations, so the copy cost in the first iteration is amortized. Because we need to copy the matrix in native layout to a packed buffer, we need to allocate extra memory (1 GB for the tested problem size). This, however, is not a limiting factor because the total runtime memory footprint of HotQCD is well within the HBM capacity of 64 GB per socket.
Figure 9 shows the VTune™ Profiler snapshot comparison of baseline against packed memory layout. The packed memory layout shows lower cycles per instructions (CPIs) (0.4 vs 1.4) and fewer execution slots stalled on memory requests (28% vs 44%).
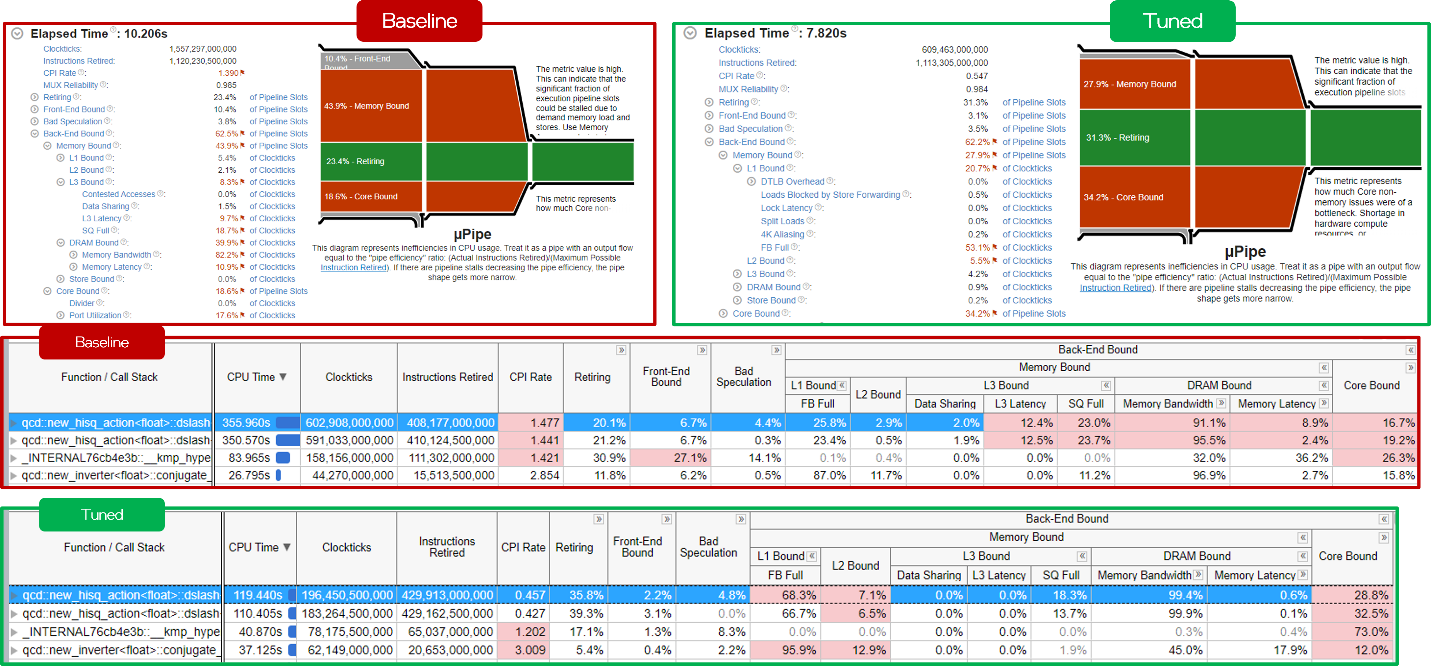
Figure 9. VTune™ Profiler comparison between the baseline and packed layout
Overall, by employing packed memory layout, the performance of HotQCD improves by 1.38x over baseline (Figure 10). The dslash kernel gets a boost of 1.54x, but it does not fully translate to the full benchmark gains as the packed layout causes cache pollution and slows down the subsequent vector operations that follow dslash. The optimizations are applicable to Intel Xeon systems without HBM as well, with observed performance gains of 1.21x over baseline (Figure 11).

Figure 10. HotQCD relative performance speedup on the Intel® Xeon® CPU Max Series
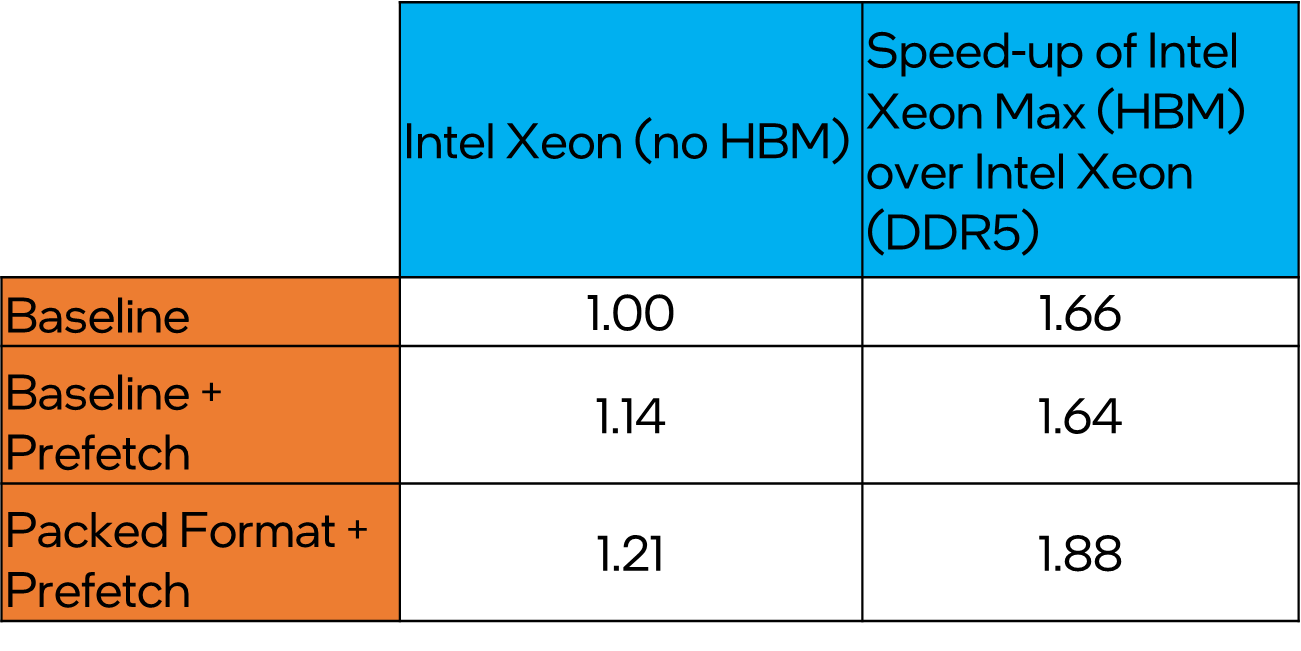
Figure 11. HotQCD performance on the Intel® Xeon® processor and the Intel® Xeon® CPU Max Series
Conclusions
We conclude with the following key takeaways:
- The Intel Xeon CPU Max Series featuring HBM delivers significant performance boosts over their DDR5 counterparts: 1.66x to 1.88x.
- Prefetching can further boost HBM performance: 1.13x over HBM baseline.
- It’s imperative to understand application memory access patterns to fully tune prefetch performance. While prefetch instructions are cheap, use them with care.
- Large memory access strides that cross the 4 KB page boundary are not ideal for HBM performance. As demonstrated, prefer to read contiguous chunks of memory over strided accesses. This delivers optimal HBM performance: 1.38x to 1.54x over baseline.