
The Need for More Flexible Parallel Compute Power
The Basel Committee on Banking Supervision* (BCBS) forecasts a four- to twentyfold increase in compute demand due to the increasing need for financial risk mitigation measures. These include advanced market prediction algorithms and risk simulations to better understand asset volatility associated with climate change, supply chain disruption, and geopolitical changes.
Software developers in the banking and financial services industry (FSI) rely on high-performance computing (HPC) environments with GPU-based acceleration to implement these risk simulation models. The challenge they face is that the wide deployment of these workloads makes it paramount that they can be run on a large variety of hardware platform configurations. Before the Unified Acceleration (UXL) Foundation’s efforts and the ever-increasing popularity of SYCL*, they faced substantial obstacles and inefficiencies caused by the need to port and refactor code every time a workload had to be deployed in a new environment.
The Monte Carlo method is a well-known method in finance, relying on highly performant random number generation as seeds for its simulation scenarios. It is used for option pricing, as the expected return on investment (ROI) is often too complex to compute directly, especially with exotic options. American and European option models are two widely used Monte Carlo simulation methods to predict the probability of various option investment outcomes.
Since the introduction of the C++ with SYCL-based oneAPI Math Kernel Library (oneMKL) Interfaces in 2020, this component of the oneAPI specification and open source extension of the Intel® oneAPI Math Kernel Library provides Data Parallel C++ interfaces for random number generator (RNG) routines, implementing commonly used pseudorandom, quasi-random, and non-deterministic generators with continuous and discrete distributions.
Just like some other oneMKL function domains, as a part of its implementation oneMKL RNG includes:
- Manual offload functionality (Random Number Generators Host API)
- Device functionality as a set of functions callable directly from SYCL kernels (Random Number Generators Device Routines).
We will show how the oneMKL Random Number Generators (RNG) Device API helps you significantly increase the computation performance on Intel® Data Center GPUs by a factor of two, compared to the Host API implementation on the same hardware.
We do this by looking at Host API and Device API RNG function call performance for the European and American option pricing models.
In addition, we will use the American option pricing model, using the Monte Carlo algorithm, as an example to demonstrate in a bit more detail how to migrate financial workloads from proprietary CUDA* code to the open, multi-platform SYCL programming model using SYCLomatic (or the Intel® DPC++ Compatibility Tool).
Results were achieved on Intel Data Center GPU Max 1550 with the oneAPI 2024.0 release.
RNG Device API Basics
The main purpose of device interfaces is to make them callable from SYCL kernels. It brings an essential performance boost because submitting time may greatly affect the overall execution time of the application. The idea is to get random numbers on the fly and process them in the same kernel without paying for global memory transfer. For example:
Host API
auto engine = oneapi::mkl::rng::mrg32k3a(*stream, 1ull);
oneapi::mkl::rng::generate(oneapi::mkl::rng::gaussian<double>(0.0, 1.0),
engine, n, d_samples);
sycl_queue.parallel_for(
sycl::nd_range<3>(sycl::range<1>(n_groups) * sycl::range<1>(n_items),
sycl::range<1>(n_items)),
[=](sycl::nd_item<1> item_1) {
post_processing_kernel(d_samples);
}).wait();
Device API
sycl_queue.parallel_for(
sycl::nd_range<3>(sycl::range<1>(n_groups) * sycl::range<1>(n_items),
sycl::range<1>(n_items)),
[=](sycl::nd_item<1> item_1) {
oneapi::mkl::rng::device::mrg32k3a<1> engine_device(1ull, n);
oneapi::mkl::rng::device::gaussian<double> distr(0.0, 1.0);
double rng_val = oneapi::mkl::rng::device::generate(distr, engine_device);
post_processing_kernel(rng_val);
}).wait();
The Host API code sequence above shows two instances of calls being initiated from CPU to GPU:
- The generate() function call that contains at least one SYCL kernel
- The offloaded parallel_for loop kernel, including nd_range and postprocessing
The Device API code sequence has all this embedded within a single offloaded parallel_for SYCL kernel, minimizing the data exchange between CPU and GPU.
So, it is easy to see that the number of kernels required for the implementation when using the Device API is smaller than the Host API. The RNG Device API is also available as a part of oneMKL Interfaces, an open-source project that can be found on GitHub*.
Let us consider American and European Monte Carlo workloads separately.
American Monte Carlo Option Pricing Model
To run this benchmark on an Intel® GPU, we took the original code from the NVIDIA* Developer Code Samples GitHub repository. We then migrated the native CUDA GPU code to SYCL using the SYCLomatic open-source project (SYCLomatic). This tool is included in the Intel® oneAPI Base Toolkit or available from GitHub under the Apache* 2.0 license. SYCLomatic allows us to port the original CUDA code to SYCL and automatically migrates about 95% of a general CUDA code to SYCL code.
Please find step-by-step instructions for migrating the American Monte Carlo option pricing model example source code to SYCL and inspect the SYCL-enabled example source code project in the GitHub repository.
To finish the process, we made some manual code changes and tuned it to the desired level of performance for our target architecture.
Additionally, after completing the SYCLomatic migration, we added a host interface call. To reduce the number of SYCL kernels used, we added device calls to the next kernel (generate_paths_kernel). This way, we reduce the number of kernels needed and remove the need for extra memory to store random numbers, as we use these numbers as soon as they are generated.
Applying the Device API interface capability, we obtain up to 2.13 times performance speed-up compared with traditional host interface calls. We observed a ~15% performance improvement for the overall application speed-up.
Figure 1 shows the performance scalability of American Monte Carlo benchmark results depending on the number of calculated paths. The RNG & next kernel speedup curve shows the performance increase of combining RNG device API and generate_paths_kernel usage compared to the Host API version using RNG Host interface calls and generate_paths_kernel separately. whole bench speedup shows overall the benchmark benefits of using RNG Device API compared to RNG Host API usage.
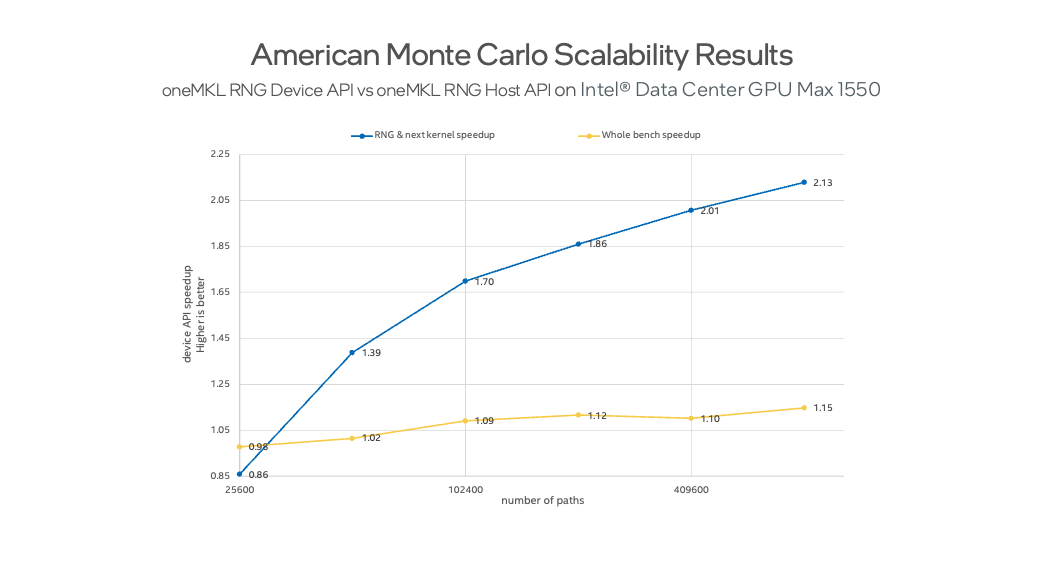
Figure 1. American Monte Carlo scalability results
Configuration details
Testing date: Performance results are based on testing by Intel as of November 24, 2023, and may not reflect all publicly available updates.
Configuration details and workload setup: 1-node, 2x Intel® Xeon® Platinum 8480+ CPU 56 cores, 512 GB; Ubuntu* 22.04.2 LTS, kernel: 5.15.47+prerelease70; Intel® oneAPI Math Kernel Library 2024.0 (oneMKL); Intel® DPC++ Compiler 2024.0.0 (2024.0.0.20231017); Intel® Level-Zero, Intel® Data Center GPU Max 1550 1.3 [1.3.26690]. GPU: Intel Data Center GPU Max 1550, GT frequency: 1.6 GHz, 1024 units, 2 tiles.
Performance varies by use, configuration, and other factors.
European Monte Carlo Option Pricing Model
Now that we looked at Device API and Host API performance for the American Monte Carlo option model, let us do the same for the European Monte Carlo option model and consider the performance of the Monte Carlo European Options Sample available on the oneAPI samples GitHub.
Let us see whether, for this use case, too, the use of the Device API is beneficial.
The difference from the American Monte Carlo model is that the code in the repository already uses a Device API. So, to be able to make the performance comparison, this time we need to add a Host API implementation. To add the Host API and model option pricing for a duration of one year, the option_years variable is being set to 1. After this consideration, we can easily replace device calls with a host call as a separate SYCL kernel. However, we need extra memory to store generated numbers.
Applying those changes, we found that operating memory on the GPU is insufficient to store ~100 000 000 000 double precision numbers as the original sample was configured to do. One drawback of Device API usage is the limited availability of localized memory on a GPU compared to a CPU, which can sometimes require more advanced shared memory management for large datasets. To keep the reference example fundamentally unchanged, other than the use of device API vs host API, we decided to reduce the number of calculated asset pricing evolution paths to 16,000. This allowed the code to run successfully using device API implementation without any large code changes.
Comparing Device API and Host API performance for the European options pricing prediction model, we see that here, too, execution speed benefits from the use of GPU Device APIs.
Figure 2 shows how the RNG Device API usage allows users to obtain a 3.69 times performance improvement for the whole European Monte Carlo benchmark compared to RNG Host API.
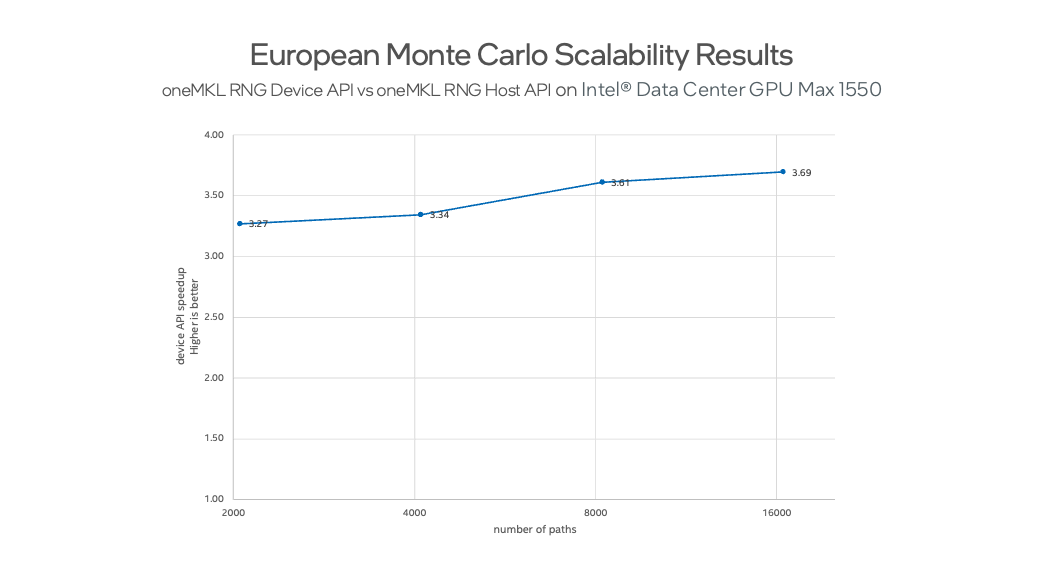
Figure 2. European Monte Carlo scalability results
Configuration details
Testing date: Performance results are based on testing by Intel as of November 24, 2023, and may not reflect all publicly available updates.
Configuration details and workload setup: 1-node, 2x Intel® Xeon® Platinum 8480+ CPU 56 cores, 512 GB; Ubuntu* 22.04.2 LTS, kernel: 5.15.47+prerelease70; Intel® oneAPI Math Kernel Library 2024.0 (oneMKL); Intel® DPC++ Compiler 2024.0.0 (2024.0.0.20231017); Intel Level-Zero, Intel® Data Center GPU Max 1550 1.3 [1.3.26690]. GPU: Intel Data Center GPU Max 1550, GT frequency: 1.6 GHz, 1024 units, 2 tiles.
Performance varies by use, configuration, and other factors.
Use oneMKL RNG Device API Routines to Your Advantage
Device API allows users to achieve an essential performance boost compared to host interfaces but requires much more coding and knowledge about specific domain implementations. It is also a more flexible API since users can control the parameters of SYCL parallel routines.
Results in this article can be applied to other applications (not only financial) that have calculations of random numbers on the critical performance path.
Addressing challenges is a regular process for Intel® Compiler and oneMKL software development teams. To make Intel® software better for our customers, we are constantly looking for both more efficient algorithms and better optimization techniques.
To get started now, look at the Intel oneAPI Math Kernel Library, the oneAPI Math Kernel Library (oneMKL) Interfaces project, and SYCLomatic.