6/20/2024
This article was originally published on VentureBeat.

CUDA* is a parallel computing programming model for Nvidia* GPUs. With the proliferation over the past decade of GPU usage for speeding up applications across HPC, AI and beyond, the ready availability of their GPUs and applications built on CUDA have given Nvidia a head start in the marketplace over other accelerated computing solutions.
However, CUDA’s proprietary and closed-source nature has left many scientific research facilities, AI startups and enterprises struggling with their dependency on the programming model. This has been particularly acute in recent months of highly limited supply of high-end NVIDIA GPUs 1, 2. Currently, it is predicted that this shortage, due to an increase in demand for accelerated offload computing and AI, will last well into 20253. Supply constraints notwithstanding, there are advantages to using a mix of workload-specific heterogeneous architectures including CPUs, GPUs, ASICs and FPGAs from across multiple vendors based on one’s specific compute, memory and energy needs.
The belief that progress in scientific and medical research, advanced image processing, AI-assisted data analytics and other domains should not be constrained by a closed developer programming model and a single proprietary architectural approach to computing was central to Intel kick-starting, in 2019, the oneAPI industry initiative as an open alternative to CUDA on the premise that unified programming is the future of application development.
Since its inception, the oneAPI programming model has garnered considerable momentum and is a cornerstone of the Unified Acceleration Foundation (UXL). Hosted by the Linux Foundation’s Joint Development Foundation (JDF), UXL brings together ecosystem participants to establish an open accelerated computing standard for developing applications that deliver cross-platform performance across a wide range of architectures. UXL boasts a distinguished list of participating organizations and partners, including Arm, Fujitsu, Google Cloud, Imagination Technologies, Intel, Qualcomm Technologies Inc. and Samsung.
Properties Of A Viable CUDA* Alternative
Moving a compute-intensive codebase from one hardware platform to another has been cumbersome and costly for a long time. Closed, single-vendor architecture programming limits code reuse and portability. This slows down large-scale adoption and proliferation of the latest technology advances. Providing an open, cross-industry, standards-based, unified, multiarchitecture, multivendor programming model is the one approach that promises a viable CUDA alternative by eliminating those limitations fully. Not only should the frontend API be open, but the abstraction layer backend must also be open to support a wide range of runtimes for GPUs and specialized accelerator implementations alike.
AMD*’s HIP, for example, does not meet this test. It is a C++ runtime API that allows developers to write code to run on AMD and NVIDIA GPUs. It is an interface that uses the underlying ROCm or CUDA platform runtime installed on a system. It essentially serves as a compatibility wrapper for CUDA and ROCm if used that way. The HIP approach is also limited by its dependency on proprietary CUDA libraries.
This does not solve the problem, and it does not create a truly portable solution. It only creates a slightly bigger walled garden that does not allow the developer to take advantage of power savings, reduced heat dissipation or the performance benefit that specialized accelerators or other GPU architectures may provide. There is a whole ecosystem of current and future accelerated computing use cases that the HIP approach does not cover.
Approaches such as OpenCL (high complexity), Java (compromised performance) and others also exhibit limitations.
On the other hand, the Khronos Group’s SYCL open source, royalty-free, cross-platform abstraction layer allows developers to deliver uncompromised performance on heterogeneous architectures in standard C++.
As a hardware-agnostic organic extension of standard ISO C++, SYCL intuitively presents itself as a viable foundation for a unified, open alternative approach with wide ecosystem acceptance.
- It allows code execution on any open backend-compliant device runtime, whether a CPU, GPU, FPGA or other accelerator.
- It manages data resources and code execution on targeted devices.
- It is open to interfacing with any lower-level proprietary runtimes.
Once SYCL is combined with a rich ecosystem of libraries, tools and framework optimizations, maximizing developer productivity, we have the viable alternative developers are looking for. Also important is an easy way to move legacy GPU code and migrate existing CUDA applications to SYCL seamlessly, while also ensuring that the original code performance is maintained.
Promise Of Portability And Performance With oneAPI
This is where oneAPI comes in. It leverages the SYCL framework and combines it with the compilers, APIs, libraries, tools and code samples that were needed to create a rich catalog of fully SYCL and oneAPI-enabled applications.
Doing so turns the vision of providing developers with a common developer experience across multiple accelerator architectures into reality. It makes ubiquitous multiarchitecture and multivendor computing achievable.
- “Multiarchitecture” means that a single source code can be compiled and run across different architectures, including but not limited to CPUs, GPUs and FPGAs.
- “Multivendor” signifies the ability to compile and execute a common code on devices from different manufacturers.
Ecosystem collaboration on the open oneAPI specification and compatible oneAPI implementations has grown dramatically across individual open-source software developers, research institutions, enterprise solution providers and hardware platform vendors alike.
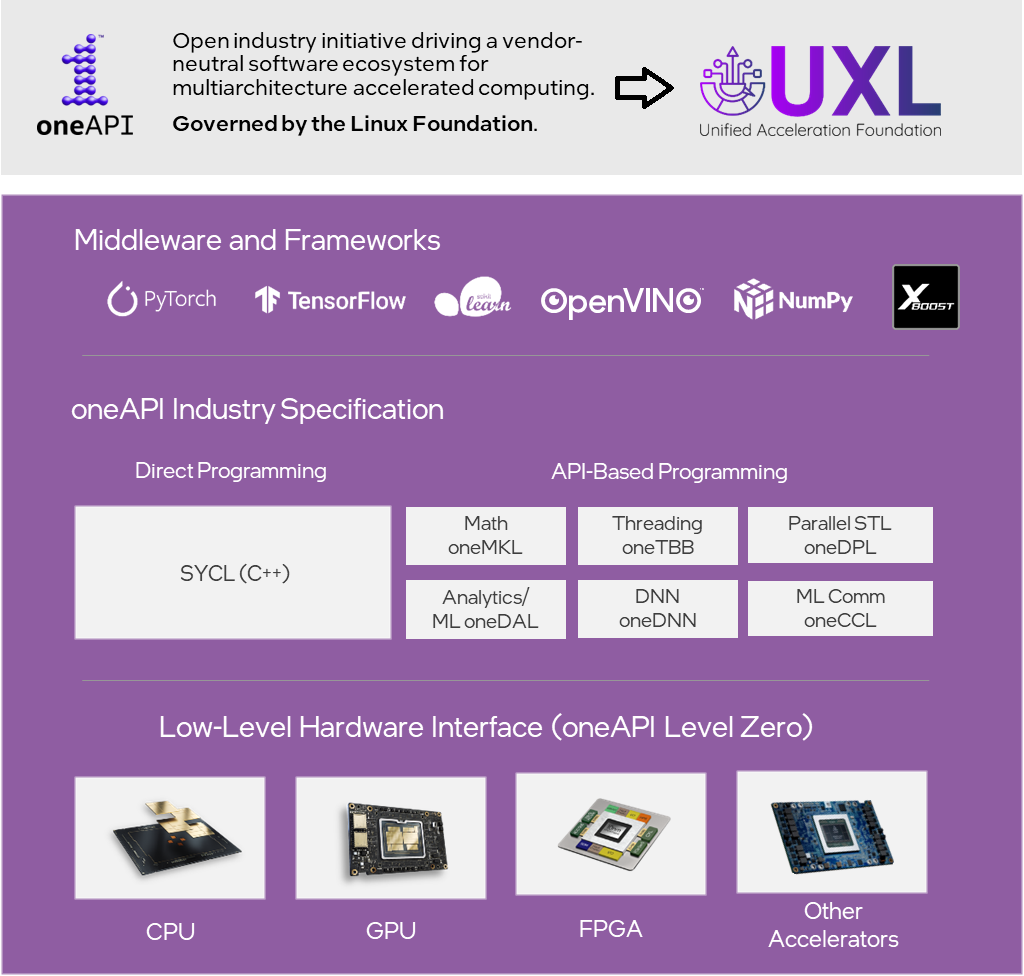
Fig.1: Unified multiarchitecture software stack for accelerated computing
As we can see in Figure 1,
- the API spec elements cover many use cases, including math (oneMKL), neural networks (oneDNN), threading (oneDPL and oneTBB), distributed communications (oneCCL), data compression and accelerator offload.
- Level Zero provides powerful and open system-level interfaces to create your own custom runtime libraries for a computing device of your choice.
- SYCLomatic turns code migration from CUDA to SYCL into a simple, guided, step-by-step process.
As the oneAPI Initiative’s ecosystem partners contribute, the rich capabilities of this unified framework will only grow.
Intel also provides a reference implementation of the oneAPI spec for Intel architectures.
- The Intel® oneAPI Base Toolkit is a foundational set of comprehensive tools, including optimized oneAPI specification components. It provides a C++ with SYCL-enabled Intel® oneAPI DPC++/C++ Compiler, based on the open-source LLVM compiler infrastructure project and its Clang frontend.
- The Intel® HPC Toolkit expands these concepts to multi-node and cluster HPC computing and the Intel® Fortran Compiler.
- The Intel® AI Tools provide framework and library optimizations for training and inference to accelerate end-to-end data science and analytics pipelines to the developer solutions built around the oneAPI philosophy.
All this is complemented with the Intel® DPC++ Compatibility Tool binary distribution of the SYCLomatic CUDA-to-SYCL migration tool and advanced performance analysis and profiling tools like Intel® VTune™ Profiler and Intel® Advisor.
Migration from CUDA to oneAPI results in not just seamless application portability across multiple architectures but performance portability as well. Developers rightfully expect CUDA to SYCL code migration to both be easy and achieve comparable performance on the original pre-migration platform as well as newly targeted hardware configurations.
Here is a relative performance (Fig. 2 & 3) of select datasets looking at the original CUDA or HIP code performance on their native hardware platform configurations against the SYCL code performance on the exact same setup.
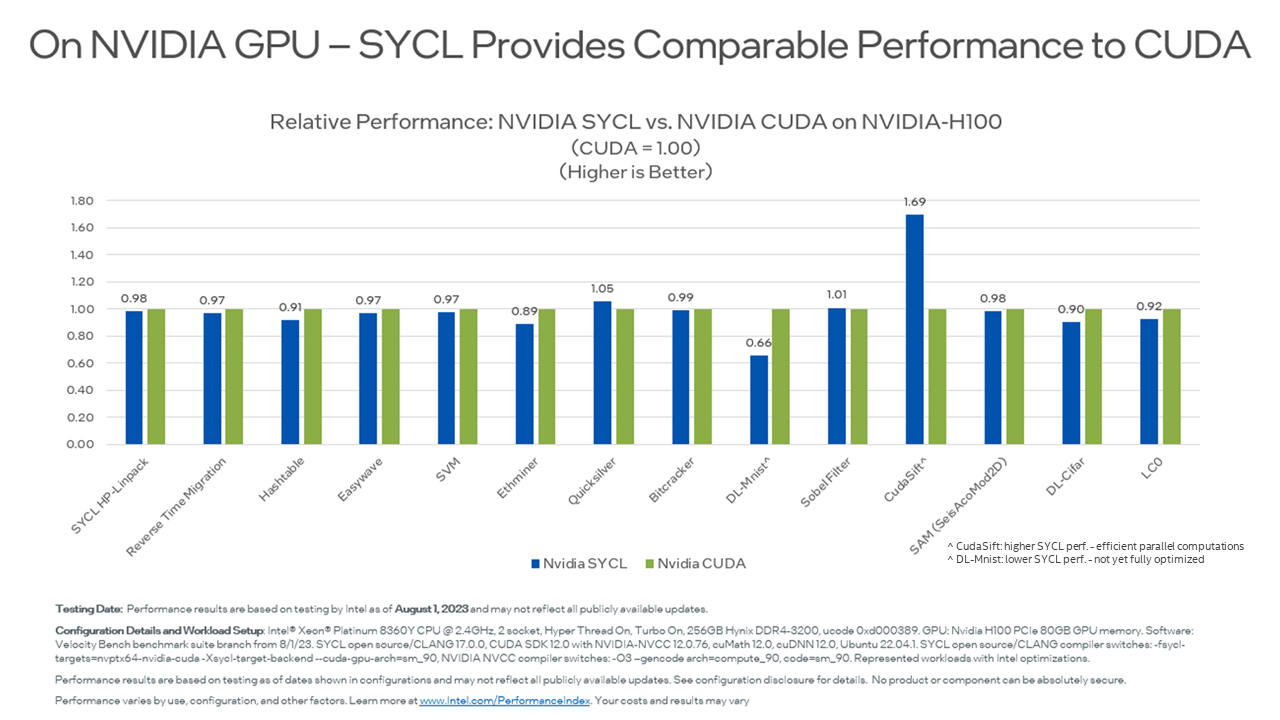
Fig. 2: Relative Performance: NVIDIA SYCL vs. NVIDIA CUDA on NVIDIA-H100
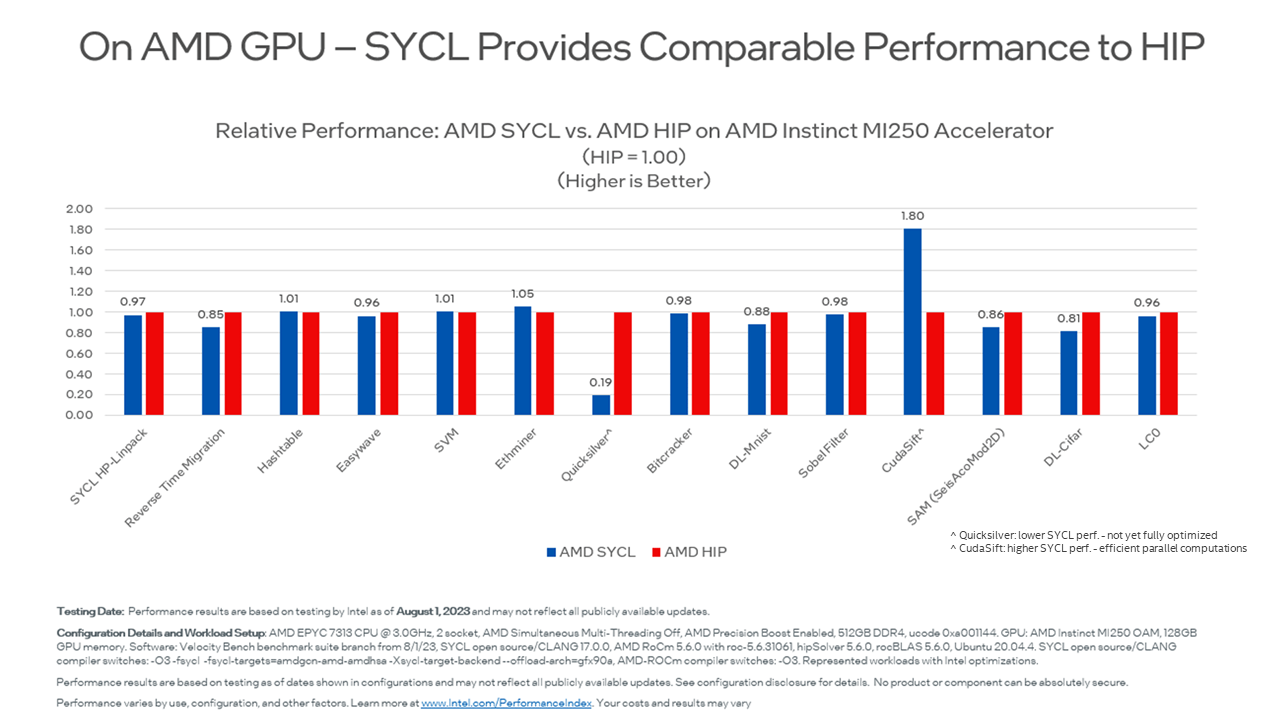
Fig. 3: Relative Performance: AMD SYCL vs. AMD HIP on AMD Instinct MI250 Accelerator
Following its recognition in previous years, the Intel oneAPI software tools and libraries were again recognized by the readers of HPCwire magazine with the Reader’s Choice Award 2023 for Best HPC Programming Tool or Technology.
oneAPI Ecosystem Momentum
A change is happening where heterogeneous computing is gaining widespread adoption, not just in HPC4 and AI but beyond. Multiarchitecture computing has been around for a while, but its increased use across a wide range of applications is driving a major shift in the industry. The increasing demand for data-intensive workloads has led to a proliferation in the use of accelerators, and most recently, the emergence of LLM (large language model)-based AI applications has created an explosion in both the usage of and public attention in GPUs and AI accelerators.
The growing momentum of oneAPI’s approach to meeting this ecosystem need of a unified model to simplify programming in a heterogeneous architecture environment is evident when looking at computer scientists at over 30 universities and research institutions migrating and optimizing their software as part of the oneAPI Centers of Excellence program, freeing solutions for molecular dynamics, fluid dynamics, medical drug discovery, particle physics, nuclear interactions, earthquake prediction and environmental surveys from vendor lock-in.
oneAPI forms the backbone of the exascale Aurora supercomputer at Argonne Labs’ Argonne Leadership Computing Facility’s (ALCF) Early Science Program.
Hundreds of organizations and countless developers contribute to the many ready-to-use SYCL migrated and optimized solutions available:
- The oneAPI Community GitHub maintains an Awesome List of oneAPI Projects.
- The oneAPI ecosystem’s Catalog of SYCL-migrated Applications is continuously expanding.
- The oneAPI Centers of Excellence propel the adoption of technologies optimized by oneAPI across academia and research institutions.
Those adopting oneAPI, often see a significant performance boost over previous implementations.
Just as Linux*, LLVM* and GNU* transformed the software stack for CPUs using open source and standards-based projects, the same is now happening for multiarchitecture compute.
Multiple initiatives are underway to add open reference backend implementations for various oneAPI library spec elements, allowing your code to target several accelerators out of the box. UXL Foundation members such as Codeplay5 added plugins and runtime libraries to ensure the ported code can run seamlessly on AMD and NVIDIA devices. Intel provides its own highly optimized Intel® Graphics Compute Runtime for oneAPI Level Zero and OpenCL™ Driver. Finally, a oneAPI Construction Kit opens the runtime backend to anyone who wants to add their own accelerator offload device to the framework.
The Path To A Bright Future
oneAPI and the UXL Foundation, by embracing neutrality and independence, are charting the way for the future of accelerated computing. Building on open specifications and embracing industry standards will transform how complex compute-intensive applications are developed and deployed across a diverse and evolving set of multiarchitecture, multivendor platforms, all while fostering faster software development cycles, wider deployment options and more ubiquitous computing.
We encourage you to get started on your journey towards code freedom with oneAPI by exploring the CUDA to SYCL Migration Portal and learning more about the UXL foundation. You can also try out and evaluate all of Intel’s oneAPI-powered tools on Intel Developer Cloud.
References:
1 Dave, Paresh. “Nvidia Chip Shortages Leave AI Startups Scrambling for Computing Power” WIRED, 24 Aug. 2023
2 Shilov, Anton. “TSMC: Shortage of Nvidia’s AI GPUs to Persist for 1.5 Years” Tom’s Hardware, 7 Sep. 2023
3 Griffith, Erin. “The Desperate Hunt for the A.I. Boom’s Most Indispensable Prize” New York Times, 16 Aug. 2023
4 Evans Data Corporation, “Developer Marketing Survey Report” 2023
5 Codeplay is an Intel company