It is a general misconception that GPUs are necessary to train deep learning (DL) models. There are many complex DL models that train more efficiently on CPUs using distributed training configurations. Intel® Xeon® Scalable Processors have built-in AI acceleration with Intel® Deep Learning Boost instructions. This article describes how to set up distributed training on a cluster using TensorFlow* and Horovod*.
TensorFlow is a widely used DL framework that is optimized for Intel® processors and other architectures using Intel® oneAPI Deep Neural Network (oneDNN), an open-source, cross-platform library for DL applications. The TensorFlow optimizations enabled by oneDNN accelerate key performance-intensive operations, such as convolution, matrix multiplication, batch normalization, and many more. Horovod is an open-source package that facilitates distributed DL with TensorFlow and other popular frameworks such as PyTorch*. It is widely used to train models across multiple GPUs and CPUs.
AI Arena is an open platform presented by Tencent for the research of multi-agent intelligence and complex decision-making. The platform includes a wide range of services that can help AI researchers to build their experiment environment conveniently. Tencent has shown a real-world case of building an AI agent in the smash-hit mobile game Honor of King with AI Arena platform, which involves multi-agent competition and cooperation, imperfect information, complex action control, and massive state-action space. This AI agent could make players have more fun to enhance game playability. We present a case study of Tencent’s production-level model training on a 16-node cluster comprised of Intel Xeon Scalable Processors, achieving up to 15.2x speedup over a single node.
Running Distributed Deep Learning (DL) Training
You can either use a prebuilt Docker* container with TensorFlow with oneDNN enabled, which has everything you need:
docker pull intel/intel-optimized-tensorflow:2.6.0-ubuntu-18.04-mpi-horovod
Or you can manually install TensorFlow (v2.6 or later) with oneDNN enabled, Horovod (v0.22.1 or later), and Open MPI (v4.0 or later). Be sure to check your GCC version. If you are using Ubuntu* 16.04 or older, install GCC v8.4.1 or later.
Use the following commands to run distributed TensorFlow using the Horovod framework on a Linux* cluster. First, set the following environment variables:
export LD_LIBRARY_PATH=<path to OpenMP lib>:$LD_LIBRARY_PATH
export PATH=<path to Open MPI bin>:$PATH
export OMP_NUM_THREADS=#of_cores of the machine [e.g., lscpu | grep "Core"]
export KMP_AFFNITY=granularity=fine,compact,1,0
export KMP_BLOCKTIME=1
Before starting the training, we can find out how many sockets are in the system using the following command:
lscpu | grep "Socket"
Use the following command to run the training on one server with two sockets. Here, the total number of workers is two:
horovodrun -np 2 -H localhost:2 --autotune python train.py
To run the training across four servers, each with two sockets, use this command. Here, the total number of workers is eight (one worker on each socket).
horovodrun -np 8 -H server1:2,server2:2,server3:2,server4:2 --autotune python train.py
To run on eight servers, each with one socket, use this command. Here, the total number of workers is also eight.
horovodrun -np 8 \
-H server1:1,server2:1,server3:1,server4:1,server5:1,server6:1,server7:1,server8:1 \
--autotune python train.py
As you can see, you can scale the number of servers up or down depending on the time-to-train that you want to achieve for your model. Time-to-train is expected to scale almost linearly with the number of servers used. Hyperparameter optimization is also done, as it would be for training on multiple GPUs. The learning rate and effective batch size can often be scaled by the number of workers. An increase in the learning rate can often compensate for the increased batch size.
Case Study: Training Wukong AI*
Wukong AI*, an artificial intelligence program, playing Honor of Kings, a popular MOBA game published by Tencent, exceeds the performance of top-professional player. Wukong AI uses reinforcement learning (RL). The goal of RL is to select and optimize appropriate policies to strengthen the AI agent. Selection of these policies can be optimized in deep RL training. Distributed training is used to scale the training process to multiple RL learners on the cluster of 2nd Generation Intel Xeon Scalable Processors.
We started off on a single node and single worker to measure the baseline performance, then scaled up to more workers until we reached the desired time-to-train. We achieved the required performance with 16 nodes. In this case study, distributed training gave up to 15.2x speedup over the baseline performance (Figure 1). This is nearly linear speedup with distributed training on our Intel Xeon processor-based cluster.
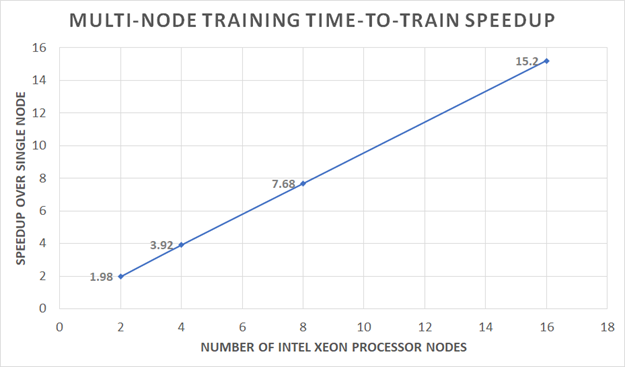
Figure 1. Distributed training gives significant speed-up over baseline performance.
Intel Xeon Scalable processors provide the performance required to train a variety of production workloads. Using Horovod* for distributed training reduces the time-to-train. In this blog we shared a recent case study used by Tencent AI Lab.
Stay tuned for more blogs and articles as Intel adds more hardware acceleration in the next generation Intel Xeon Scalable processors and software acceleration to continue to meet users’ needs.
Resources and Support
You can get more information from the following sites:
For help with technical questions, visit the following communities and forums to find answers and get support:
System Configuration
|
TensorFlow Source Code |
|
|
TensorFlow Version |
2.6.0 |
|
CPU |
76 |
|
Threads per core |
2 |
|
Cores per socket |
19 |
|
Sockets |
2 |
|
NUMA nodes |
2 |
|
Vendor ID |
GenuineIntel |
|
BIOS Vendor ID |
Smdbmds |
|
CPU family |
6 |
|
Model |
85 |
|
Model name |
Intel Xeon Platinum 8255C Processor @ 2.50 GHz |
|
BIOS Model name |
3.0 |
|
Stepping |
5 |
|
Hyper Threading |
ON |
|
Turbo |
ON |
|
Memory |
256 GB |
|
OS |
Red Hat Enterprise CentOS Linux version 8.2 (Core) kernel 4.18.0-305.3.1.el8.x86_64 x86_64 |
See Related Content
On-Demand Webinars
- Improve Performance on Distributed Deep-Learning Training Workload
Watch
Articles
- Optimize Distributed AI Training using Intel® oneAPI Toolkits
Read - Speed up Databricks Runtime for ML with Intel-optimized Libraries
Read - Getting Started with Habana® Gaudi® for Deep Learning Training
Read - Hyperparameter Optimization with SigOpt for MLPerf Training
Read - WeBank* Cryptography Case Study
Download
Podcast
- Google and Intel Optimize TensorFlow for Deep Learning Performance
Listen