As part of our mission to bring AI everywhere, Intel is continuously investing in the AI ecosystem to ensure its platforms are ready for the industry’s newest AI models and software. Today, we are excited to announce the support of Phi-3, a family of small, open AI models developed by Microsoft*, with our AI solutions across datacenter platforms, AI PCs and platforms for the edge.
The Phi-3 family – tiny but mighty models – offers capable and cost-effective options for developers and customers to build generative AI applications. Phi-3-mini, a 3.8B language model was made available in late April. Today, Microsoft released new models in the Phi-3 family to offer users more flexibility across the quality-cost curve. At the same time, Intel’s AI products, from Intel® Gaudi® AI accelerators and Intel® Xeon® processors in the datacenter to AI PCs and edge solutions powered by Intel® Arc™ GPU and Intel® Core™ Ultra, support the new Phi-3 models.
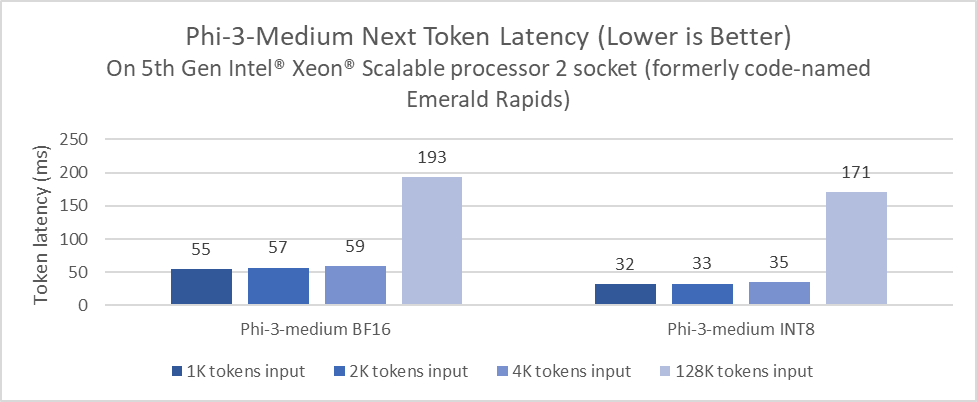
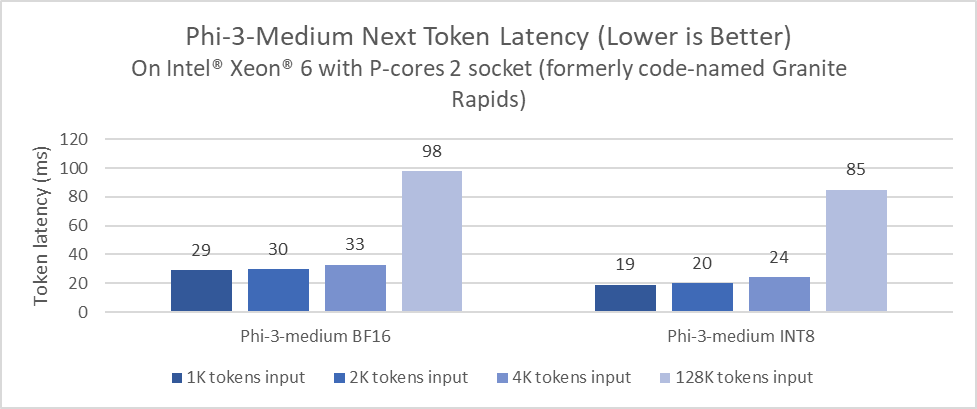
Intel® Xeon® processors with Intel® Advanced Matrix Extensions (AMX) in every core address demanding end-to-end AI workloads and unlock new levels of performance for inference and training. The preview numbers of Phi-3-medium 4k and 128k variants that we collected on Xeon demonstrate that widely available Xeon processors are a performant viable option for LLM inference deployment, and Intel® Xeon® 6 offers up to 2x improvement on Phi-3-medium inference latency compared to 5th Gen Intel Xeon processors.
According to Microsoft, Phi-3 offers outstanding reasoning and language understanding capabilities, outperforming models of the same size and its next size up, which is perfect for the AI PC or edge. Running Phi-3 on the AI PC and edge devices offers benefits such as personalization, privacy, and responsiveness. Intel enables LLMs to run locally on either AI PCs powered by Intel® Core™ Ultra with an NPU and available built-in Arc™ GPU, or on Arc discrete GPUs with Intel® Xᵉ Matrix Extensions (Intel® XMX) acceleration. The size of Phi-3 models makes it a perfect fit for use in on-device inference and makes possible lightweight model fine-tuning or customization on AI PCs.
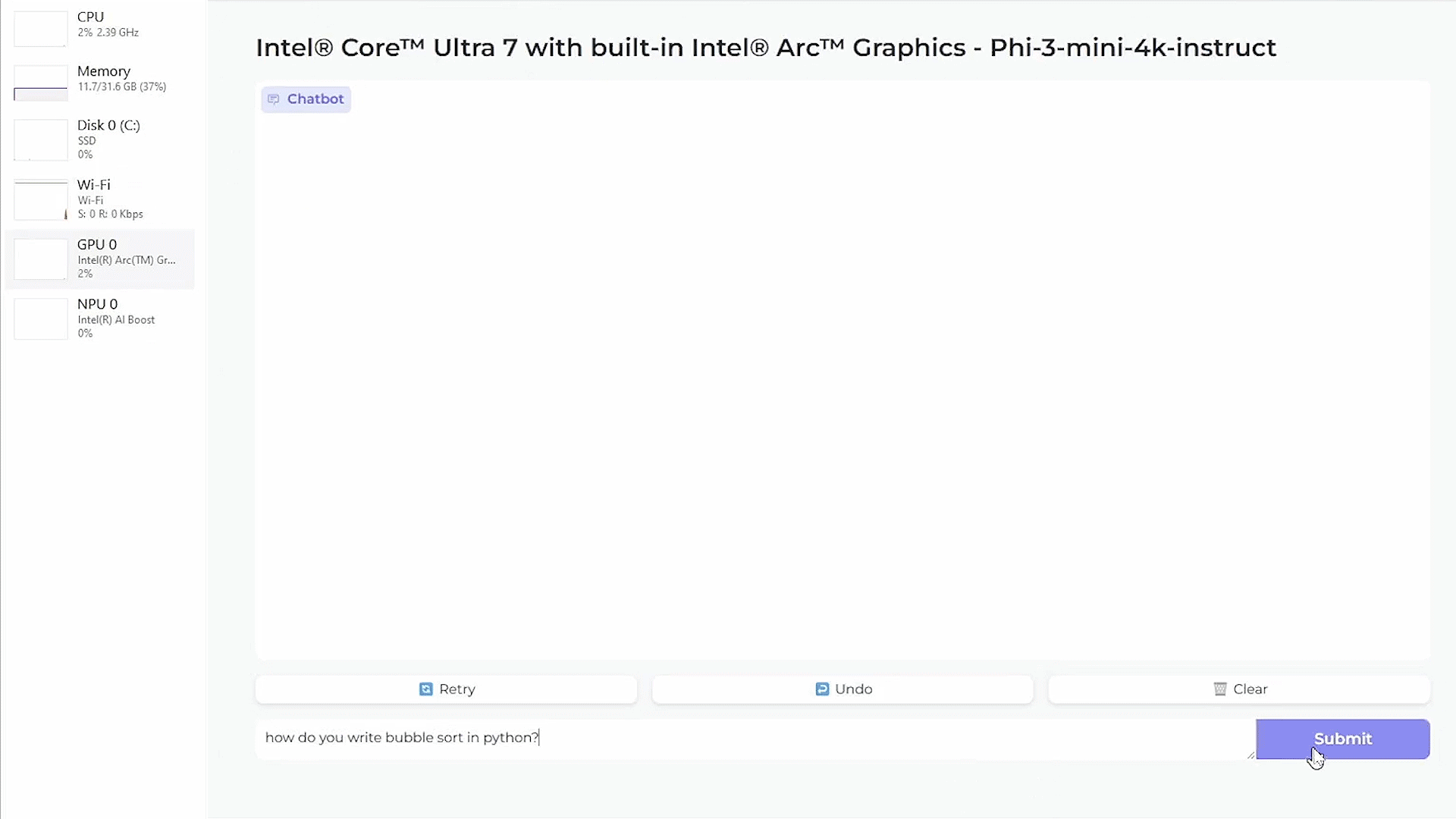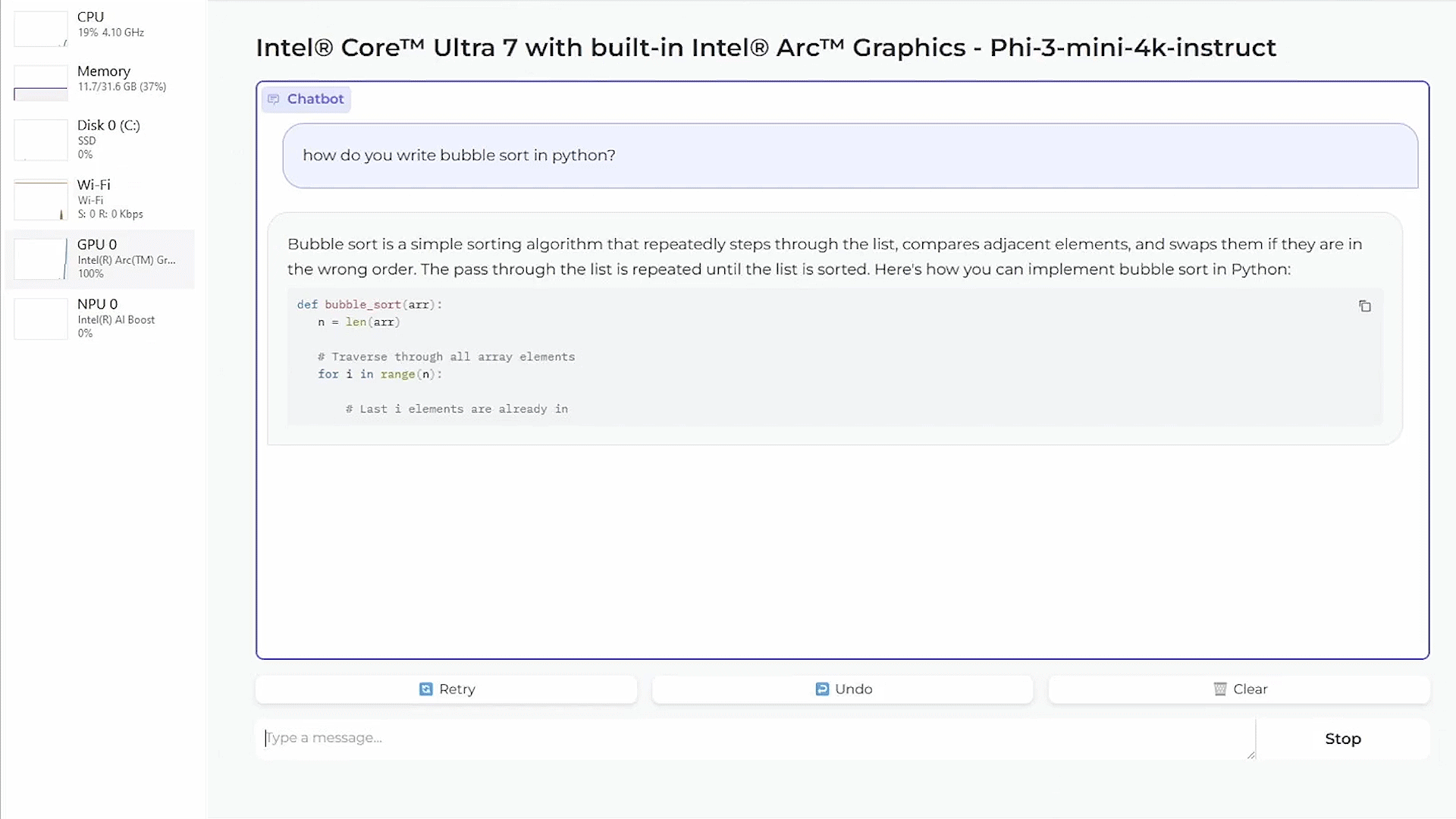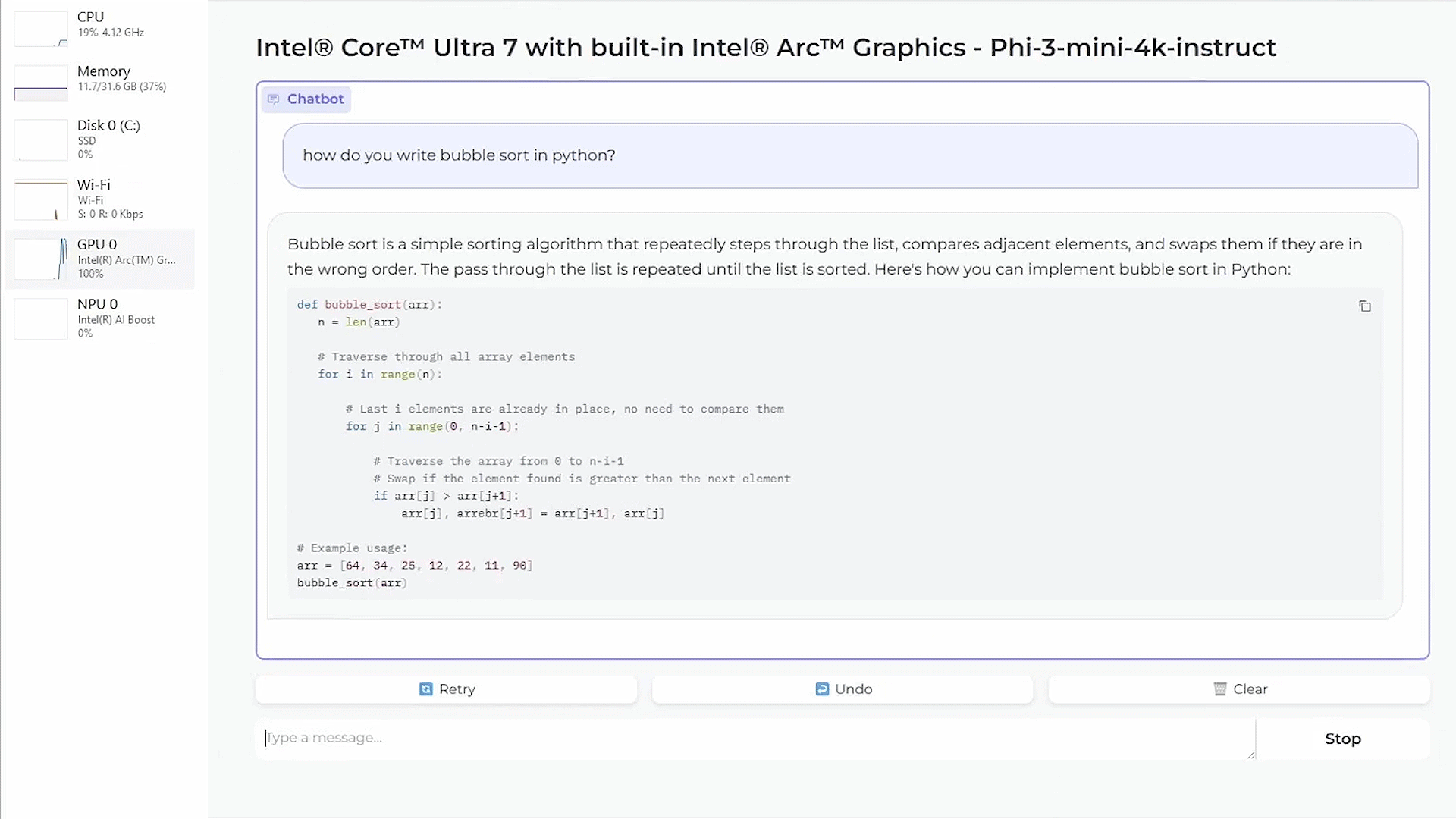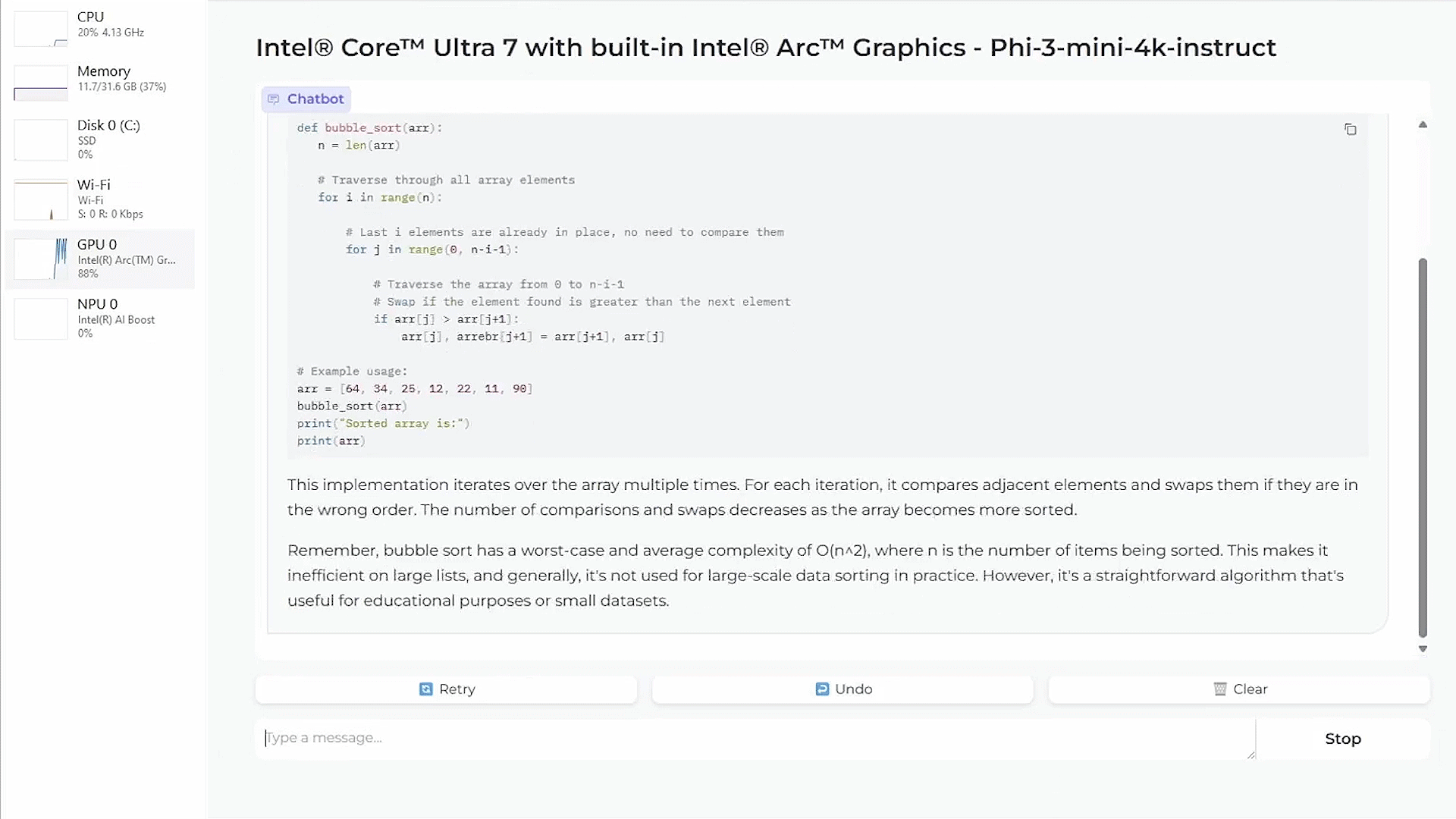
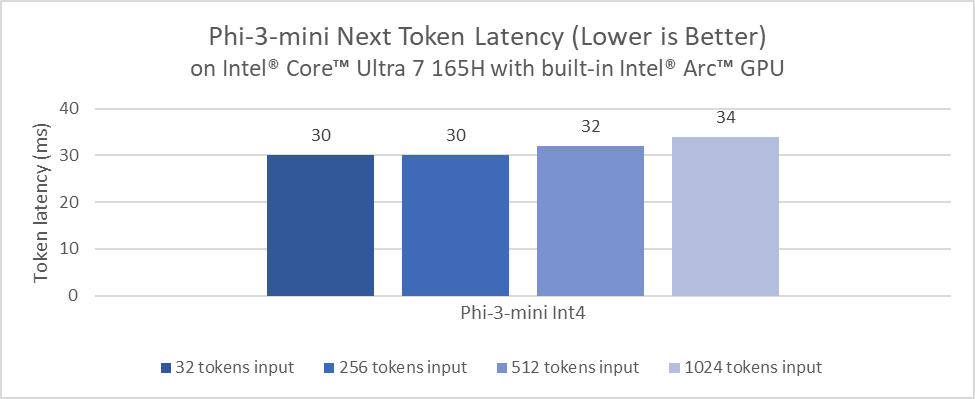
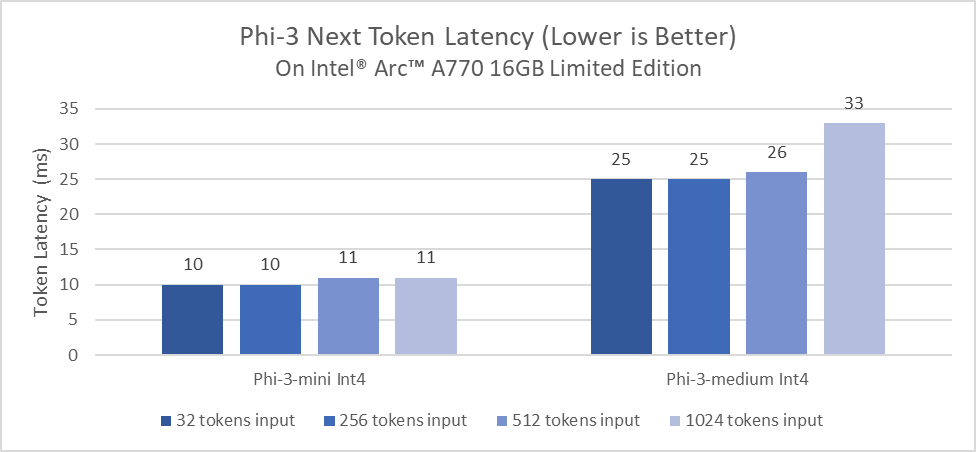
We benchmarked inference latency of Phi-3-mini 4k variant on AI PC powered by Intel® Core™ Ultra 7 165H built in Arc™ GPU and the Phi-3-mini and phi-3-medium 4k variants on Intel® Arc™ A770 discrete graphics with impressive token generation latency.
Enjoy our technical demo of running a chatbot powered by Phi-3-mini on AI PC powered by Intel® Core™ Ultra processors!
Running LLMs efficiently requires many software optimizations, such as performant fused kernels, quantization, KV caching, PagedAttention, and Tensor Parallelism. Intel hardware is accelerated through comprehensive software frameworks and tools, such as PyTorch* & Intel® Extension for PyTorch, OpenVINO™ Toolkit, DeepSpeed*, Hugging Face libraries and vLLM for optimal LLM inference performance.
Further, Intel has a long-standing relationship with Microsoft in AI software for both datacenter and client. Intel collaborated with Microsoft to co-design the accelerator abstraction in DeepSpeed and enable CPU, Gaudi and GPU support. Intel also extended automatic Tensor Parallelism to support multiple LLMs, including Phi-3. Intel also collaborates closely with Microsoft on DirectML and ONNX Runtime for deployment of AI features on the AIPC.
Xeon based instances are available across major cloud service providers and Intel® Tiber™ Developer Cloud. Gaudi 2 (and soon Gaudi 3) is also available in Tiber Developer Cloud. Here are the resources for getting started, try out Phi-3 today with Intel’s AI solutions.
- Gaudi Examples
- PyTorch Get Started on Intel Xeon and AI PCs
- OpenVINO Jupyter notebook for chatbot on Intel AIPC or Xeon
Product and Performance Information
Intel Xeon Processor: Measurement on Intel Xeon 6 Processor (formerly code-named: Granite Rapids) using: 2x Intel® Xeon® 6 processors with P-cores, HT On, Turbo On, NUMA 6, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[on CPU, 8], Total Memory 1536GB (24x64GB DDR5 8800 MT/s [8800 MT/s]), BIOS BHSDCRB1.IPC.0030.D67.2403082259, microcode 0x810001a0, 1x Ethernet Controller I210 Gigabit Network Connection 1x SSK Storage 953.9G, Red Hat Enterprise Linux 9.2 (Plow), 6.2.0-gnr.bkc.6.2.4.15.28.x86_64, Test by Intel on May 10th 2024. Repository here.
Measurement on 5th Gen Intel® Xeon® Scalable processor (formerly code-named: Emerald Rapids) using: 2x Intel(R) Xeon(R) Platinum 8593Q, 64cores, HT On, Turbo On, NUMA 4, Integrated Accelerators Available [used]: DLB [2], DSA [2], IAA[2], QAT[on CPU, 2], 512GB (16x32GB DDR5 5600 MT/s [5600 MT/s]), BIOS 3B07.TEL2P1, microcode 0x21000200, 1x Ethernet Controller X710 for 10GBASE-T 1x KBG40ZNS1T02 TOSHIBA MEMORY 953.9G 1x Samsung SSD 970 EVO Plus 2TB, CentOS Stream 9, 5.14.0-437.el9.x86_64, Test by Intel on May 10th 2024. Repository here.
Intel® Core™ Ultra: Measurement on a Microsoft Surface Laptop 6 with Intel Core Ultra 7 165H platform using 32GB LP5x 7467Mhz total memory, Intel graphics driver 101.5518, IPEX-LLM 2.1.0b20240515, Windows 11 Pro version 22631.3447, Performance power policy, and core isolation enabled. Intel® Arc™ graphics only available on select H-series Intel® Core™ Ultra processor-powered systems with at least 16GB of system memory in a dual-channel configuration. Test by Intel on May 16th, 2024. Repository here.
Intel® Arc™ A-Series Graphics: Measurement on Intel Arc A770 16GB Limited Edition graphics using Intel Core i9-14900K, ASUS ROG MAXIMUS Z790 HERO motherboard, 32GB (2x 16GB) DDR5 5600Mhz and Corsair MP600 Pro XT 4TB NVMe SSD. Software configurations include Intel graphics driver 101.5448, IPEX-LLM 2.1.0b20240515, Windows 11 Pro version 22631.3447, Performance power policy, and core isolation disabled. Test by Intel on May 16th, 2024. Repository here.
References
Tiny but mighty: The Phi-3 small language models with big potential
Phi-3 Technical Report : A Highly Capable Language Model Locally on Your Phone (arXiv: 2404.14219)
Boost LLMs with PyTorch on Intel Xeon Processors
Efficient LLM inference solution on Intel GPU (arXiv: 2401.05391)
AI disclaimer:
AI features may require software purchase, subscription or enablement by a software or platform provider, or may have specific configuration or compatibility requirements.
Details at www.intel.com/AIPC.