Generative AI powered by large language models (LLM) has become important for generating text, summarizing and translating content, responding to questions, engaging in conversations, and performing more complicated tasks, such as solving math problems or reasoning. LLMs are built with a transformer-based architecture with multiple decoder layers, which generate the next token from the preceding tokens. Typical LLMs that are available in the community are GPT-J, Llama, and Falcon, among others. The parameter size of LLMs scales from one billion to several hundreds of billions, which requires specific optimizations in a software stack to make the models run quickly in acceptable latency. In this article, we show you the PyTorch* Optimizations from Intel and how to apply these optimizations for LLM, and the performance benefit of using an Intel® Xeon® processor, which is one of the easiest ways to build your LLM inference service considering its wide availability.
Software Stack with Dedicated Optimizations for LLMs
PyTorch is a popular deep learning framework that provides tensor computing with strong acceleration via various hardware platforms and a tape-based automatic differentiation system. PyTorch has rich ecosystems that makes it the framework of choice for domains like LLMs. This framework continuously grows with massive new optimizations and features for various new trending areas. LLMs are one of the interesting areas to be optimized in PyTorch in the future. This article introduces Intel® Extension for PyTorch*, which helps optimize the performance for LLMs.
Intel Extension for PyTorch is an open source library extending PyTorch with up-to-date features and optimizations for an extra performance boost on Intel hardware to take advantage of hardware capabilities like:
- Intel® Advanced Vector Extensions 512 (Intel® AVX-512)
- Vector Neural Network Instructions (VNNI)
- Intel® Advanced Matrix Extensions (Intel® AMX) on Intel CPUs
- Intel® Xe Matrix Extensions (Intel® XMX) AI engines on Intel discrete GPUs.
Starting with v2.2.0, Intel Extension for PyTorch provides comprehensive feature support and optimization for the LLM domain through its dedicated module called ipex.llm. On the operator level, the extension provides an efficient GEMM kernel to speed up the linear layer and customized operators to reduce the memory footprint. To better trade off the performance and accuracy, different low-precision solutions—such as SmoothQuant and weight-only-quantization—are also enabled, which allows the extension to support datatypes that include FP32, BF16, SmoothQuant for int8, and weight-only quantization for int8 and int4 (experimental). Typical key technical points like paged attention, ROPE fusion, and Tensor Parallelism are included to boost the performance for LLMs. The optimization from Intel Extension for PyTorch has been applied and verified for a wide set of LLMs across different datatypes. The following table shows the latest verified status (green means the model has been verified with good performance and good accuracy, while yellow means accuracy may exceed 1% when compared to the FP32 datatype):
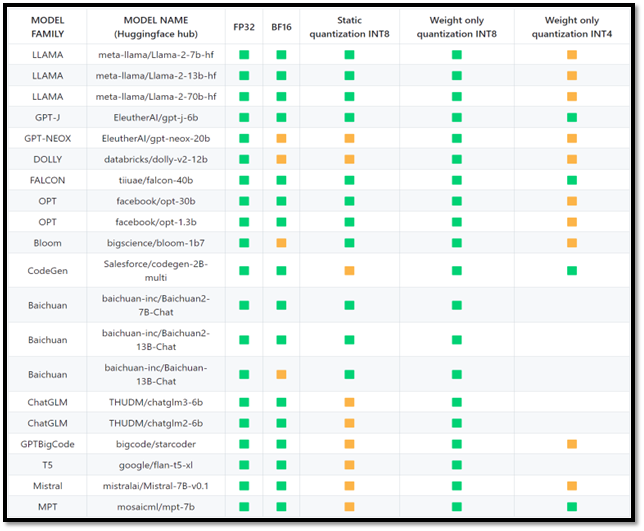
Table 1. Verified model list with optimization from Intel Extension for PyTorch (Image source: GitHub*)
How to Apply the Optimized Software Stack for LLM
This section shows how to speed up the LLM inference across different precisions (BF16, int8) and multi-node scenarios.
Let’s start with BF16 precision, which has been widely used for deep learning training and inference. The LLMs inference uses iterative decoding and is the typical memory-bound workload. Both model weights and kv_cache will introduce a memory footprint for every token decoding step. BF16 only consumes half of the memory compared with float32, which makes it a better choice than float32. The following code is an example of enabling the llama2-7b BF16 inference with Intel Extension for PyTorch. Compared to the original normal inference steps, only a single line of code is added to invoke the optimization:
import torch
import intel_extension_for_pytorch as ipex
import transformers
model= transformers.AutoModelForCausalLM(model_name_or_path).eval()
dtype = torch.bfloat16
model = ipex.llm.optimize(model, dtype=dtype)
# inference with model.generate()
...
To further reduce the memory footprint of model weights, int8, which only occupies 8 bits, can be used when slight accuracy loss is acceptable. The LLM inference is a memory-bound workload. The memory read is the largest hot spot. Based on this, a new quantization technology called weight-only quantization (WOQ) shows more potential than traditional static quantization and dynamic quantization. WOQ stores the weight in a low-precision data type (like int8) and computes with any data type (float32, BF16, float16, and int8) based on the trade-off between the accuracy and performance. Here is a typical example:
import torch
import intel_extension_for_pytorch as ipex
import transformers
model= transformers.AutoModelForCausalLM(model_name_or_path).eval()
qconfig = ipex.quantization.get_weight_only_quant_qconfig_mapping(
weight_dtype=torch.qint8,
lowp_mode=ipex.quantization.WoqLowpMode.BF16,
)
model = ipex.llm.optimize(model, quantization_config=qconfig)
# inference with model.generate()
...
SmoothQuant, another low-precision technology, is also supported in Intel Extension for PyTorch to reduce the accuracy impact based on traditional static quantization.
With the previous optimizations, you can already get good performance on a single Intel Xeon processor. To further reduce the inference latency, we can also use DeepSpeed to enable Tensor Parallel based distributed inference, which can then take advantage of the computation power of multiple nodes for the Intel Xeon processor and push the inference latency even lower. The following is sample code that shows how to perform distributed inference with BF16 precision.
import torch
import intel_extension_for_pytorch as ipex
import deepspeed
import transformers
dtype = torch.bfloat16
deepspeed.init_distributed(deepspeed.accelerator.get_accelerator().communication_backend_name())
world_size = ... # get int from env var "WORLD_SIZE" or "PMI_SIZE"
with deepspeed.OnDevice(dtype=dtype, device="meta"):
model= transformers.AutoModelForCausalLM(model_name_or_path).eval()
model = deepspeed.init_inference(
model,
mp_size=world_size,
base_dir=repo_root,
dtype=dtype,
checkpoint=checkpoints_json,
**kwargs,
)
model = model.module
model = ipex.llm.optimize(model, dtype=dtype)
# inference
...
More detailed examples can be found on GitHub, which can be used as a reference for LLM inference.
Demonstrated LLM Performance
With the optimizations from Intel Extension for PyTorch, we benchmarked a set of typical LLMs on 5th gen Intel® Xeon® Scalable processors, including GPT-J 6B, LLaMA2 7B and 13B, and larger size models like GPT-NeoX 20B, Falcon-40B to give you a wide picture of LLM performance on a single server with Intel Xeon processors. The test is done with an input token length across 128 to 2K to simulate different usage scenarios.

Figure 1. Next token latency across 6B to 13B models on BF16 precision†

Figure 2. Next token latency across 6B to13B models on WOQ int8 precision†
Figures 1 and 2 show the next token latency across typical 6B to 13B LLM models with BF16 and WOQ int8 precisions. We can find that nearly all the configurations can be done within 100 ms, which is a typical reading speed, and 7B or less models can cut the latency half to fewer than 50 ms. Specifically, WOQ int8 precision, which shows much better performance than BF16 as expected, pushes the latency to approximately 30 ms for 7B or fewer for LLM models.
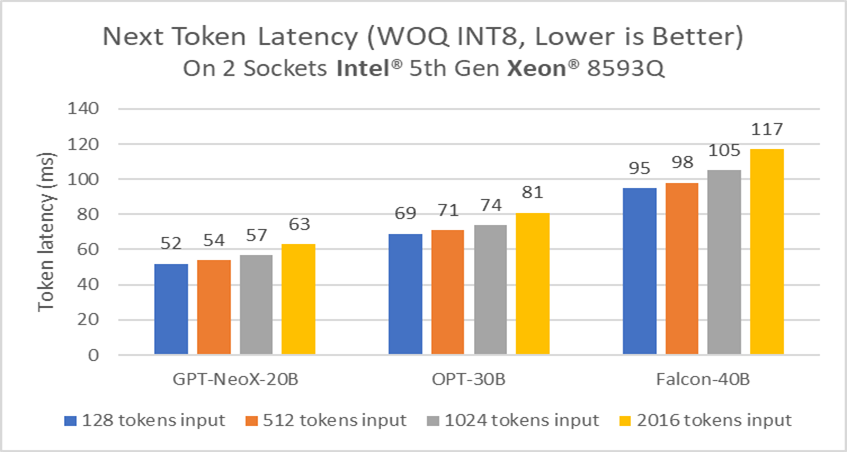
Figure 3: Next token latency across 20B to 40B models on WOQ int8 precision†
Figure 3 shows the next token latency across typical 20B to 40B LLM models with WOQ int8 precision based on two Intel Xeon CPUs. We find that even Falcon-40B can reach up to about 100 ms latency under a 1 K input token length, and GPT-NeoX-20B can be close to 50 ms under 1K input token length.
Summary
With an optimized software stack built with Intel Extension for PyTorch, we can get pretty good LLM inference performance on typical Intel Xeon platforms using hardware accelerators like Intel AVX-512, VNNI, and Intel AMX. To adopt these optimizations and directly improve the performance for LLM models by a broader community, we are upstreaming these optimizations into PyTorch and related ecosystem projects.
We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow. Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel® AI software portfolio to help you prepare, build, deploy, and scale your AI solutions.
† Performance benchmarking configuration: Intel® Xeon® Platinum 8593Q 2-socket system, 128 cores, 256 threads, Intel® Hyper-Threading Technology on, turbo boost on, non-uniform memory access (NUMA) nodes: 4, total memory 1024 GB (16 x 64 GB DDR5 5600 MT/s), microcode 0xa10001c0, Red Hat* Enterprise Linux* v9.3 (Plow), 6.2.0-emr.bkc.6.2.13.3.43.x86_64, GNU Compiler Collection (GCC)* v12.3, PyTorch v2.2.0, Intel Extension for PyTorch v2.2.0, DeepSpeed v0.13.0; Model: Llama2 7B and Llama2 13B; Token Length: 128, 512, 1024, 2016 (in), 32 (out); Tested on 1 socket, BS=1, Beam=4, Precision: BF16 and WOQ int8. Test by Intel as of March 8, 2024.
PyTorch* Optimizations from Intel
Intel is one of the largest contributors to PyTorch*, providing regular upstream optimizations to the PyTorch deep learning framework that provide superior performance on Intel® architectures. The AI Tools includes the latest binary version of PyTorch tested to work with the rest of the kit, along with Intel® Extension for PyTorch*, which adds the newest Intel optimizations and usability features.
You May Also Like Content
Related Resources
Intel AI Developer Tools and Resources
oneAPI Unified Programming Model
Related Documentation