Story at a Glance
- Intel® oneAPI Math Kernel Library (oneMKL) is highly optimized, flexible, and the most-used1 math library for Intel® architectures. It is a future-proof solution to speed up the development of applications involving numerical computations across a wide range of fields, including finance, advanced data analytics, gaming simulations, science, and engineering.
- Its extensive collection of math functions include linear algebra and sparse linear algebra functions, fast fourier transforms, random-number generator functions, data fitting, vector math, and summary statistics.
- oneMKL is an enhanced version of Intel® MKL; its expanded support comprehends GPU offload and SYCL.
- By optimizing math processing routines, oneMKL yields enhanced application performance on the latest and future generations of Intel® CPUs, GPUs, and other accelerators.
Intel oneAPI Math Kernel Library (oneMKL) is the next-generation of Intel MKL, expanded and enhanced to support numerical computing across CPUs, yes, but also GPUs, FPGAs, and other accelerators that are now part and parcel of the heterogeneous computing environment.
This blog will give you a quick overview of the math library to better help you determine whether it’s the right choice for you and/or if you should upgrade from conventional Intel MKL.
Let’s get started.
Why oneMKL?
oneMKL is an extensive collection of math functions that cover a variety of applications ranging from simple ones, such as solving linear equations and linear algebra, to complex ones, such as data fitting and summary statistics.
It serves as a common medium through which you can apply several scientific computing functions such as dense and sparse Basic Linear Algebra Subprograms (BLAS), Linear Algebra Package (LAPLACK), random number generation (RNG), vector math, and fast Fourier transforms (FFT), all following uniform API conventions. All of these are provided in C and Fortran interfaces, in addition to GPU offload and SYCL* support.
Additionally, oneMKL helps you accelerate Python* computations (NumPy* and SciPy*) when used with Intel® Distribution for Python.
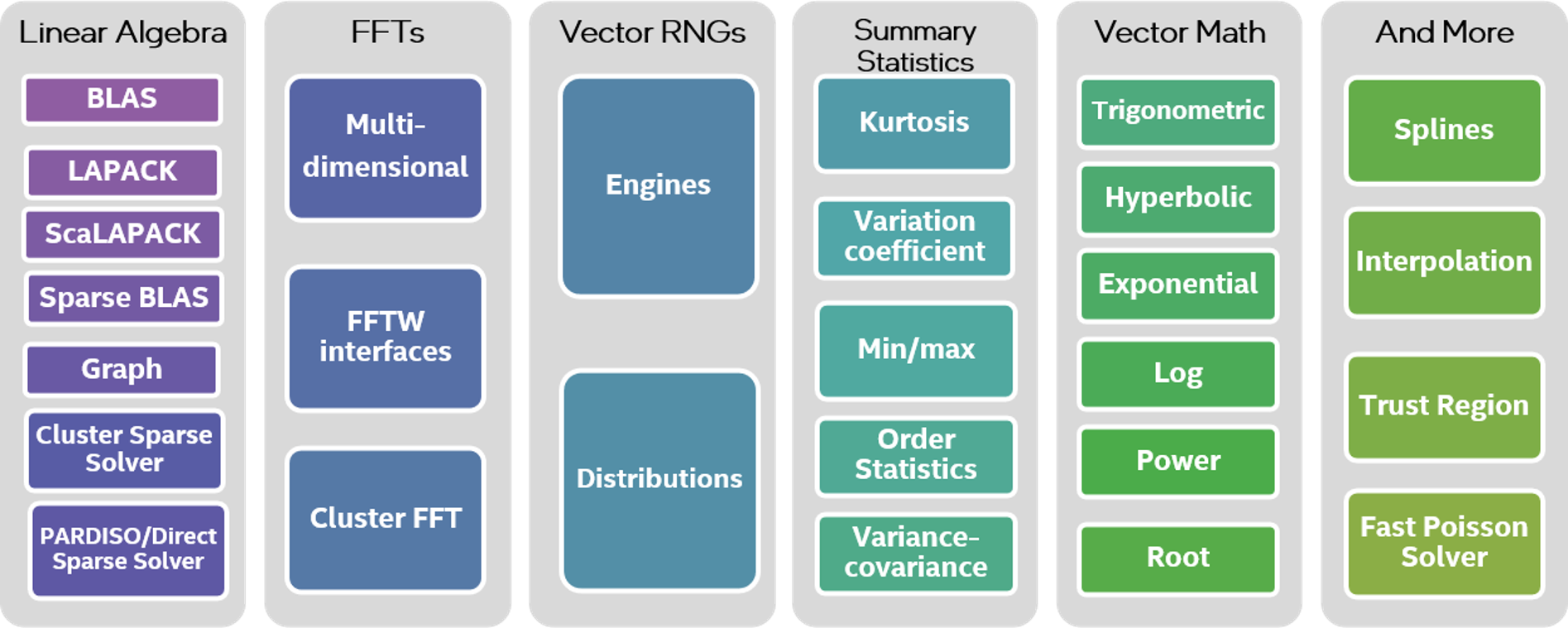
oneMKL – An Advancement of Intel® MKL
oneMKL is an enhanced version of the conventional Intel® MKL. Its expanded support for GPU offload and SYCL distinguishes it from its predecessor. Let us briefly discuss these two differences.
oneMKL GPU Offload Support
oneMKL supports GPU offload of computations using both OpenMP* as well as SYCL. It can thus leverage parallel-execution kernels of GPU architectures with its major functionalities directly enabled for Intel GPU offload.
oneMKL follows the General Purpose GPU (GPGPU) offload model implemented as part of the Intel® Graphics Compute Runtime for oneAPI Level Zero and OpenCL™ Driver. The basic execution model looks as follows, where the host CPU is connected to one or more compute devices, each of which contains multiple GPU Compute Engines (CE) (also known as Xe Vector Engines (XVE) or Execution Units (EU)).

→ Read about the implementation details of the oneMKL GPU offload model here.
oneMKL SYCL API
The SYCL API component of oneMKL is a part of oneAPI, an open, cross-industry, standards-based, unified, multi-architecture framework. (SYCL from the Khronos Group* incorporates the SYCL spec + language extensions developed using an open community process.) Hence, you can get its benefits on diverse computational devices such as CPUs, GPUs, FPGAs, and other accelerators. The functionalities provided by the SYCL API have been categorized into several domains, each with its own namespace and relevant code samples available at the oneAPI GitHub repository.
- Dense Linear Algebra
- Sparse Linear Algebra
- Discrete Fourier Transforms
- Random Number Generators
- Summary Statistics
- Vector Math
→ Learn more about the oneMKL SYCL API through oneAPI GitHub Repository and Developer Reference Guide.
→ For a quick demo on setting up an SYCL queue and making a BLAS function call using oneMKL SYCL API, check out the webinar at [00:30:13].
One of the most important aspects that SYCL API can assist you with is the migration of CUDA* math library calls to oneMKL function calls. This is in addition to the domains mentioned above.
So, let’s talk about that.
CUDA-to-SYCL Migration with oneMKL SYCL API
Two automated migration tools can be used to easily migrate CUDA codes to C++ with SYCL:
- Intel® DPC++ Compatibility Tool (DPC++ is the oneAPI implementation of SYCL)
- SYCLomatic (the open-source version of the Compatibility Tool)
These tools automatically replace CUDA math library calls with oneMKL SYCL API functions. CUDA code returns the standard set of error codes. However, given that SYCL is an extension of standard C++, the oneMKL SYCL API uses C++ exception-handling mechanisms for its error messaging.
With the migrated SYCL code, you achieve true portability in the sense that your code can now be executed across heterogeneous architectures and multi-vendor devices.
→ Visit this link to learn about code migration with oneMKL SYCL API.
→ Here’s the CUDA to C++ with SYCL Migration page.
oneMKL Support for the Latest Hardware
You can take advantage of oneMKL functionalities and optimizations on state-of-the-art architectures as well as future generations of hardware. Here are some highlights of how oneMKL lets you utilize the complete potential of your hardware configuration:
- It supports Intel® Advanced Matrix Extensions (Intel® AMX) for optimized bfloat16 and int8 data types, and Intel® Advanced Vector Extensions 512 (Intel® AVX-512) float16 data type for the 4th Gen Intel® Xeon® Scalable Processors.
- It provides matrix multiply optimizations such as Single Precision General Matrix Multiplication (SGEMM), Double Precision General Matrix Multiplication (DGEMM), RNG functions, and much more, on next generation CPUs and GPUs.
- It supports Intel® Xe Matrix Extensions (Intel® XMX) for several optimizations and features on the Intel® Data Center GPU Max Series.
- It leverages the hardware capabilities of Intel® Xeon® processors and Intel® Data Center GPUs for memory-bound dense and sparse linear algebra, vector math, FFT, spline computations, and several other scientific calculations.
Watch the Webinar
If this has piqued your interest, take a deeper dive into the features, capabilities, and advantages of oneMKL in this on-demand webinar where the expert speakers discuss:
- How oneMKL supports and takes full advantage of the latest Intel® CPUs (particularly the 4th Gen Intel® Xeon® Scalable Processors) and GPUs (with practical illustrations).
- What distinguishes oneMKL from the traditional Intel® Math Kernel Library (MKL).
- Important features of oneMKL
- How oneMKL supports heterogeneous compute with OpenMP* and SYCL, and
- Demonstration of mapping CUDA* math library calls to oneMKL
Watch [59:07]
More Terminology, More Context
Below is a slight unpacking of terminology that may additionally help you connect the dots on oneMKL and how it fits into the heterogeneous-compute environment.
- The oneAPI Specification for oneMKL defines the C++ with SYCL interfaces for performance math library functions. The oneMKL specification can evolve faster and more frequently than implementations of the specification.
- The oneAPI Math Kernel Library (oneMKL) Interfaces project is an open-source implementation of the specification. The project aims to demonstrate how the SYCL interfaces documented in the oneMKL specification can be implemented for any math library and work for any target hardware. While the implementation provided here may not yet be the full implementation of the specification, the goal is to build it out over time. We encourage the community to contribute to this project and help to extend support to multiple hardware targets and other math libraries.
- oneMKL is the Intel product implementation of the specification (having C++ with SYCL interfaces) as well as similar functionality with C and Fortran interfaces. It is highly optimized for Intel® CPU and Intel® GPU hardware.
What’s Next?
Get started with oneMKL today and accelerate your numerical computations as never before! Avail yourself of oneMKL’s advanced capabilities to accelerate math processing routines and enhance application performance with reduced development time on modern as well as upcoming Intel® architectures.
While you use the current oneMKL functionalities and optimizations, remember that oneMKL is evolving fast! We attempt to keep adding various optimizations and support for advanced math features compatible with the latest Intel® hardware.
We also encourage you to check out the AI, HPC, and Rendering tools in Intel’s oneAPI-powered software portfolio.
Additional Resources
Here are some useful resources for you to dig into oneMKL:
- oneMKL Landing Page
- oneMKL Documentation
- oneAPI Specification Documentation for oneMKL
- Intel® oneAPI Base Toolkit
- oneMKL Interfaces: GitHub Repository
- oneMKL Code Samples on GitHub
- Webinar: Why oneMKL? Accelerate Math Computations on the Latest Hardware
- How to Move from CUDA* Math Library Calls to oneMKL
- CUDA-to-SYCL Migration Tools: SYCLomatic and Intel® DPC++ Compatibility Tool
- Codeplay* oneAPI for NVIDIA® GPUs
Get The Software
You can install oneMKL as a part of the Intel® oneAPI Base Toolkit or download its stand-alone version, both for free!