Overview
As an open source distributed event streaming platform, Apache Kafka* is often used for a variety of workloads including being a publish-subscribe, real-time messaging system to process data in a resilient, fault tolerant, and horizontally scalable way.
Because Kafka is a high-volume and low-latency message broker, Intel needed a fast (but still secure) encryption algorithm capable of encrypting an arbitrary amount of data. The Kafka Producer API must encrypt the messages before pushing them over the network into the Kafka Consumer API, which then needs to decrypt them upon retrieval. Kafka supports the encryptions using Transport Layer Security (TLS). Enabling TLS causes performance impacts due to encryption overhead. Kafka does not directly support any form of encryption-at-rest for data stored at a broker.
This guide explores several use cases to show Kafka workload optimizations on 3rd gen Intel® Xeon® Scalable processors. These use cases accelerate the encryption process through hardware across different compression methods against different Java* Development Kit (JDK) versions.
Intel® Crypto Acceleration for Kafka Encryption
New 3rd gen Intel Xeon Scalable processors introduce enhanced cryptographic operations, called Intel® Crypto Acceleration, which contributes to improved performance for Kafka workloads where encryption and decryption are enabled. The new crypto instructions set supports implementation of stronger encryption protocols without compromising performance by reducing compute cycles allocated for cryptography processing.
As high volumes of data are encrypted, symmetric key encryption is the natural choice for efficiently ensuring the confidentiality of stored Kafka type messages. The Advanced Encryption Standard (AES) is an efficient symmetric encryption algorithm, and Intel® AES New Instructions (Intel® AES-NI) are supported by 3rd gen Intel Xeon Scalable processors (formerly code named Ice Lake) with Vector Advanced Encryption Standard (VAES) for faster processing of cryptographic algorithms, constant time encryption, and resilience to certain side-channel attacks. The new Intel AES-NI instruction set is composed of six new instructions that perform several compute-intensive parts of the AES algorithm. These instructions can run using significantly fewer clock cycles than a software solution.
Galois/Counter Mode (GCM) is an authenticated encryption mode for block ciphers. AES with GCM is not only efficient and secure, but hardware implementations can achieve high speeds with low cost and low latency because the mode can be pipelined. Applications that require high-data throughput can benefit from these high-speed implementations. AES with GCM is optimized with the newest JDK software–for example OpenJDK* 11.0.11 and later, which leverages the power of VAES and VPCLMULQDQ instructions from Intel® Advanced Vector Extensions 512 (Intel® AVX-512). This may accelerate the Kafka streaming performance while reducing the CPU overhead due to encryptions. TLS cryptography protocols use AES with GCM cipher suites to optimize Kafka broker throughput performance and reducing encryption overhead without impacting the latency service level agreement (SLA).
Intel has also developed a compression plug-in solution as an extension of certain compression algorithms, improving throughput, latency, and compression ratios for a Kafka workload.
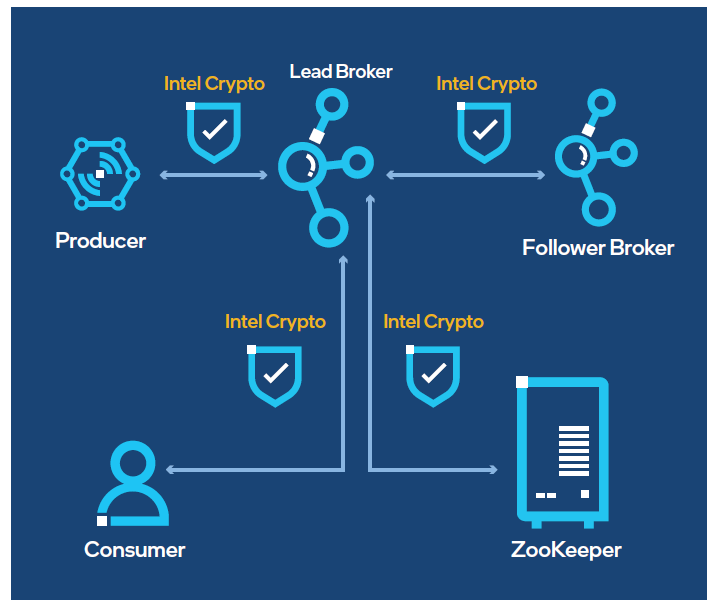
Figure 1. Kafka encryption with Intel® Crypto Acceleration when data is in motion
Optimize Kafka Streaming
Optimizing the Kafka streaming performance is a key challenge for any enterprise for better SLA, increased total cost of ownership (TCO), better user experience, and satisfying the compliance requirements.
Following are several ways to achieve better Kafka performance on Intel platforms:
- Switch to the latest generation Intel Xeon processor to take advantage of advanced crypto acceleration capabilities.
- Scale to choose higher vCPU Intel-based instances.
- Use optimized JDK versions to benefit from crypto upstream features.
- Use best compression methods based on use cases.
- Use OpenSSL TLS or advanced JDK SSL features.
- Use libraries optimized by Intel for better compressions based on use cases.
Performance Benchmark Test
For capacity planning tied to SLA requirements, it is important to run the benchmark testing to achieve the optimized throughput and best user experience as different environments, workloads, and use cases have specific needs.
The following benchmark test cases were performed across different generations of Intel Xeon Scalable processors, JDK versions, compression methods, and encryption scenarios in Amazon Elastic Compute Cloud (Amazon EC2)* instances. For test cases run on specific Amazon EC2 instances and related hardware configurations, Kafka software, and workload configurations, refer to Appendix A.
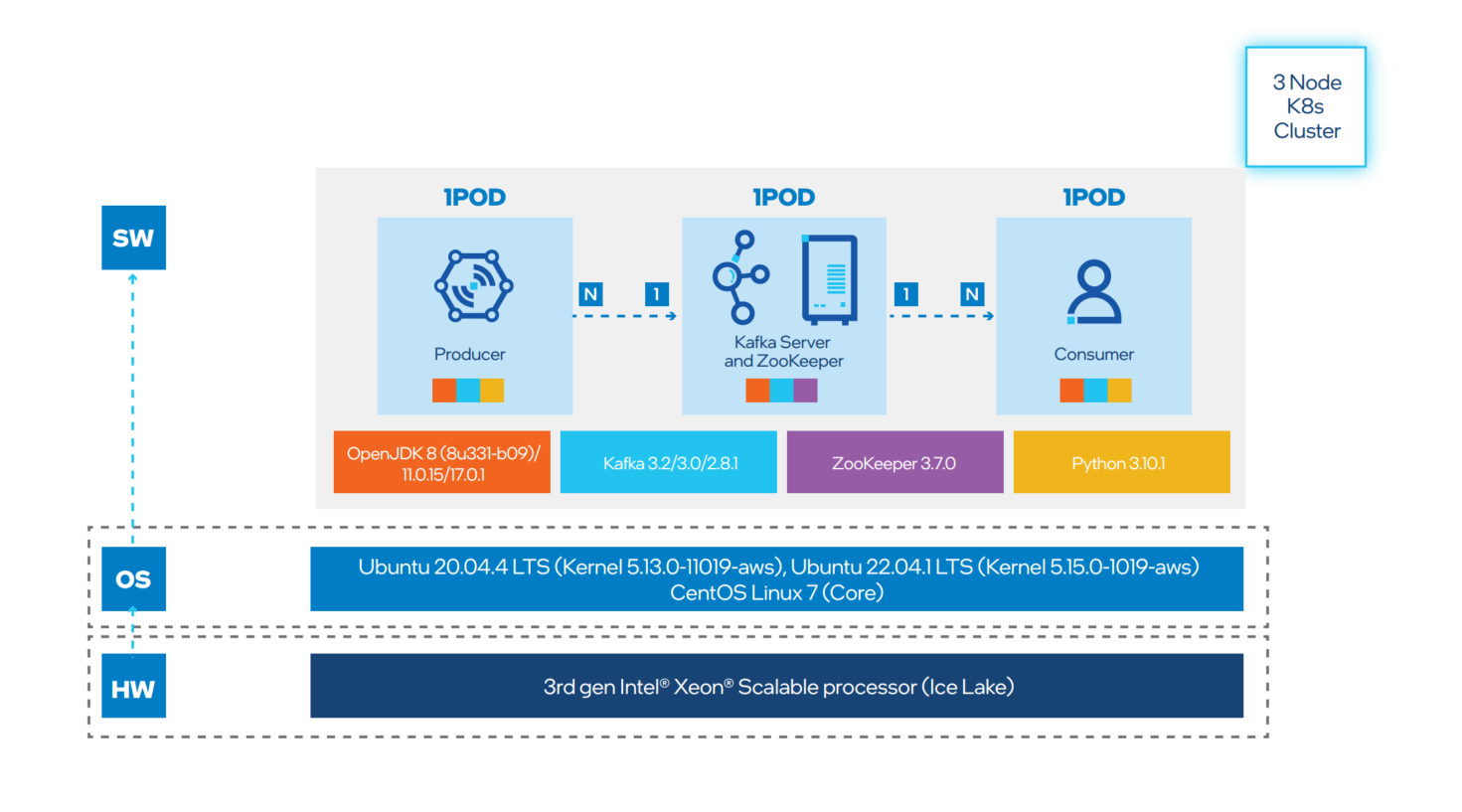
Workload Architecture
This workload measures Kafka's streaming performance by using the built-in standard application tool. Currently, the test case measures the Producer API and Consumer API performance. Intel has used the following diagram as a Kafka benchmarking framework for testing. The workload ran using standard embedded scripts kafka-producer-perf-test.sh and kafka-consumer-perf-test.sh for performance harness.

Process and Methodology
The following steps show the benchmark process that was used to run the test:
- Perform Kafka Producer API–publish millions of messages per thread to Broker Kafka server.
- Perform Kafka Consumer API–read millions of subscribed messages per thread.
The workload contains three Docker* images:
- Producer (generate and send messages to Kafka and ZooKeeper server)
- Kafka-ZooKeeper-server (receive messages from Producer and send messages to Consumer)
- Consumer (get messages from Kafka and ZooKeeper server)
Three Kubernetes* worker nodes were used for this test case to host Producer, Broker, and Consumer containers in PODs.
Each POD is assigned to each Kubernetes node using anti-affinity setup. Producer has one POD, Broker has one POD, and Consumer has one POD. Testing is done with Replication factor 1 with one partition.
Median value of three runs taken for max throughput and p99 latency to avoid outliers.
Measure the p99 latency and aggregate transmitted throughput from Producer to Broker.
Key Performance Indicators (KPI)
This benchmark result focuses on two KPIs:
- Max throughput (in MB/second), which measures the sum of Producer messages that arrive to Broker within a specific amount of time.
- Producer P99 Latency—the time it takes for a record produced to Kafka to be fetched by the Consumer. P99 latency is standard tail latency measures how much end-to-end latency 99th percentile of time.
Software Stack
Any changes in configurations have been mentioned in the individual optimizations area to override:
1. Intel Xeon Processor Gen-to-Gen Performance Comparison Using Kafka
Both throughput and latency KPI depend on the choice of hardware or cloud provider. So, it is important to understand what hardware acceleration and software can help to achieve your specific latency goals in your unique environment.
In the following test, Kafka performance comparison was done between 3rd gen Intel Xeon Scalable processor instances and 2nd gen Intel Xeon Scalable processor instances in Amazon EC2 m5, m6i, and i4i type instances. It shows the performance difference across storage, compute, and memory optimized Amazon EC2 instances. In the following sections, any changes made to the baseline configurations are called out.
1.1. Intel Xeon Processor Gen-to-Gen Comparison Using Amazon EC2* m6i (3rd gen) versus m5 (2nd gen) – Encryption OFF
The performance test is done on a 2nd gen Intel Xeon Scalable processor m5.4xlarge (16 vCPU) versus 3rd gen Intel Xeon Scalable processor-based m6i.4xlarge (16 vCPU) in OpenJDK 11.0.15 version while Kafka encryption configuration is turned off.
Performance Summary
3rd gen Intel Xeon Scalable processor instances (m6i) show 30% throughput improvement versus older generation processors (m5). For throughput, higher is better; for P99 latency, lower is better. For configuration details, see table 1.1 and table 2.1 in Appendix A.
1.2. Intel Xeon Processor Gen-to-Gen Comparison Using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) – Encryption ON
The performance test is done on a 2nd gen Intel Xeon Scalable processor m5.4xlarge (16 vCPU) versus 3rd gen Intel Xeon Scalable processor-based m6i.4xlarge (16 vCPU) in OpenJDK 11.0.15 version while Kafka encryption configuration is turned on.
Performance Summary
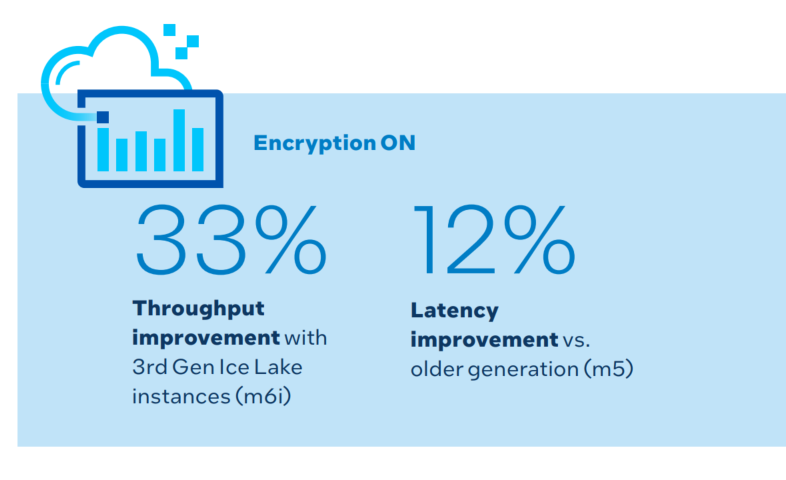
3rd gen Intel Xeon Scalable processor instances (m6i) show 33% throughput improvement and 12% latency improvement versus older generations (m5). Improvements are because of AES crypto instructions for 3rd gen. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.1 and 2.1 in Appendix A.
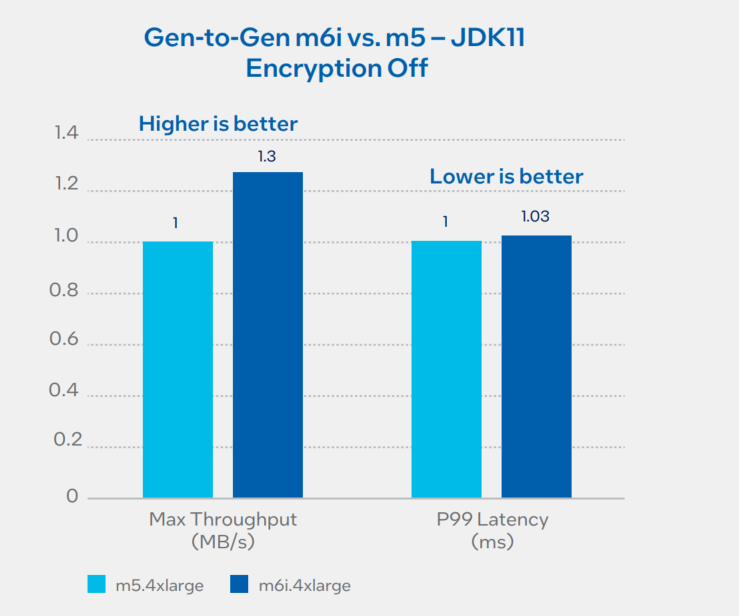
Figure 2. Intel Xeon processor gen-2-gen comparison using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) – encryption off
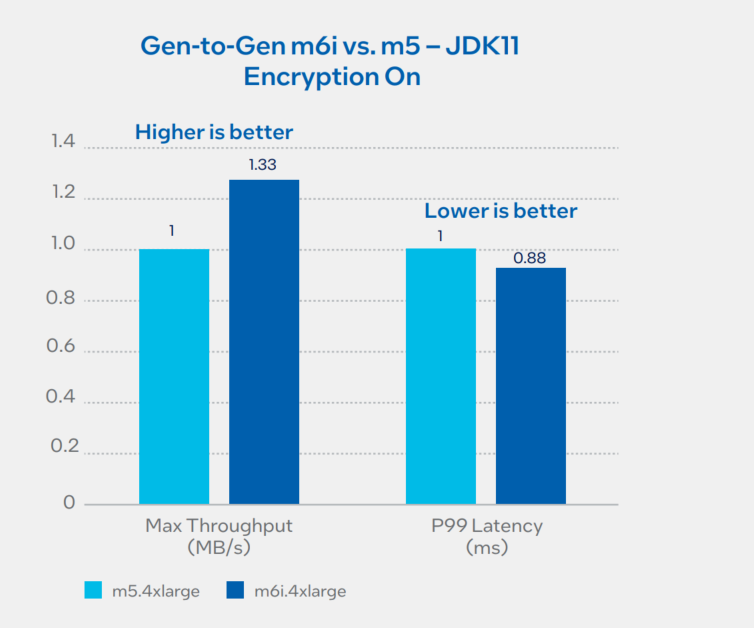
Figure 3. Intel Xeon processor gen-to-gen comparison using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) – encryption on
1.3. Intel Xeon Processor Gen-to-Gen Comparison Using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) with Compression
The performance test is done on a 2nd gen Intel Xeon Scalable processor m5.4xl (16 vCPU) versus 3rd gen Intel Xeon Scalable processor m6i.4xl (16 vCPU) in OpenJDK 11.0.15 version.
The following images show the optimization on throughput and latency across two different compression methods: Zstd and LZ4 compression type algorithms.
Performance Summary
Amazon EC2 m6i.4xlarge instance shows 35% throughput improvement in Zstd and 30% throughput improvement in LZ4 against Amazon EC2 m5.4xlarge instance.
Amazon EC2 m6i.4xlarge instance shows 12% latency improvement in Zstd and 36% latency improvement in LZ4 against Amazon EC2 m5.4xlarge instance. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.1 and 2.1 in Appendix A.
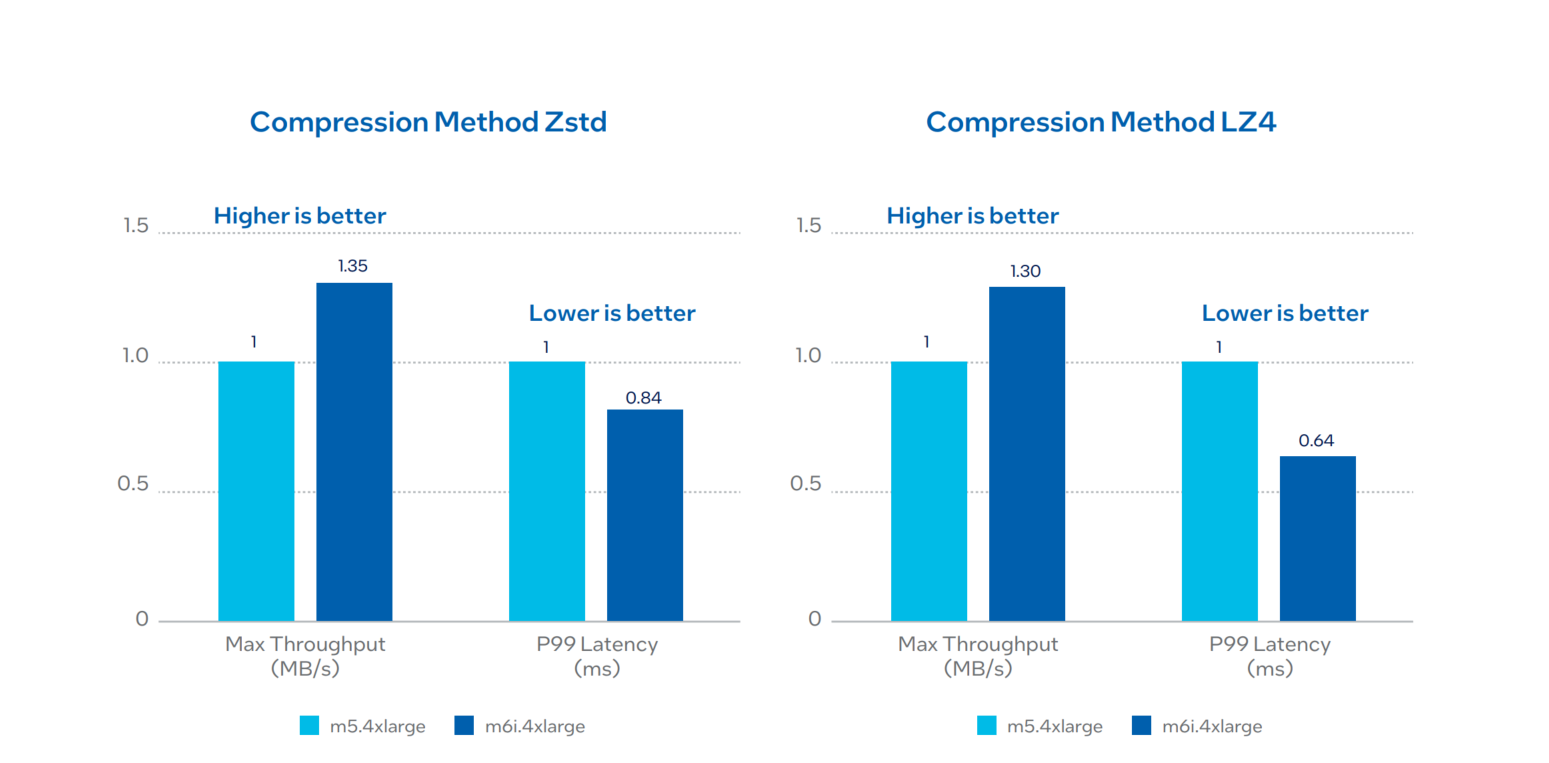
Figure 4. Intel Xeon processor gen-to-gen comparison using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) Zstd or LZ4 compression
2. Kafka Performance–CPU Scaling Using Amazon EC2 i4i
Kafka performance comparison was done across multiple 3rd gen Intel Xeon Scalable processor instances in Amazon EC2 i4i instances. In the following test, the number of Kafka Producers, Brokers, Consumers, and total partitions also increased linearly by 4x.
For example, the i4i.4xlarge instance with 16 vCPU has 32 Brokers, Consumers, Producers, and partitions.
2.1. Amazon EC2 i4i Instances (LZ4 compression)
The performance test is done on Intel Xeon Scalable processors (formerly code named Ice Lake) i4i.xlarge(4vCPU), i4i.2xlarge(8vCPU), i4i.4xlarge(16vCPU) in OpenJDK 11.0.15 version.
The following images show the optimization on throughput and latency for compression methods LZ4.
Performance Summary
3rd gen Intel Xeon Scalable processor Amazon EC2 i4i instance CPUs scaling shows linear percent maximum throughput improvement with LZ4 compression. Brokers, consumers, and partitions also scaled along with instances. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.2 and 2.2 in Appendix A.

Figure 5. Amazon EC2 i4i Instances scaling (LZ4 compression).
3. Kafka Encryption Performance across Java* Versions
The transparent end-to-end encryption in Kafka done via a Java serializer and deserializer implementation uses the Intel AVX-512 instruction set. 3rd gen Intel Xeon Scalable processor instructions support the operations of crypto algorithms for simultaneous running and a method allowing parallel processing of multiple independent data buffers. This gives the crypto acceleration boost of Kafka stream processing performance.
The Intel team has upstreamed several crypto instructions set supports in OpenJDK version 11.0.11+ through the open source Java community. This document provides the details on Kafka performance comparison across different Java versions.
3.1. Kafka Throughput in Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) across JDK and Encryptions
Kafka performance comparison was done across 3rd gen Intel Xeon Scalable processors in Amazon EC2 m6i.4xlarge and m5.4xlarge instances across JDK 8 versus JDK 11 versions for different encryption settings. JDK 11 and higher versions provide the Intel® Crypto Acceleration optimizations against no crypto support for JDK8, hence attributed to significant performance improvements.
Performance Summary
3rd gen Intel Xeon Scalable processors on an Amazon EC2 instance show approximately 25% to 30% throughput improvement against 2nd gen Intel Xeon Scalable processors. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.1 and 2.1 in Appendix A.
3.2. Kafka Throughput and Latency on Amazon EC2 i4i.4xlarge across JDK
Kafka performance comparison done across 3rd gen Intel Xeon Scalable processor in Amazon EC2 i4i.4xlarge instances across JDK 8 versus JDK 11 versions for compression Zstd while Encryptions are turned on. JDK 11 and higher provides the Intel Crypto acceleration against no Crypto support for JDK 8 hence attributed to significant performance improvements.
Performance Summary
3rd gen Intel Xeon Scalable Processors with Amazon EC2 instance i4i.4xlarge shows 26% throughput and 39% latency improvement JDK 8 to JDK 11 with encryption set to ON. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.1 and 2.1 in Appendix A.
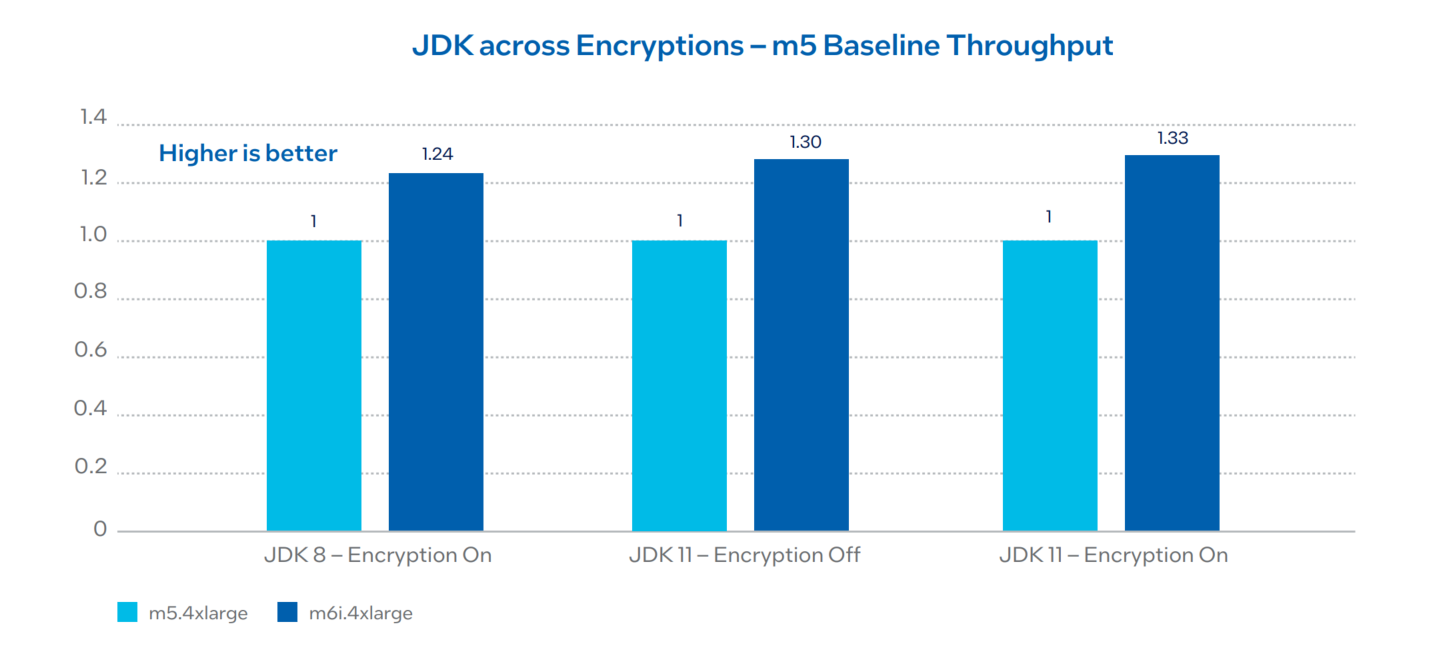
Figure 6. Amazon EC2 m6i 3rd gen versus m5 2nd gen - no compression
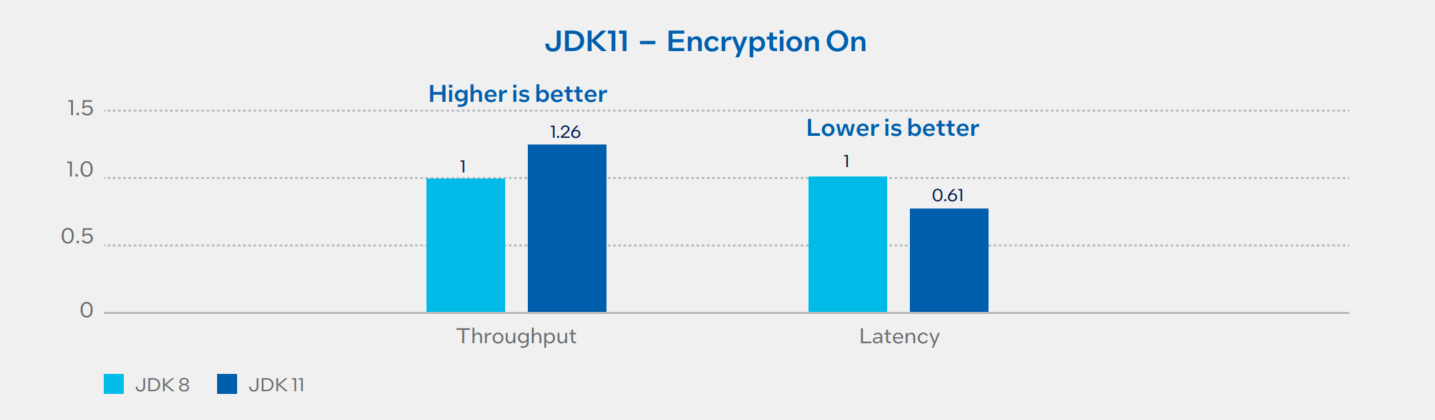
Figure 7. Amazon EC2 i4i.4xlarge latency and throughput for JDK 8 vs. JDK 11
4. Kafka Compression in Amazon EC2 Instances
Compression has a huge significance in Kafka workload performance. By default, Kafka messages are not compressed.
Compressing data batches improves throughput and reduces the load on physical storage (with replication it would be even more), plus data transmitted over the network is reduced. Message compression adds latency in the producer (CPU time spent compressing the messages), but it is not always suitable for low-latency applications where the cost of compression or decompression has zero tolerance.
From producers to broker throughput with different compression algorithms inhibits significant difference versus no compression.
The following graph outlines throughput and latency impact in compressed and noncompressed data. It also shows how compression varies across different algorithms and the performance impact. Intel has also developed a plug-in solution on top of Gzip compression to improve latency for maximum throughput.
4.1. Kafka Compression Performance Comparison Using Amazon EC2 m6i.4xlarge
Performance on Kafka data across different compression algorithms is shown in the following chart. All tests on m6i.4xlarge have been done with 32 (double the vCPUs) producers, brokers, consumers, and partitions.
Performance Summary
P99 Latency is better when Gzip compression is applied comparing other compression methods. Excluding Gzip, other compression methods are showing better throughput. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.1 and 2.1 in Appendix A.

Figure 8. Amazon EC2 m6i.4xlarge across compression types - encryption off
4.2. Kafka Compression Optimizations on Intel Libraries
Kafka compression process helps to achieve two things: Reducing network bandwidth usage and saving disk space on Kafka Brokers. However, the tradeoff is dispatch latency because of higher CPU use due to compression. Gzip is known to have the highest compression ratios with high CPU use, but the slowest compression speed (latency). In certain use cases, Gzip is a more desirable cost optimize solution against LZ4, Zstd, or Snappy.
Intel® Integrated Performance Primitives (Intel® IPP) multithreaded software library with Zlib interface improve the default Gzip latency. And the Intel® Intelligent Storage Acceleration library (Intel® ISA-L) optimizes the storage throughput with functions for RAID, erasure code, cyclic redundancy check (CRC) functions, cryptographic hash, encryption, and compression. The following graph presents the Intel solution over native Java for Gzip to show performance boost.
Performance Summary
Intel ISA-L improves throughput by 1.47x and Intel IPP improves throughput by 1.15x comparing Java native Gzip.. Intel ISA-L improves latency by 34% and Intel IPP improves latency by 8% comparing Java native gzip. For throughput, higher is better; for P99 latency, lower is better. For configuration details, see Table 1.3 and 2.4 in Appendix A.
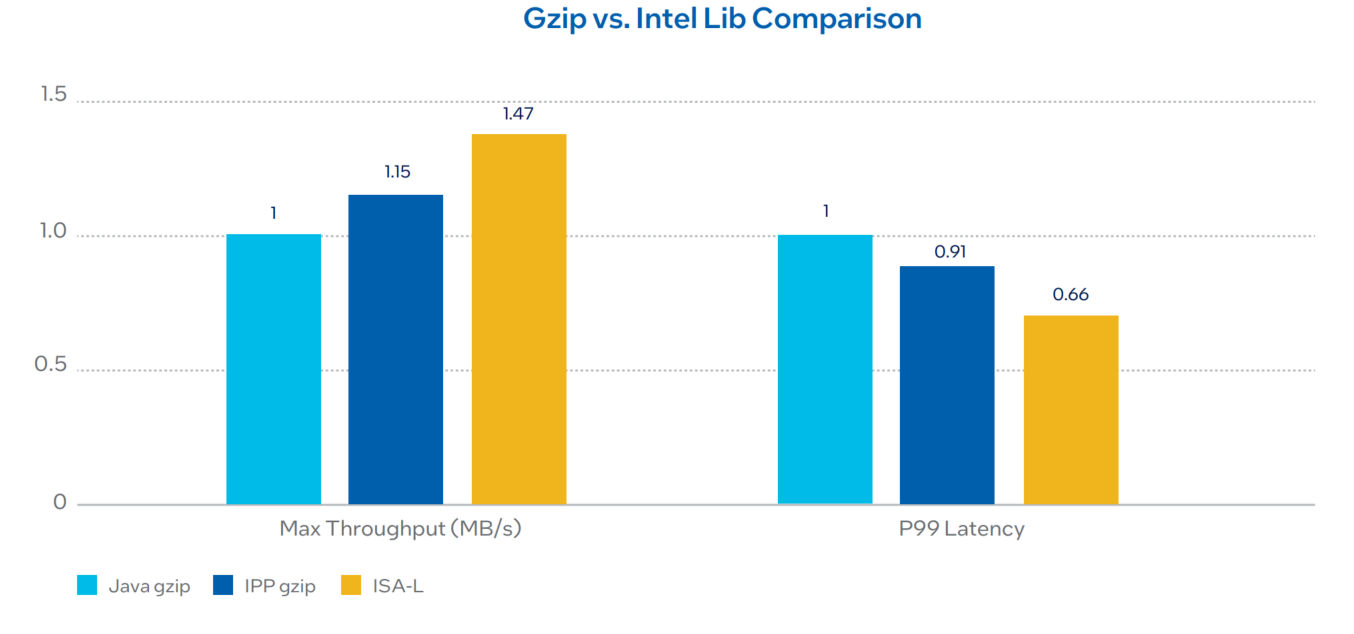
Figure 9. 3rd gen Intel Xeon Scalable processor with Intel® Advanced Encryption Standard New Instructions set from the Intel AVX-512 instruction family.
5. Intel's Contributions on Open Source Optimization
OpenJDK—Upstream and Backport Support for VAES Crypto
The Intel team has contributed to the OpenJDK community so that Java can take advantage of performance acceleration crypto features support from Intel AVX-512 instruction set in 3rd gen Intel Xeon Scalable processors.
The Intel team also backported several crypto/hash acceleration support features from future JDK versions (JDK 12+) to JDK 11 LTS and JDK 11.0.10., which differentiates the overall Java performance in JDK 11 to boost performance for numerous Java dependent workloads including Kafka. This enhancement is contributed by Intel and sponsored by the hot spot compiler team.
Kafka Community–TLS Regression
Kafka supports TLS for both encryption and authentication. TLS cryptographic protocol uses AES-GCM, which can be CPU intensive. If a server has negotiated TLS 1.3, it must terminate the connection with an “unexpected message” alert. TLS 1.3 on Kafka 2.7 doesn’t support renegotiation creating intermittent disconnections in brokers before read/write is completed impacting p99 latency.
While working with a customer, Intel engineers found the issue for JDK 11 and TLS 1.3 and suggested a fix, which was applied the fix to resolve the issue, and has been requested to upstream to the Kafka community.
OpenSSL*: SSL & TLS with Several Cryptographic Functions Including AES
The OpenSSL* project provides an open source implementation of the SSL/TLS protocols and is a commonly deployed library for SSL/TLS worldwide, which can be used in Kafka clients and broker communication. Confluent Kafka broadly adopted OpenSSL for TLS. OpenSSL implementation can have better performance comparing to JDK SSL.
Asynchronous OpenSSL is a nonblocking approach that supports a parallel-processing model at the cryptographic level for SSL/TLS protocols, which in turn allows for other types of optimizations. This capability allows cryptographic transformations to be processed on dedicated hardware engines or on separate logical cores. Intel® QuickAssist Technology Engine for OpenSSL* (Intel® QAT Engine for OpenSSL*) can boost the overall TLS performance.
Intel QAT Engine for OpenSSL supports acceleration for both hardware and optimized software based on vectorized instructions.
Intel® Intelligent Storage Acceleration Library (Intel® ISA-L)
Intel ISA-L provides tools to minimize disk space use and maximize storage throughput, security, and resilience. Intel ISA-L is a collection of optimized low-level functions targeting storage applications. Intel ISA-L helps improve compression and throughput performance and reduce latency for a storage application with erasure coding that uses Reed-Solomon error correction. Intel ISA-L proves increased Gzip compression performance (better throughput) using an Intel implementation called IGZIP. Intel ISA-L crypto accelerates multibuffer cryptography hashes providing better throughput using a vector SIMD instruction set and improved AES ciphers. This can optimize Kafka performance.
Intel® Integrated Performance Primitives (Intel® IPP Cryptography)
Intel IPP Cryptography is a secure, fast, and lightweight library of building blocks for cryptography, highly optimized for various Intel CPUs that includes 3rd gen Intel Xeon Scalable processor. It optimizes hardware cryptography instructions support using several Intel® Streaming SIMD Extensions versions and various Intel AVX instructions sets. Intel IPP is a multithreaded software library (part of Intel® oneAPI toolkits), which shows better Kafka performance using Intel IPP with Gzip, the Intel patched version of a native Java for Gzip solution.
6. Intel's Continued Innovation to Optimize Kafka
- Better Kafka performance using JDK 18 optimized CRC32, interleaved GCM functions on Intel hardware.
- New 4th Gen Intel Xeon Scalable processors with Intel® QuickAssist Technology (Intel® QAT) accelerator engine improves crypto acceleration and data compression and decompression while offloading the CPU.
- JDK 18 improved Java array copy/clear to use 512-bit wide vector width instruction for 4th gen Intel Xeon Scalable processors.
- A Granulate* application and workload performance optimization solution from Intel saves CPU use without any code changes. It can reduce costs by up to 60% while saving CPU up to 25%-40%.
Appendix A–Configurations
The following tables show the full configuration details for the test environment, platforms, and software.
Table 1.1 Hardware configuration used for:
- Figures 2 and 3—Intel Xeon processor gen-2-gen comparison using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen)–encryption off and on
- Figure 4—Intel Xeon Processor gen-to-gen comparison using Amazon EC2 m6i (3rd gen) versus m5 (2nd gen) Zstd or LZ4 compression
- Figure 6—Amazon EC2 m6i 3rd gen versus m5 2nd gen—no compression
- Figure 8—Amazon EC2 m6i.4xlarge across compression types—encryption off
.
| m6i.4xlarge | m5.4xlarge | |
| Manufacturer | Amazon EC2 | Amazon EC2 |
| Product Name | m6i.4xlarge | m5.4xlarge |
| BIOS Version | 1 | 1 |
| Microcode | 0xd000331 | 0x500320a |
| IRQ Balance | Enabled | Enabled |
| CPU Model | Intel Xeon Platinum 8375C CPU at 2.90 GHz | Intel Xeon Platinum processor 8259CL CPU at 2.50 GHz |
| Base Frequency | 2.9 GHz | 2.5 GHz |
| Maximum Frequency | 3.5 GHz | 3.5 GHz |
| All-Core Maximum Frequency | 3.5 GHz | 3.1 GHz |
| CPUs | 16 | 16 |
| Threads per Core | 2 | 2 |
| Cores per Socket | 8 | 8 |
| Socket | 1 | 1 |
| Non-Uniform Memory Access (NUMA) Node | 1 | 1 |
| Prefetchers | DCU HW, DCU IP, L2 HW, L2 Adj. | DCU HW, DCU IP, L2 HW, L2 Adj. |
| Turbo | Enabled | Enabled |
| Frequency | 2899 | 2.5 GHz |
| Max C-State | 9 | 9 |
| Installed Memory | 64 GB (1 x 64 GB DDR4 3200MT/s [Unknown]) | 64 GB (1 x 64 GB DDR4 2933 MT/s [Unknown]) |
| Huge Pages Size | 2048 KB | 2048 KB |
| Transparent Huge Pages | madvise | madvise |
| Automatic NUMA Balancing | Disabled | Disabled |
| NIC Summary | 1x Elastic Network Adapter (ENA) | 1x Elastic Network Adapter (ENA) |
| Drive Summary | 1 x 500 GB Amazon Elastic Block Store | 1 x 500 GB Amazon Elastic Block Store |
Table 1.2 Hardware configuration used for 3rd gen Intel Xeon Scalable processors with Amazon EC2 i4i instance CPUs.
| i4i.xlarge | i4i.2xlarge | i4i.4xlarge | |
| Manufacturer | Amazon EC2 | Amazon EC2 | Amazon EC2 |
| Product Name | i4i.xlarge | i4i.2xlarge | i4i.4xlarge |
| BIOS Version | 1 | 1 | 1 |
| Microcode | 0xd000331 | 0xd000331 | 0xd000331 |
| IRQ Balance | Enabled | Enabled | Enabled |
| CPU Model | Intel Xeon Platinum processor 8375C CPU at 2.90 GHz | Intel Xeon Platinum processor 8259CL CPU at 2.50 GHz | Intel Xeon Platinum processor 8375C CPU at 2.90 GHz |
| Base Frequency | 2.9 GHz | 2.9 GHz | 2.9 GHz |
| Maximum Frequency | 3.5 GHz | 3.5 GHz | 3.5 GHz |
| All-Core Maximum Frequency | 3.5 GHz | 3.1 GHz | 3.5 GHz |
| CPUs | 4 | 8 | 16 |
| Threads per Core | 2 | 2 | 2 |
| Cores per Socket | 2 | 4 | 8 |
| Socket | 1 | 1 | 1 |
| NUMA Node | 1 | 1 | 1 |
| Prefetchers | DCU HW, DCU IP, L2 HW, L2 Adj. | DCU HW, DCU IP, L2 HW, L2 Adj. | DCU HW, DCU IP, L2 HW, L2 Adj |
| Turbo | Enabled | Enabled | Enabled |
| Frequency | 2.9 GHz | 2.9 GHz | 2.9 Ghz |
| Max C-State | 9 | 9 | 9 |
| Installed Memory | 32 GB (1x64 GB DDR4 3200 MT/s [Unknown]) | 64 GB (641x64GB DDR4 3200 MT/s [Unknown]) | 128 GB (1x64 GB DDR4 3200 MT/s [Unknown]) |
| Huge Pages Size | 2048 KB | 2048 KB | 2048 KB |
| Transparent Huge Pages | madvise | madvise | madvise |
| Automatic NUMA Balancing | Disabled | Disabled | Disabled |
| NIC Summary | 1x Elastic Network Adapter (ENA) | 1x Elastic Network Adapter (ENA) | 1x Elastic Network Adapter (ENA) |
| Drive Summary | 1 x 500 GB Amazon Elastic Block Store | 1 x 500 GB Amazon Elastic Block Store | 1 x 500 G Amazon Elastic Block Store, 1 x 3.4 TB Amazon EC2 NVMe Instance Storage |
Table 1.3 Hardware and software configurations of the bare metal 3rd gen Intel Xeon Scalable processor with Intel ISA-L and Intel IPP.
|
Operating System |
CentOS Linux* 7 (Core) |
|
Kernel |
5.13.0+ |
|
CPU Model |
Intel Xeon Gold 6348 CPU at 2.60 GHz |
|
Sockets, Total CPU(s), NUM Count |
2, 112, 2 |
|
HT, Turbo Boost |
Included |
|
Memory |
1024 GB (32 x 32 GB DDR4 3200 MT/s [3200 MT/s]) |
|
Disk |
Nvme0n1: 3.7T |
|
Network |
loopback |
|
BIOS Version |
05.01.01 |
|
Microcode |
0xd0002a0 |
|
Version |
02.01.00.1127 |
|
Kafka |
3.0.0 |
|
Java |
JDK 11.0.15 |
|
Intel ISA-L |
2.30 |
|
IPP |
2021.4.0 |
Table 2.1 Software and workload used for:
- Figures 2 and 3—Intel Xeon processor gen-to-gen comparison using Amazon ECS m6i (3rd gen) versus m5 (2nd gen)—encryption off and on
- Figure 4—Intel Xeon processor gen-to-gen comparison using Amazon ECS m6i (3rd gen) versus m5 (2nd gen) Zstd or LZ4 compression
- Figure 6—Amazon ECS m6i 3rd gen versus m5 2nd gen—no compression
|
Attribute |
m6i.4xlarge |
m5.4xlarge |
|
OS_VER |
22.04.1 |
22.04.1 |
|
OS_IMAGE |
Ubuntu* 22.04.1 LTS |
Ubuntu 22.04.1 LTS |
|
OPENJDK_VER |
jdk-11.0.15 |
jdk-11.0.15 |
|
OPENJDK_PACKAGE |
openJDK11U-jdk_x86_linux_hotspot_11.0.15_10.tar.gz |
openJDK11U-jdk_x86_linux_hotspot_11.0.15_10.tar.gz |
|
PYTHON_VER |
Python-3.10.2 |
Python-3.10.2 |
|
PYTHON_PACKAGE |
||
|
Zookeeper |
3.7.0 |
3.7.0 |
|
ZOOKEEPER_PACKAGE |
||
|
KAFKA |
3.2 |
3.2 |
|
KAFKA_PACKAGE |
kafka_2.12-3.2.0.tgz |
kafka_2.12-3.2.0.tgz |
|
REPLICATION_FACTOR |
1 |
|
PARTITIONS |
Twice # of vCPUs1 |
|
# OF PRODUCERS |
Twice # of vCPUs |
|
# OF CONSUMERS |
Twice # of vCPUs |
|
# OF BROKERS |
Twice # of vCPUs |
|
NUM_RECORDS |
5,000,000 |
|
ENCRYPTION |
TRUE |
|
RECORD_SIZE |
1,000 |
|
COMPRESSION_TYPE |
OFF |
|
MESSAGES |
10,000,000 |
|
CONSUMER_TIMEOUT |
600,000 |
|
BATCH_SIZE |
524,288 |
|
LINGER_MS |
100 |
- A 4xlarge instance of vCPUs is 16. So, the number of producers, consumers, brokers, or partitions is 32.
Table 2.2 Software and workload used for test results from Figure 5 (Amazon EC2 i4i instances scaling LZ4 compression) and Figure 7 (Amazon EC2 i4i.4xlarge latency and throughput for JDK 8 versus JDK 11)
|
Attribute |
i4i.xlarge, i4i.2xlarge, i4i.4xlarge |
|
OS_VER |
22.04.1 |
|
OS_IMAGE |
Ubuntu 22.04.1 LTS |
|
OPENJDK_VER |
jdk-11.0.15 |
|
OPENJDK_PACKAGE |
openJDK11U-jdk_x86_linux_hotspot_11.0.15_10.tar.gz |
|
PYTHON_VER |
Python-3.10.2 |
|
PYTHON_PACKAGE |
|
|
Zookeeper |
3.7.0 |
|
ZOOKEEPER_PACKAGE |
|
|
KAFKA |
3.2 |
|
KAFKA_PACKAGE |
kafka_2.12-3.2.0.tgz |
|
REPLICATION_FACTOR |
1 |
|
PARTITIONS |
Twice # of vCPUs |
|
# OF PRODUCERS |
Twice # of vCPUs |
|
# OF CONSUMERS |
Twice # of vCPUs |
|
# OF BROKERS |
Twice # of vCPUs |
|
NUM_RECORDS |
5,000,000 |
|
ENCRYPTION |
TRUE |
|
RECORD_SIZE |
1,000 |
|
COMPRESSION_TYPE |
Zstd / LZ4 |
|
MESSAGES |
10,000,000 |
|
CONSUMER_TIMEOUT |
600,000 |
|
BATCH_SIZE |
524,288 |
|
LINGER_MS |
100 |
Table 2.3 Software and workload used for test results from Figure 8—Amazon EC2 m6i.4xlarge across compression types—encryption off.
|
Attribute |
m6i.4xlarge |
|
OS_VER |
20.04.4 |
|
OS_IMAGE |
Ubuntu 20.04.4 LTS |
|
OPENJDK_VER |
jdk-17.0.1 |
|
OPENJDK_PACKAGE |
|
|
PYTHON_VER |
Python-3.10.2 |
|
PYTHON_PACKAGE |
|
|
Zookeeper |
3.7.0 |
|
ZOOKEEPER_PACKAGE |
|
|
KAFKA |
2.8.1 *) |
|
KAFKA_PACKAGE |
|
REPLICATION_FACTOR |
1 |
|
PARTITIONS |
Twice # of vCPUs |
|
# OF PRODUCERS |
Twice # of vCPUs |
|
# OF CONSUMERS |
Twice # of vCPUs |
|
# OF BROKERS |
Twice # of vCPUs |
|
NUM_RECORDS |
3,000,000 |
|
ENCRYPTION |
Off |
|
RECORD_SIZE |
1000 |
|
COMPRESSION_TYPE |
Gzip/Zstd/Snappy/LZ4 |
|
MESSAGES |
2,000,000 |
|
CONSUMER_TIMEOUT |
600,000 |
|
BATCH_SIZE |
Default |
|
LINGER_MS |
Default |
Table 2.4 Kafka configuration used for test results from Figure 9—3rd gen Intel Xeon Scalable processor with a compression library from Intel.
|
REPLICATION_FACTOR |
1 |
|
PARTITIONS |
1 |
|
# OF PRODUCERS |
112 |
|
# OF CONSUMERS |
1 |
|
# OF BROKERS |
1 |
|
NUM_RECORDS |
5,000,000 |
|
MESSAGES |
10000000.0 |
|
ENCRYPTION |
No |
|
RECORD_SIZE |
2048 |
|
COMPRESSION_TYPE |
Gzip/lz4 |
|
BATCH_SIZE |
524288.0 |
|
LINGER_MS |
100 ms |