This information was first published on GitHub*.
Deploy Distributed LLMs with Intel® Xeon® Scalable Processors on Microsoft Azure*
Overview
Large language models (LLMs) are becoming ubiquitous, but in many cases, you don’t need the full capability of the latest GPT model. Additionally, when you have a specific task at hand, the performance of the biggest GPT model may not be optimal. Often, fine-tuning a small LLM on your dataset can yield better results.
The Intel® Cloud Optimization Modules for Microsoft Azure*: nanoGPT Distributed Training is designed to illustrate the process of fine-tuning a large language model with 3rd or 4th generation Intel® Xeon® Scalable processors on Microsoft Azure. Specifically, we show the process of fine-tuning a nanoGPT model with 124M parameters on the OpenWebText dataset in a distributed architecture. This project builds upon the initial codebase of nanoGPT built by Andrej Karpathy. The objective is to understand how to set up distributed training so that you can fine-tune the model to your specific workload. The result of this module is a base LLM that can generate words, or tokens, that are suitable for your use case when you modify it to your specific objective and dataset.
This module demonstrates how to transform a standard single-node PyTorch* training scenario into a high-performance distributed training scenario across multiple CPUs. To fully capitalize on Intel® hardware and further optimize the fine-tuning process, this module integrates Intel® Extension for PyTorch* and Intel® oneAPI Collective Communications Library (oneCCL). The module serves as a guide to setting up an Azure cluster for distributed training workloads while showcasing a complete project for fine-tuning LLMs.
To form the cluster, the cloud solution implements Azure trusted virtual machines (VM), using instances from the Dv5 series. To enable seamless communication between the instances, each of the machines are connected to the same virtual network, and a permissive network security group is established that allows all traffic from other nodes within the cluster. The raw dataset is taken from Hugging Face* Hub, and once the model has been trained, the weights are saved to the virtual machines.
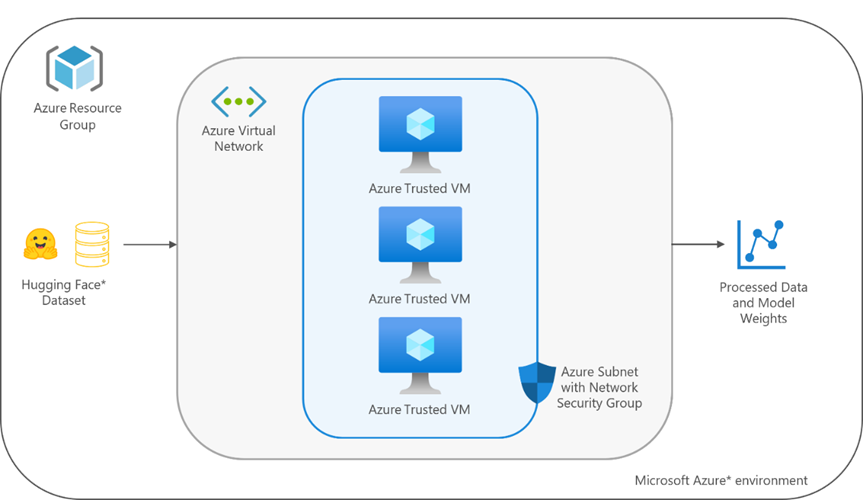
Figure 1. Architectural diagram of Azure nanoGPT distributed training module
In Part 1 of this two-part article, we configure the Azure resources and fine-tune the model on a single node.
Part 2 sets up the distributed training architecture and add two additional nodes to the cluster.
Get Started
Before beginning this tutorial, ensure that you have downloaded and installed the prerequisites.
Then, from a new terminal window, use the following command to sign in to your account interactively with the Microsoft Azure command-line interface.
az login
Create an Azure Resource Group
The Azure resource group holds all of the resources for our solution. Name the resource group intel-nano-gpt and set the location to eastus.
# Set the names of the resource group and location
export RG=intel-nano-gpt
export LOC=eastus
# Create the Azure resource group
az group create -n $RG -l $LOC
Create an Azure Virtual Network
Next, we create an Azure virtual network for the virtual machine cluster. This allows the VMs created in the following steps to securely communicate with each other.
Use the following command to create a virtual network named intel-nano-gpt-vnet and an associated subnet named intel-nano-gpt-subnet.
export VNET_NAME=intel-nano-gpt-vnet
export SUBNET_NAME=intel-nano-gpt-subnet
az network vnet create --name $VNET_NAME \
--resource-group $RG \
--address-prefix 10.0.0.0/16 \
--subnet-name $SUBNET_NAME \
--subnet-prefixes 10.0.0.0/24
Create an Azure Network Security Group
This security group filters the traffic between the virtual machines in the network that was created in the previous step and allow for SSH access into the VMs in the cluster.
Azure network security group in the resource group named intel-nano-gpt-network-security-group.
export NETWORK_SECURITY_GROUP=intel-nano-gpt-network-security-group
az network nsg create -n $NETWORK_SECURITY_GROUP -g $RG
Create an SSH Key Pair
To securely connect to the Azure VMs in the clusterNext, create an SSH key pair as follows:
export SSH_KEY=intel-nano-gpt-SSH-key
az sshkey create -n $SSH_KEY -g $RG
To change privacy permissions of the private SSH key that was generated, use the following command:
chmod 600 ~/.ssh/<private-ssh-key>
Next, upload the public SSH key to your Azure account in the resource group that was created in the previous step.
az sshkey create -n $SSH_KEY -g $RG --public-key "@/home/<username>/.ssh/<ssh-key.pub>"
Verify that the SSH key was successfully uploaded to Azure using the following command:
az sshkey show -n $SSH_KEY -g $RG
Create the Azure VM
Now we are ready to create the first Azure VM in the cluster to fine-tune the model on a single node. We created a trusted virtual machine using an instance from the Dv5 series. This features a 3rd generation Intel Xeon Scalable processor featuring an all-core turbo clock speed of 3.5 GHz with Intel® Advanced Vector Extensions 512 (Intel® AVX-512), Intel® Turbo Boost Technology, and Intel® Deep Learning Boost. These VMs offer a combination of vCPUs and memory to meet the requirements associated with most enterprise workloads, such as small-to-medium databases, low-to-medium traffic web servers, application servers, and more. For this module, we selected the Standard_D32_v5 VM size, which comes with 32 vCPUs and 128 GiB of memory.
export VM_NAME=intel-nano-gpt-vm
export VM_SIZE=Standard_D32_v5
export ADMIN_USERNAME=azureuser
az vm create -n $VM_NAME -g $RG \
--size $VM_SIZE \
--image Ubuntu2204 \
--os-disk-size-gb 256 \
--admin-username $ADMIN_USERNAME \
--ssh-key-name $SSH_KEY \
--public-ip-sku Standard \
--vnet-name $VNET_NAME \
--subnet $SUBNET_NAME \
--nsg $NETWORK_SECURITY_GROUP \
--nsg-rule SSH
Then, SSH into the VM using the following command:
ssh -i ~/.ssh/<private-ssh-key> azureuser@<public-IP-Address>
Note In the ~/.ssh directory of your VM, ensure you have stored the private SSH key that was generated in the previous step in a file called id_rsa and have enabled the required privacy permissions using the command: chmod 600 ~/.ssh/id_rsa.
Install Dependencies
To set up the environment for fine-tuning the nanoGPT model, first update the package manager and install TCMalloc for extra performance.
sudo apt update
sudo apt install libgoogle-perftools-dev unzip -y
Set Up an Anaconda* Environment
To fine-tune nanoGPT, first download and install conda* based on your operating system.
For Linux, use the following commands:
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh
bash ./Anaconda3-2023.07-1-Linux-x86_64.sh
To begin using conda, you have two options: restart the shell or run the following command:
source ~/.bashrc
Running this command sources the bashrc file, which has the same effect as restarting the shell. This enables you to access and use conda for managing your Python* environments and packages seamlessly.
Once conda is installed, create a virtual environment and activate it using the following commands:
conda create -n cluster_env python=3.10
conda activate cluster_env
We have now prepared our environment and can move onto downloading the data and training our nanoGPT model.
Fine-tune nanoGPT on a Single CPU
Now that the Azure resources have been created, download the OpenWebText dataset and fine-tune the model on a single node.
First, clone the repo and install the dependencies:
git clone https://github.com/intel/intel-cloud-optimizations-azure
cd intel-cloud-optimizations-azure/distributed-training/nlp
pip install -r requirements.txt
To run distributed training, use the Intel® oneAPI Collective Communications Library (oneCCL). Download the appropriate wheel file and install it using the following commands:
wget https://intel-extension-for-pytorch.s3.amazonaws.com/torch_ccl/cpu/oneccl_bind_pt-1.13.0%2Bcpu-cp310-cp310-linux_x86_64.whl
pip install oneccl_bind_pt-1.13.0+cpu-cp310-cp310-linux_x86_64.whl
You can delete the wheel file after installation:
rm oneccl_bind_pt-1.13.0+cpu-cp310-cp310-linux_x86_64.whl
Next, you can download and process the full OpenWebText dataset. This is accomplished with one script.
python data/openwebtext/prepare.py --full
Note The complete dataset takes up approximately 54 GiB in the Hugging Face .cache directory and contains about 8 million documents (8,013,769). During the tokenization process, the storage usage might increase to around 120 GiB. The entire process can take anywhere from 30 minutes to 3 hours, depending on your CPU performance.
Upon successful completion of the script, two files are generated:
- train.bin: This file will be approximately 17GB (~9B tokens) in size.
- val.bin: This file will be around 8.5MB (~4M tokens) in size.
You should be able to run:
ls -ltrh data/openwebtext/
and see the following output:

Figure 2. Results of the OpenWebText data preprocessing
To streamline the training process, we used the Hugging Face Accelerate library. Once you have the processed .bin files, you are ready to generate the training configuration file by running the following accelerate command:
accelerate config --config_file ./single_config.yaml
When you run the above command, you are prompted to answer a series of questions to configure the training process. Following are the prompts and responses to set up the single-node environment:
In which compute environment are you running?
This machine
Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]: yes
Do you want to use Intel PyTorch Extension (IPEX) to speed up training on CPU? [yes/NO]: yes
Do you wish to optimize your script with torch dynamo?[yes/NO]: no
Do you want to use DeepSpeed? [yes/NO]: no
Do you wish to use FP16 or BF16 (mixed precision)?
fp16
Note Select bf16 on 4th generation Intel Xeon CPUs; for other CPUs, select fp16.
This generates a configuration file named single_config.yaml in your current working directory.
We are now ready to begin fine-tuning the nanoGPT model. You can start the process by running the main.py script. Alternatively, to streamline the process and optimize performance, run main.py using the accelerate launch command with the generated configuration file. The accelerate library automatically selects the appropriate number of cores, device, and mixed precision settings based on the configuration file. You can begin this process with the following command:
accelerate launch --config_file ./single_config.yaml main.py
This command initiates the fine-tuning process, using the settings specified in the single_config.yaml file.
You can review the intel_nano_gpt_train_cfg.yaml and make changes to the batch_size, device, max_iters, and so forth, as needed. If you prefer to use a different configuration file, you can make one and give it a new name like new_config.yaml and pass it to main.py using the --config-name flag as follows:
accelerate launch --config_file ./single_config.yaml main.py --config-name new_config.yaml
Note Accelerate uses the maximum number of physical cores (virtual cores excluded) by default. If you want to experiment by controlling the number of threads, you can set --num_cpu_threads_per_process to the number of threads you wish to use. For example, if you want to run the script with only four threads:
accelerate launch --config_file ./single_config.yaml --num_cpu_threads_per_process 4 main.py
The script trains the model for a specified number of iterations, set by max_iters, and performs evaluations at regular intervals, set byeval_interval. If the evaluation score surpasses the previous model's performance, the current model will be saved in the current working directory under the name ckpt.pt. It will also save the snapshot of the training progress under the name snapshot.pt. You can customize these settings by modifying the values in the intel_nano_gpt_train_cfg.yaml file.
We performed ten iterations of training, successfully completing the process. During this process, the model was trained on a total of 320 samples. This was achieved with a batch size of 32 and was completed in approximately seven and a half minutes.

Figure 3. Results of single-node fine-tuning
The total dataset consists of approximately eight million training samples, which would take much longer to train. However, the OpenWebText dataset was not built for a downstream task; it is meant to replicate the entire training dataset used for the base nanoGPT model. There are many smaller datasets like the Alpaca dataset with 52,000 samples, which would be quite feasible on a distributed setup similar to the one described here. Ultimately, you will use your own dataset to customize the model for your specific task.
Summary
In this tutorial, we showed how to set up and fine-tune a nanoGPT model on a singular machine running on an instance from the Azure Dv5 series. Now that we have processed the dataset and configured the Azure resources for the cluster, Part 2 show how to set up the multi-CPU environment, fine-tune the model on three nodes, and review the performance between environments.
Additional Resources
Intel Cloud Optimization Modules for Azure: nanoGPT Distributed Training
Intel Xeon Scalable Processors
Initial Code Base of nanoGPT Built by Andrej Karpathy
Azure Trusted Virtual Machines Using Dv5 Series
Create an Azure Resource Group
Create an Azure Virtual Network
Create an Azure Network Security Group