This tutorial picks up where the article Deploy Kubeflow with Confidential Computing VMs on Microsoft Azure* left off. It is part of the Intel® Cloud Optimization Modules, a set of cloud-native open source reference architectures that are designed to facilitate building and deploying Intel-optimized AI solutions on leading cloud providers, including Amazon Web Services (AWS)*, Microsoft Azure*, and Google Cloud Platform*.
After installing Kubeflow* on your Microsoft Azure* Kubernetes Services (AKS) cluster, this tutorial will step through how to build and deploy a Kubeflow pipeline to predict the probability of a loan default using Intel® Optimization for XGBoost* and Intel® oneAPI Data Analytics Library (oneDAL) to accelerate training and inference. The full code for this tutorial can be found here. Below is a graph of the full pipeline.
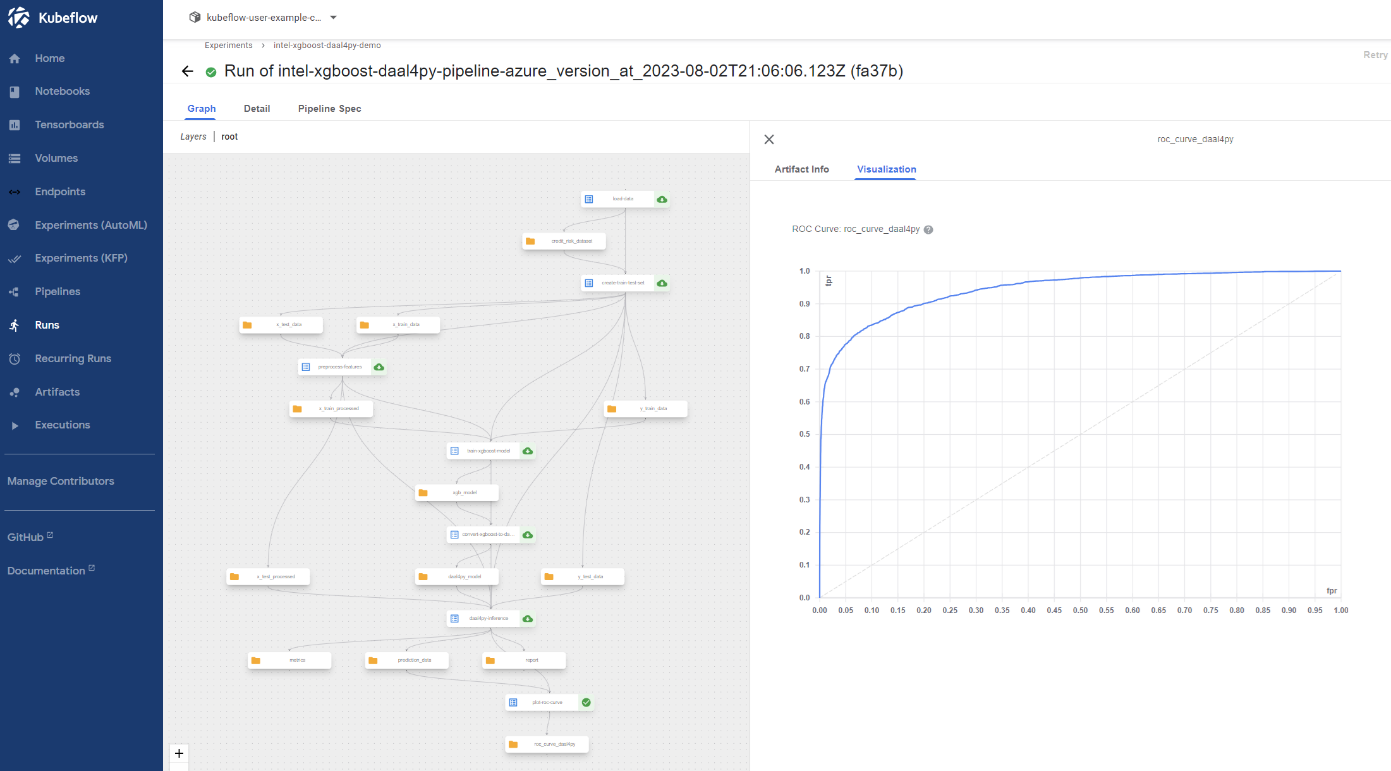
The Kubeflow pipeline consists of the following 7 components:
- Load data: Load the dataset (credit_risk_dataset.csv) from the URL specified in the pipeline run parameters, and perform synthetic data augmentation. Download the Kaggle* Credit Risk Dataset.
- Create training and test sets: Split the data into training and test sets of an approximately 75:25 split for model evaluation.
- Preprocess features: Transform the categorical features of the training and test sets by using one-hot encoding, then impute missing values and power-transform numerical features.
- Train XGBoost model: Train an XGBoost model using the accelerations provided by the Intel Optimizations for XGBoost.
- Convert XGBoost model to daal4py: Convert the XGBoost model to an inference-optimized daal4py classifier.
- daal4py Inference: Compute predictions using the inference-optimized daal4py classifier and evaluate model performance. It returns an output summary of the precision, recall, and F1 score for each class, as well as the area under the curve (AUC) and accuracy score of the model.
- Plot ROC Curve: Perform model validation on the test data and generate a plot of the receiver operating characteristic (ROC) curve.
The code for the pipeline is in the src folder of the repo, in the intel-xgboost-daal4py-pipeline-azure.py Python* script. Before running the script, ensure that you have installed version 2.0 or above of the Kubeflow Pipelines SDK. To update your SDK version, you can use:
pip install -U kfp
Intel® Software Guard Extensions
The Kubeflow pipeline leverages secure and confidential computing nodes using Intel® Software Guard Extensions (Intel® SGX) virtual machines on the Azure Kubernetes cluster. The pipeline pods are assigned to an Intel SGX node by adding a nodeSelector to the pipeline task. The node selector will look for a node with a matching label key/value pair when scheduling the pods. When creating the Intel SGX node pool on the AKS cluster, you can use the node label parameter --labels intelvm=sgx. You can then reference this label in the pipeline code for scheduling pods onto an Intel SGX node. The code below will assign the data preprocessing pipeline task to an Intel SGX node:
from kfp import kubernetes kubernetes.add_node_selector(task = preprocess_features_op, label_key = 'intelvm', label_value = 'sgx')
Pipeline Components
The first component in the pipeline, load_data, downloads the credit_risk_dataset.csv from the URL provided in the pipeline run parameters and synthetically augments the data to the specified size. It then saves the new dataset as an output artifact in the Kubeflow MinIO* volume.
This dataset is then read into the next step of the component, create_train_test_set, which subsets the data into an approximately 75:25 split for model evaluation. The training and test sets, X_train, y_train, X_test and y_test, are then saved as output dataset artifacts.
The preprocess_features component creates a data preprocessing pipeline to prepare the data for the XGBoost model. This component loads the X_train and X_test files from the MinIO storage and transforms the categorical features using one-hot encoding, imputes missing values, and power-transforms the numerical features.
The next component then trains the XGBoost model. Using XGBoost on Intel CPUs takes advantage of software accelerations powered by oneAPI, without requiring any code changes. To get the highest amount of optimization for Intel CPUs, ensure that you are using the latest version of XGBoost. In the initial testing of incremental training updates of size 1 million, Intel Optimization for XGBoost v1.4.2 offers up to 1.54x speedup over stock XGBoost v0.811. The following code snippet is implemented in the train_xgboost_model component:
# Create the XGBoost DMatrix, which is optimized for memory efficiency and training speed dtrain = xgb.DMatrix(X_train.values, y_train.values) # Define the model parameters params = {"objective": "binary:logistic", "eval_metric": "logloss", "nthread": 4, # num_cpu "tree_method": "hist", "learning_rate": 0.02, "max_depth": 10, "min_child_weight": 6, "n_jobs": 4, # num_cpu, "verbosity": 1} # Train XGBoost model clf = xgb.train(params = params, dtrain = dtrain, num_boost_round = 500)
To further optimize the model prediction speed, we convert the trained XGBoost model into an inference-optimized daal4py classifier in the convert_xgboost_to_daal4py component. daal4py is the Python API of oneDAL. In testing batch inference of size 1 million, oneDAL provided a speedup of up to 4.44x1. You can convert the XGBoost model to daal4py with one line of code:
# Convert XGBoost model to daal4py daal_model = d4p.get_gbt_model_from_xgboost(clf)
Then use the daal4py model to evaluate the model’s performance on the test set in the daal4py_inference component.
# Compute binary class labels and probabilities daal_prediction = d4p.gbt_classification_prediction( nClasses = 2, resultsToEvaluate = "computeClassLabels|computeClassProbabilities" ).compute(X_test, daal_model)
We compute both the binary class labels and probabilities by calling the gbt_classification_prediction method in the code above. You can also calculate the log probabilities with this function. This component will return the classification report in CSV format, as well as two Kubeflow metrics artifacts: the area under the curve and the accuracy of the model. These can be viewed in the Visualization tab of the metrics artifact.
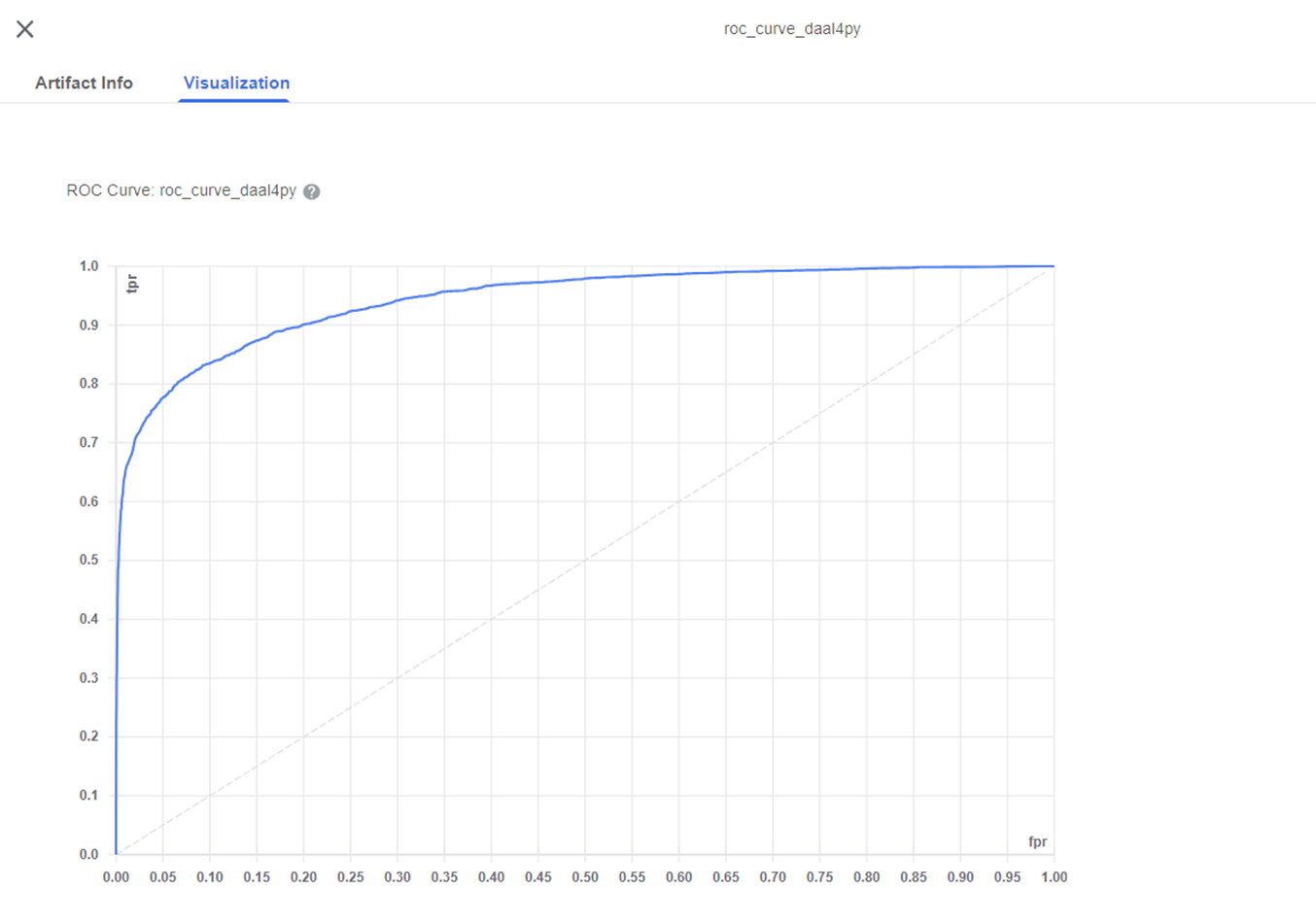
In the last component of the pipeline, plot_roc_curve, we load the prediction data with the probabilities and the true class labels to calculate the ROC curve using the CPU-accelerated version from Intel® Extension for Scikit-Learn. The results are stored as a Kubeflow ClassificationMetrics artifact, which can be viewed in the Visualization tab of the roc_curve_daal4py artifact. Once your Pipeline has finished running, you should see a similar graph as the one below.
Next Steps
- Access the full source code on GitHub.
- Register for Office Hours for help on your implementation.
- Learn more about all of our Intel® Cloud Optimization Modules.
- Come chat with us on our Intel® DevHub Discord server to keep interacting with fellow developers.
Previous Article: Learn How to Deploy Kubeflow with Confidential Computing VMs on Microsoft Azure