Introduction
Cython* is a superset of Python* that additionally supports C functions and C types on variable and class attributes. Cython is used for wrapping external C libraries that speed up the execution of a Python program. Cython generates C extension modules, which are used by the main Python program using the import statement.
One interesting feature of Cython is that it supports native parallelism (see the cython.parallel module). The cython.parallel.prange function can be used for parallel loops; thus one can take advantage of Intel® Many Integrated Core Architecture (Intel® MIC Architecture) using the thread parallelism in Python.
Cython in Intel® Distribution for Python* 2017
Intel® Distribution for Python* 2017 is a binary distribution of Python interpreter, which accelerates core Python packages, including NumPy, SciPy, Jupyter, matplotlib, Cython, and so on. The package integrates Intel® Math Kernel Library (Intel® MKL), Intel® Data Analytics Acceleration Library (Intel® DAAL), pyDAAL, Intel® MPI Library and Intel® Threading Building Blocks (Intel® TBB). For more information on these packages, please refer to the Release Notes.
The Intel Distribution for Python 2017 can be downloaded here. It is available for free for Python 2.7.x and 3.5.x on OS X*, Windows* 7 and later, and Linux*. The package can be installed as a standalone or with the Intel® Parallel Studio XE 2017.
Intel Distribution for Python supports both Python 2 and Python 3. There are two separate packages available in the Intel Distribution for Python: Python 2.7 and Python 3.5. In this article, the Intel® Distribution for Python 2.7 on Linux (l_python27_pu_2017.0.035.tgz) is installed on a 1.4 GHz, 68-core Intel® Xeon Phi™ processor 7250 with four hardware threads per core (a total of 272 hardware threads). To install, extract the package content, run the install script, and then follow the installer prompts:
After the installation completes, activate the root environment (see the Release Notes):
$ source /opt/intel/intelpython27/bin/activate root
Thread Parallelism in Cython
In Python, there is a mutex that prevents multiple native threads from executing bycodes at the same time. Because of this, threads in Python cannot run in parallel. This section explores thread parallelism in Cython. This functionality is then imported to the Python code as an extension module allowing the Python code to utilize all the cores and threads of the hardware underneath.
To generate an extension module, one can write Cython code (file with extension .pyx). The .pyx file is then compiled by the Cython compiler to convert it into efficient C code (file with extension .c). The .c file is in turn compiled and linked by a C/C++ compiler to generate a shared library (.so file). The shared library can be imported in Python as a module.
In the following multithreads.pyx file, the function serial_loop computes log(a)*log(b) for each entry in the A and B arrays and stores the result in the C array. The log function is imported from the C math library. The NumPy module, the high-performance scientific computation and data analysis package, is used in order to vectorize operations on A and B arrays.
Similarly, the function parallel_loop performs the same computation using OpenMP* threads to execute the computation in the body loop. Instead of using range, prange (parallel range) is used to allow multiple threads executed in parallel. prange is a function of the cython.parallel module and can be used for parallel loops. When this function is called, OpenMP starts a thread pool and distributes the work among the threads. Note that the prange function can be used only when the Global Interpreter Lock (GIL) is released by putting the loop in a nogil context (the GIL global variable prevents multiple threads to run concurrently). With wraparound(False), Cython never checks for negative indices; with boundscheck(False), Cython doesn’t do bound check on the arrays.
$ cat multithreads.pyx
After completing the Cython code, the Cython compiler converts it to a C code extension file. This can be done by a disutils setup.py file (disutils is used to distribute Python modules). To use the OpenMP support, one must tell the compiler to enable OpenMP by providing the flag –fopenmp in a compile argument and link argument in the setup.py file as shown below. The setup.py file invokes the setuptools build process that generates the extension modules. By default, this setup.py uses GNU GCC* to compile the C code of the Python extension. In addition, we add –O0 compile flags (disable all optimizations) to create a baseline measurement.
$ cat setup.py
Use the command below to build C/C++ extensions:
$ python setup.py build_ext –-inplace
Alternatively, you can also manually compile the Cython code:
$ cython multithreads.pyx
This generates the multithreads.c file, which contains the Python extension code. You can compile the extension code with the gcc compiler to generate the shared object multithreads.so file.
After the shared object is generated. Python code can import this module to take advantage of thread parallelism. The following section will show how one can improve its performance.
You can import the timeit module to measure the execution time of a Python function. Note that by default, timeit runs the measured function 1,000,000 times. Set the number of execution times to 100 in the following examples for a shorter execution time. Basically, timeit.Timer () imports the multithreads module and measures the time spent by the function multithreads.test_serial(). The argument number=100 tells the Python interpreter to perform the run 100 times. Thus, t1.timeit(number=100) measures the time to execute the serial loop (only one thread performs the loop) 100 times.
Similarly, t12.timeit(number=100) measures the time when executing the parallel loop (multiple threads perform the computation in parallel) 100 times.
- Measure the serial loop with
gcccompiler, compiler option–O0(disabled all optimizations).
Import timeit and time t1 to measure the time spent in the serial loop. Note that you built with gcc compiler and disabled all optimizations. The result is displayed in seconds.
- Measure the parallel loop with
gcccompiler, compiler option–O0(disabled all optimizations).
The parallel loop is measured by t2 (again, you built with gcc compiler and disabled all optimizations).
As you observe, the parallel loop improves the performance by roughly a factor of 110x.
- Measure the parallel loop with
icccompiler, compiler option–O0(disabled all optimizations).
Next, recompile using the Intel® C Compiler and compare the performance. For the Intel® C/C++ Compiler, use the –qopenmp flag instead of –fopenmp to enable OpenMP. After installing the Intel Parallel Studio XE 2017, set the proper environment variables and delete all previous build:
To explicitly use the Intel icc to compile this application, execute the setup.py file with the following command:
$ LDSHARED="icc -shared" CC=icc python setup.py build_ext –-inplace
The parallel loop is measured by t2 (this time, you built with Intel compiler, disabled all optimizations):
- Measure the parallel loop with
icccompiler, compiler option–O3.
For the third try, you may want to see whether or not using –O3 optimization and enabling Intel® Advanced Vector Extensions (Intel® AVX-512) ISA on the Intel® Xeon Phi™ processor can improve the performance. To do this, in the setup.py, replace –O0 with –O3 and add –xMIC-AVX512. Repeat the compilation, and then run the parallel loop as indicated in the previous step, which results in: 21.027512073516846. The following graph shows the results (in seconds) when compiling with gcc, icc without optimization enabled, and icc with optimization, Intel AVX-512 ISA:
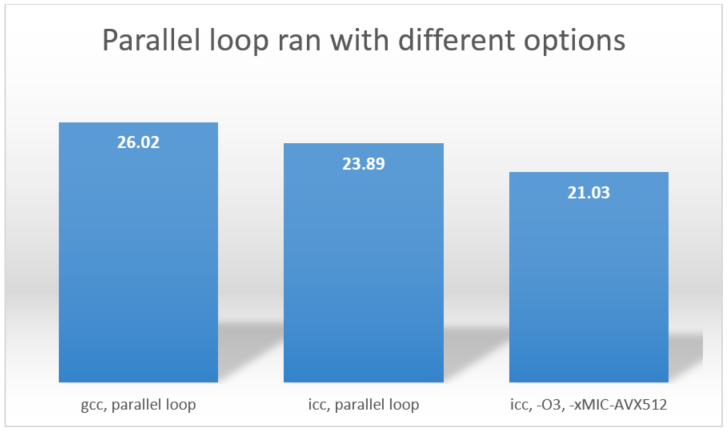
The result shows that the best result (21.03 seconds) is obtained when you compile the parallel loop with the Intel compiler, and enable auto-vectorization (-O3) combined with Intel AVX-512 ISA (-xMIC-AVX512) for the Intel Xeon Phi processor.
By default, the Intel Xeon Phi processor uses all available resources: it has 68 cores, and each core uses four hardware threads. A total of 272 threads or four threads/core are running in a parallel region. It is possible to modify the core and number of thread running by each core. The last section shows how to use an environment variable to accomplish this.
- To run 68 threads on 68 cores (one thread per core) executing the loop body for 100 times, set the
KMP_PLACE_THREADSenvironment as below:
$ export KMP_PLACE_THREADS=68c,1t
- To run 136 threads on 68 cores (two threads per core) running the parallel loop for 100 times, set the
KMP_PLACE_THREADSenvironment as below:
$ export KMP_PLACE_THREADS=68c,2t
- To run 204 threads on 68 cores (three threads per core) running the parallel loop for 100 times, set the
KMP_PLACE_THREADSenvironment as below:
$ export KMP_PLACE_THREADS=68c,3t
The following graph summarizes the result:

Conclusion
This article showed how to use Cython to build an extension module for Python in order to take advantage of multithread support for the Intel Xeon Phi processor. It shows how to use the setup script to build a shared library. The parallel loop performance can be improved by trying different compiler options in the setup script. This article also showed how to set different number of threads per core.