The Intel® Extension for PyTorch* provides optimizations and features to improve performance on Intel® hardware. It provides easy GPU acceleration for Intel discrete GPUs via the PyTorch “XPU” device. This allows users to run PyTorch models on computers with Intel® GPUs and Windows* using Docker* Desktop and WSL2.
One of Docker’s key benefits is that it simplifies the installation process. It takes care of all the necessary steps, including installing the oneAPI graphics runtime, PyTorch dependencies, and any other required libraries. This makes the process of getting up and running with PyTorch models on Intel GPUs easy and efficient.
To demonstrate, we will run a popular AI text-to-image model with stable diffusion on Windows using Intel® Arc™ GPUs.
Setup
Prerequisites
If you want to follow along, please ensure that your Windows computer has the latest Intel Arc GPU drivers and that your Intel GPU is listed in the Windows Device Manager:

Enable Docker Desktop with WSL2
We will use Docker Desktop with WSL2, so ensure your computer has WSL2 enabled. You can check using the following command:
wsl -l -v
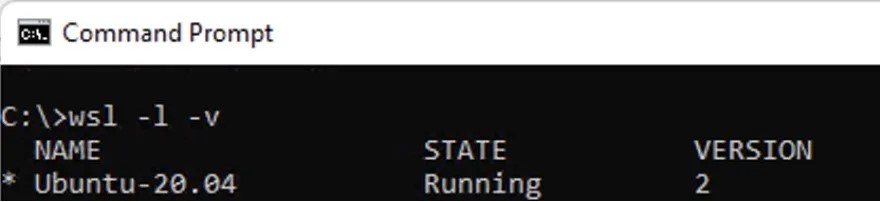
Now that we have WSL2 up and running, Install Docker Desktop for Windows and reboot.
curl -fsSLo docker_install_offline.exe https://desktop.docker.com/win/stable/Docker%20Desktop%20Installer.exe
start /wait "" docker_install_offline.exe install --accept-license –quiet
shutdown -r -t 0
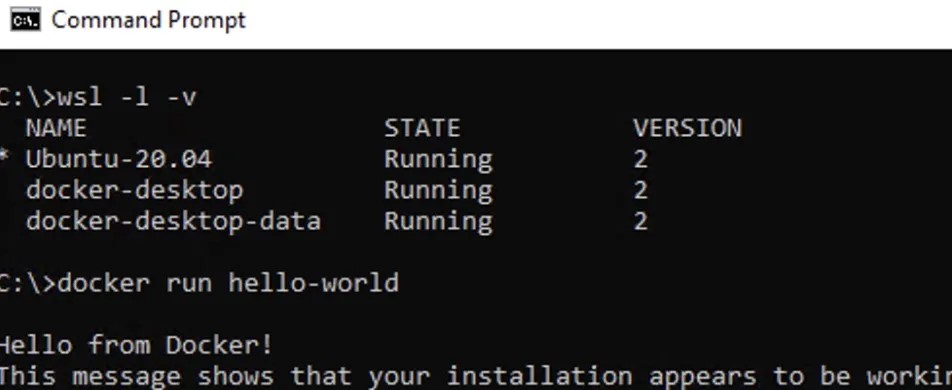
After reboot, Docker Desktop will start automatically. You can run a simple “hello world” container to verify that it’s properly enabled with WSL2:
wsl -l -v
docker run hello-world
Running PyTorch Models on Windows with Intel Arc GPUs
The official containers for Intel Extension for PyTorch are accessible on Docker Hub. They are equipped with all the necessary components, including the Intel® Graphics runtime, oneAPI, and any dependencies required to run on Intel Arc GPUs. If the container is not stored locally, Docker can easily retrieve it from Docker Hub and launch it immediately.
Before we run the container for Stable Diffusion, it is recommended to download the offline stable diffusion model. Please first install git for windows if you don’t have it in your system yet.
mkdir c:\data
cd c:\data
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
You may encounter a hangup sometimes as the cloning command for the Hugging Face repository cannot exit cleanly after downloading the code. In this case, please press Ctrl+C for a force exit.
Next, run the container as follows:
docker run -it --rm
--device /dev/dxg
-v /usr/lib/wsl:/usr/lib/wsl
-v c:\data:/data
-p 9999:9999
intel/intel-extension-for-pytorch:gpu
We are exposing port 9999 for our Jupyter* notebook and the “data” folder where we previously downloaded the Stable Diffusion offline model. This allows us to reuse the model in future runs.
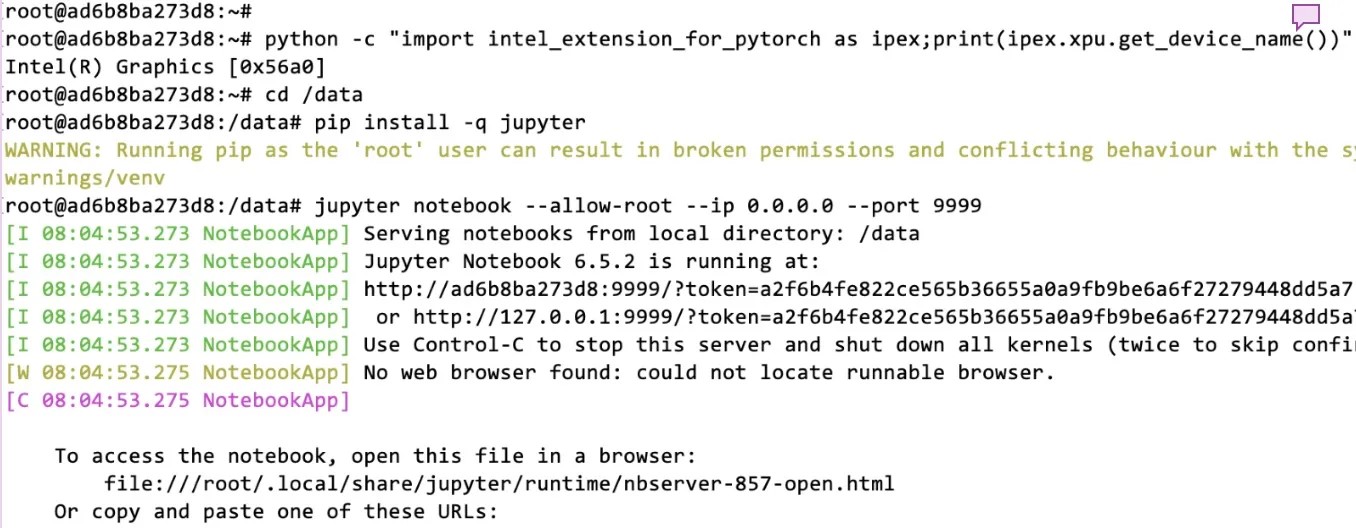
Inside the container prompt, we can first check if the Intel Arc GPU is detected by Intel Extension for PyTorch and enable the Jupyter notebook for remote access at port 9999:
python -c "import torch;import intel_extension_for_pytorch as ipex;print(ipex.xpu.get_device_name(0))"
cd /data
pip install -q jupyter
jupyter notebook --allow-root --ip 0.0.0.0 --port 9999
Sample output for above commands is shown here for reference:
Open the Jupyter notebook in your browser using the URL from output, and run Stable Diffusion using Intel Arc GPUs:
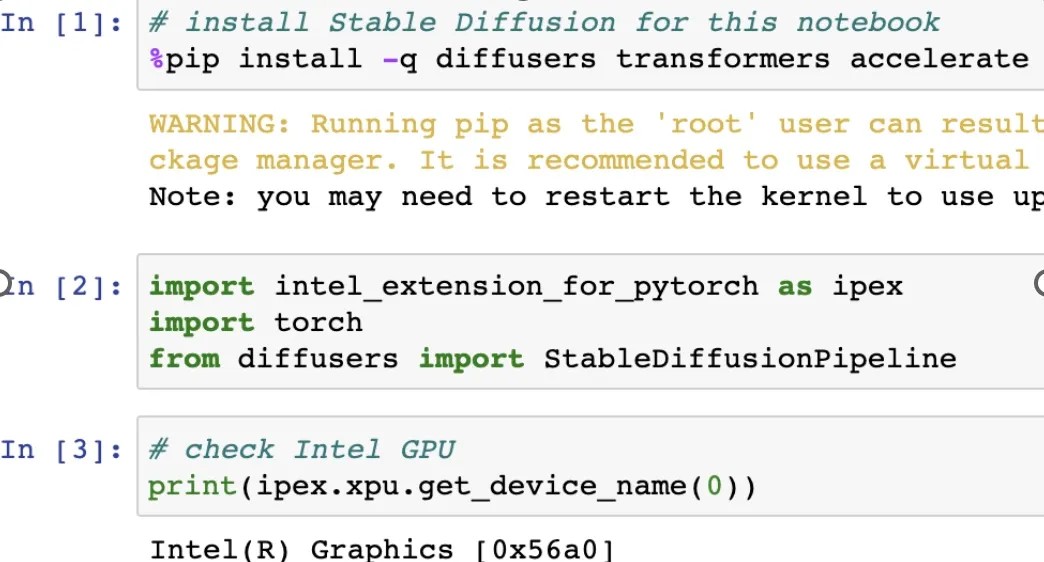
# install Stable Diffusion for this notebook
%pip install -q diffusers transformers accelerate
import intel_extension_for_pytorch as ipex
import torch
from diffusers import StableDiffusionPipeline
# check Intel GPU
print(ipex.xpu.get_device_name(0))
# load the Stable Diffusion model
pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-5",
revision="fp16",
torch_dtype=torch.float16)
# move the model to Intel Arc GPU
pipe = pipe.to("xpu")
# model is ready for submitting queries
pipe("an astronaut riding a horse on mars").images[0]
# run another query
pipe("cat sitting on a park bench").images[0]
Sample output is shown here for reference:
We can now load the model and run some sample text-to-image queries:


You can similarly run any other PyTorch model(s) on Windows WSL2 and Intel Arc GPUs using this approach.
Get the Software
We encourage you to check out Intel’s other AI Tools and Framework optimizations and learn about the open, standards-based oneAPI multiarchitecture, multivendor programming model that forms the foundation of Intel’s AI software portfolio.
For more details about 4th Gen Intel Xeon Scalable processor, visit AI Platform where you can learn about how Intel is empowering developers to run high-performance, efficient end-to-end AI pipelines.