The Challenge
The Association for Computing Machinery (ACM) Recommender System Conference organizes an annual data science competition called the RecSys Challenge. Intel has participated in this challenge for two years. This year, Intel presented the SIHG4SR: Side Information Heterogeneous Graph for Session Recommender solution (published in the ACM Digital Library), which placed fourth on the final leaderboard (under the team name “MooreWins”).
The RecSyc Challenge 2022 was organized by Dressipi and focused on fashion recommendations. The provided dataset contains 1.1 million anonymized online retail sessions over an 18-month period (Figures 1 and 2). Each session contains the customer’s activity in one day, with a purchased item as a label. Each session resulted in a purchase. The challenge is to predict which item a customer will purchase based on a set of descriptive fashion characteristics. Solutions were ranked by mean reciprocal rank (MRR) score. Specifically, for each session, given a sequence of potentially purchased items, if the actual purchased item is shown with a higher rank, we can get a better MRR. Vice versa, MRR will be lower or even zero if the labeled item is lower in the prediction list. For example, if item3 is the actual purchased item, while the prediction list is [item2, item3, item1, item0], then \(MRR= \frac{1}{rank of item_3}=\frac{1}{2}\).

Figure 1. Example of an online shopping session
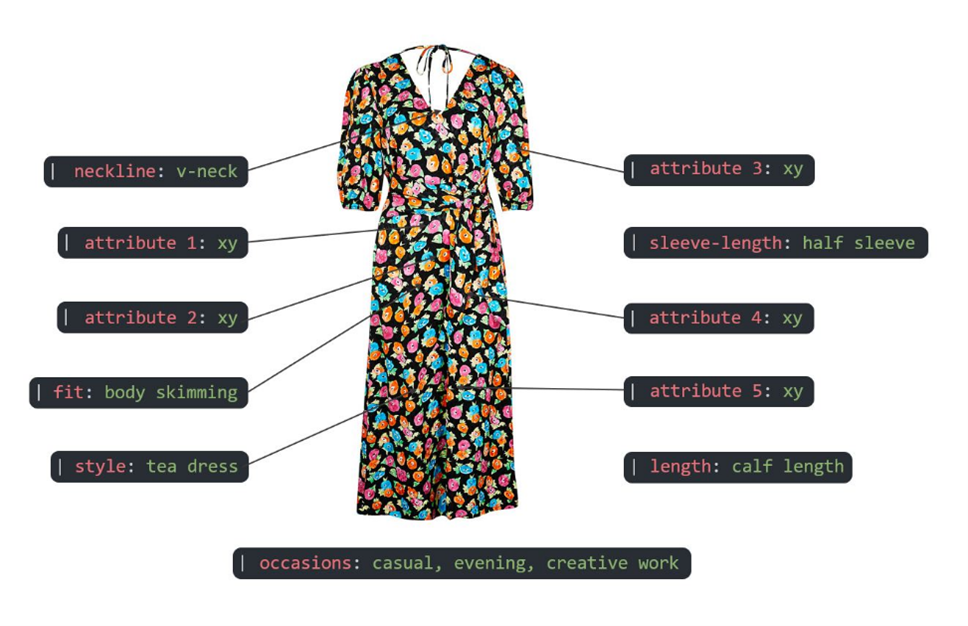
Figure 2. Example of item features
Our Solution
Our SIHG4SR solution uses a graph neural network (GNN) to learn from each session to reveal the underlying connection between viewed items and the final purchased item (Figure 3). We first represent each session with a graph implemented with Deep Graph Library (DGL), then feed them into the network. The model can be divided into three phases: encoding the input graph into three learnable embedding tables for item, feature, and category; reshaping feature and category to the same shape as item embedding, and then applying an attention readout layer and decoding the features; and fusing two independent predictions based on item and side information into one to get final item prediction.
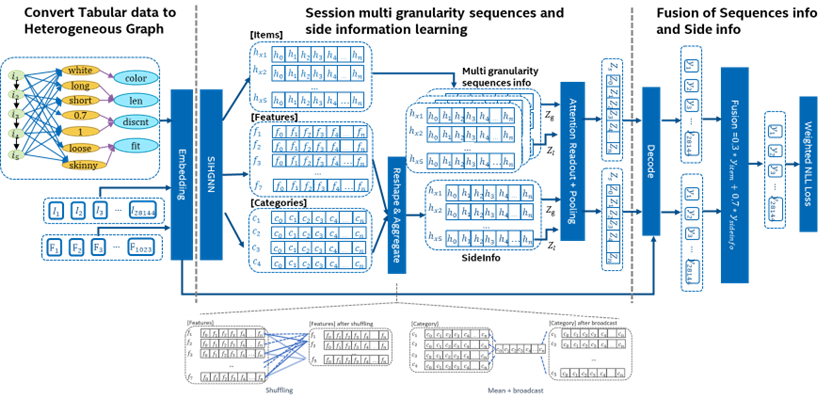
Figure 3. SIHG4SR architecture
This new model leverages heterogeneous graphs to represent each session, and fuses side information with sequences features using a novel aggregation strategy. This solution embeds item features as side information to better exploit user intent. Enhanced by recursive feature engineering, two-stage training strategy, multi-level ensemble, and hyperparameter tuning, we achieved a MRR of 0.20762, placing fourth overall.
We convert tabular session data into graphs (Figure 4). Each session is converted to one graph for a total of 1.1 million graphs. Each graph has three kinds of edges: those connecting the viewed items sequentially, those connecting items with their features, and those connecting features with their corresponding category. Items’ sequences play dominant roles in recommendation. By learning the viewing history, graph networks can detect different patterns and eventually predict the next click or purchased item. Besides that, with the descriptive features of each item and the corresponding categories, we can further exploit users’ intent with this rich context. We’ll refer to these item features and item features’ category as side information.
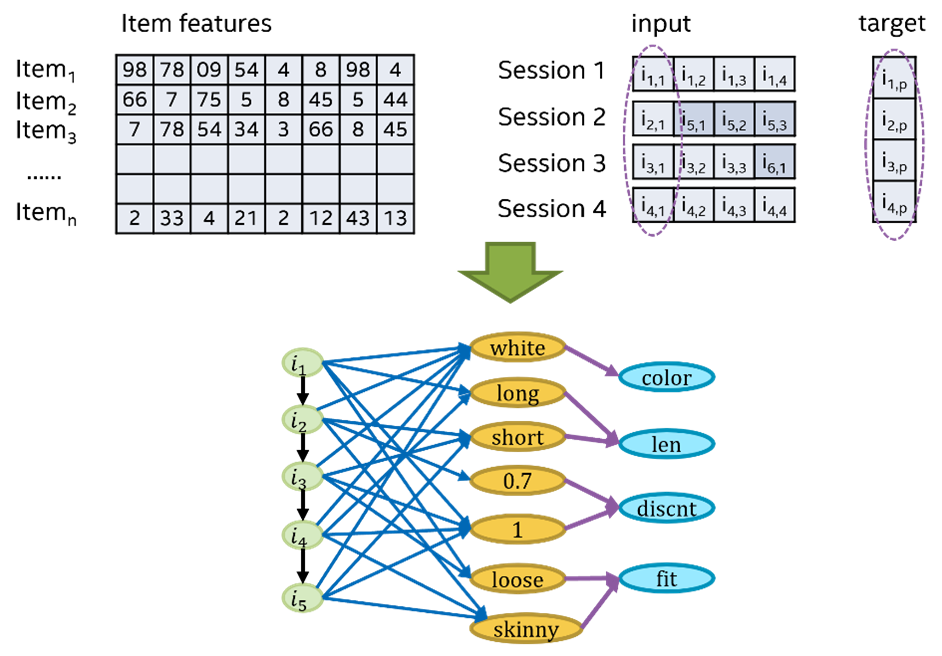
Figure 4. Convert tabular data to a heterogeneous graph
The Model
We propose a novel way to aggregate the item and side information, fuse different predictions, and enhance accuracy with a weighted loss function.
Aggregation of item and side information: We designed two methods to unify the shape of feature and category embeddings. For feature embeddings, we propose a “shuffling” method that sums feature embeddings connecting to the same item as new embedding vector. For category embeddings, we use a “mean + broadcasting” method that first calculates the mean of feature category embedding, then reshapes to item embedding by broadcasting.
Fuse item and side information predictions: We generate a local representation 𝑍𝑙 and a global representation 𝑍𝑔 to capture the user preferences, and then we combine these two representations with fixed ratios \(Z_s=αZ_l+βZ_g\).
Weighted loss: A weighted negative log likelihood (NLL) loss function is used to focus more on newer sessions than outdated ones.
Feature Engineering Improves Accuracy
Not all features contribute to the model, so selecting useful features to build the graphs is crucial. The provided item features contain 74 categories and 904 total unique “category:value” pairs. For example, let’s assume feature category 3 is “color.” Then, the feature values belonging to category 3 may be “red” or “white” or another color. If a category provides inconsistent information along the history or conflicted messages with others, it should be excluded from the graph. Furthermore, we can also generate new useful features based on the provided information. We performed 74 tests to exclude individual feature categories and then performed another eight tests to exclude combinations of feature categories according to previously detected harmful features. Additionally, by analysis of the viewing and purchasing timestamp, historical item viewing, and purchasing counting, we created three new features that benefit prediction.
Integrating with Intel® End-to-End AI Optimization Kit
Intel® End-to-End AI Optimization Kit is a composable toolkit for end-to-end AI optimization that delivers high performance and lightweight models on commodity hardware. We developed it to optimize each stage of the AI pipeline, including data processing, training, model optimization, and inference. It includes several components: RecDP provides simple APIs to do large-scale data processing, Smart Democratization Advisor (SDA) provides built-in knowledge to optimize and tune models with SigOpt*, train-free architecture search kit (DE-NAS) constructs compact neural networks, model adaptor easily transfers the pre-learning knowledge to new models.
Hyperparameter Tuning with Smart Democratization Advisor (SDA)
To get the optimal model architecture, we leveraged hyperparameter tuning to select the best parameters. Manual hyperparameter tuning (HPO) requires expertise and is usually error-prune during extensive, recursive trials. Thus, we leveraged SDA to do hyperparameter tuning for SIHG4SR (Figure 5).
Figure 5. Hyperparameter tuning with the Intel® End-to-End AI Optimization Kit
Two-Stage Training Strategy with Model Adapter
As each session only contains one purchased item but several viewed ones, we use a two-stage training strategy based on transfer learning methods to dig deeply into the data with the help of Model Adapter (Figure 6). In stage one, we focus on the next-click problem. The network is trying to correctly predict the next viewed item. With this, we can augment the data size by 5x, which greatly enhances the model. In stage two, we transfer the knowledge from the next-click to the purchased item prediction problem, where only a small dataset is enough to generate the model with accurate prediction.
![]()
Figure 6. Transfer learning-based two-stage training with Model Adapter
Ensemble Multiple Models
To enhance the prediction ability, we build multiple derivative models based on the SIHG4SR architecture (Figure 7). These sub-models are created by tuning training strategies, data sampling, node setting, edge dropping strategies, and readout and fusion configurations. Finally, we proposed four sub-models named as SIHG4SR_V1, SIHG4SR_V2, SIHG4SR_V3, and SIHG4SR_V3_enhanced. We use a two-level ensemble strategy and weighted sum the predictions from four models, which significantly helps to reduce the generalization error of a single model.
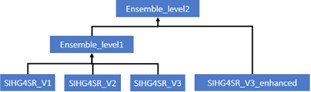
Figure 7. Model ensemble
Summary
The RecSys Challenge 2022 was a session-based recommender problem that provided an anonymized dataset to participants. The session data can be either represented with tables or graphs, and we found deep learning models show better predicting capability than machine learning methods. Our solution has four key contributions:
- SIHG4SR, a heterogeneous GNN-based model that fuses side information for the session-based recommender problem
- A feature engineering strategy that adds/removes nodes/edges in the graph to improve accuracy
- The Intel End to End AI Optimization Kit to do hyperparameter tuning and transfer learning
- A multi-level ensemble strategy to take advantage of multiple models.
This approach achieved a MRR of 0.20762, placing fourth overall.