With the Intel® oneAPI HPC Toolkit 2025.1 release, Intel® SHMEM moves from an active open-source GitHub project to also being a fully validated product release implementing an OpenSHMEM* 1.5 standard-compatible Partitioned Global Address Space (PGAS) programming model for remote data access and memory sharing in distributed multi-node compute environments.
The twist is that Intel SHMEM takes the OpenSHMEM communication API and extends it to not only distributed Intel® Xeon® Scalable processor configurations but also to System-wide Compute Language (SYCL*) based computational device kernels on Intel® GPUs. This turns it into an ideal companion library and API for Intel® Xeon® 6 compute clusters with SYCL device GPUs or high-performance large dataset applications running on supercomputers like the Aurora Exascale Supercomputer at the Argonne Leadership Computing Facility (ALCF) or the Dawn supercomputer at the Cambridge Open Zettascale Lab.
The difference to other such solutions built on OpenSHMEM is that unlike NVSHMEM* and ROC* SHMEM, Intel SHMEM’s SYCL extension, does not restrict users to any vendor-specific programming environment. SYCL is inherently multiarchitecture and multi-vendor-ready, which we believe aligns better with the spirit of an open API like OpenSHMEM. We feel that designed to be consistent with a portable programming environment, using SYCL makes a useful contribution to the expected standardization effort for GPU extensions to OpenSHMEM.
Software Architecture
Intel SHMEM implements a Partitioned Global Address Space (PGAS) programming model and includes most host-initiated operations in the current OpenSHMEM standard. It also includes new device-initiated operations callable directly from GPU kernels. The core set of features that Intel SHMEM provides are:
- Device and host API support for OpenSHMEM 1.5 compliant point-to-point Remote Memory Access (RMA), Atomic Memory Operations (AMO), signaling, memory ordering, and synchronization operations.
- Device and host API support for collective operations aligned with the OpenSHMEM 1.5 teams API.
- Device API support for SYCL work-group and sub-group level extensions for RMA, signaling, collective, memory ordering, and synchronization operations.
- A complete set of C++ function templates that supersede the C11 Generic routines in the current OpenSHMEM specification.
Let's discuss some of the implementation details of these features and how they are optimized for runtime performance.
The current OpenSHMEM memory model is specified from the perspective of the host memory being used by a C/C++ application. This limits the usage of GPU or other accelerator memories as symmetric segments without changes or amendments to the specification. The execution model also needs to be adapted to allow all processing elements (PE) to execute simultaneously, with a functional mapping of GPU memories being used as a symmetric heap by each PE. In the SYCL programming model, Unified Shared Memory (USM) allows memory from host, device, and shared address spaces. This may necessitate different communication and completion semantics based on the runtime's memory type.
Intel SHMEM is designed to deliver low latency and high throughput communications for a multi-node compute architecture with tightly coupled GPU devices supporting a SYCL API.
A critical challenge with the distributed programming of such a tightly coupled GPU system is simultaneously exploiting the high-speed unified fabric among the GPUs while also supporting off-node data communication. Additionally, SHMEM applications transfer messages with a wide variety of sizes, so the library must make quick and efficient decisions regarding which path among the GPU-GPU fabric, shared host memory, or the network is best for extracting the most performance possible given the message and the network sizes.
Also, suppose the data to be transferred is resident in GPU memory. In that case, it is advantageous to use a zero-copy design rather than copying the data to host memory and synchronizing the GPU and host memory upon data arrival. GPU-initiated communication is especially important with the advent of GPU remote direct memory access (RDMA) capabilities, which enable registration of GPU device memory for zero-copy transfers by the NIC but present a software engineering challenge when the feature is unavailable.
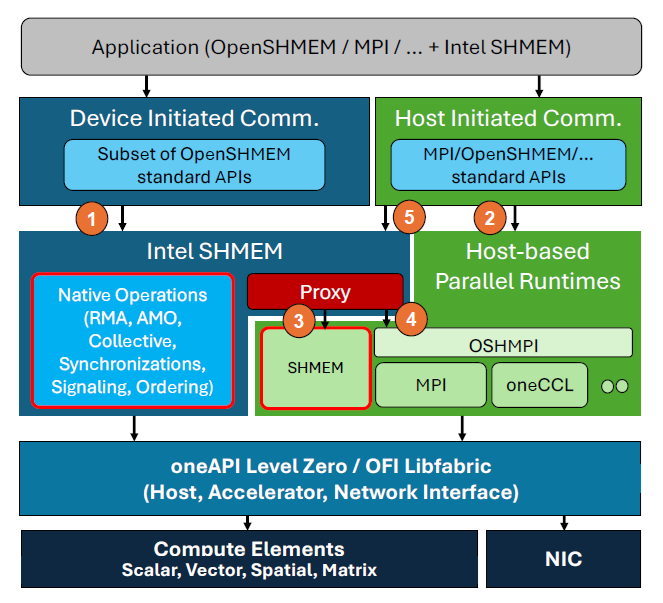
Fig. 1. Overview of Intel SHMEM Software Architecture
With these considerations in mind, let’s examine the Intel SHMEM software architecture. Figure 1's top shows the application layer, which consists of Intel SHMEM calls within an OpenSHMEM program (or an MPI program if interoperability with the host proxy backend is supported).
The Intel SHMEM APIs fall into two broad categories:
[1] device-initiated
[2] host-initiated
For inter-node (scale-out) communication, a host-side proxy thread leverages a standard OpenSHMEM library to hand off certain GPU-initiated operations, as shown in the circle [3]. This proxy backend need not be implemented as pure OpenSHMEM. For compatibility with MPI, an [4] OSHMPI solution would suffice while offering competitive performance. All the [5] host-initiated OpenSHMEM routines are available in Intel SHMEM, with the only caveat being the routines are prefixed with ishmem as opposed to shmem. While this naming scheme may not be strictly necessary, it has the advantage of distinguishing between the various OpenSHMEM-based runtimes that support GPU abstractions.
Within a local group of GPUs, Xe-Links permit individual GPU threads to issue loads, stores, and atomic operations to memory located on other GPUs. Individual loads and stores can provide very low latency. Many threads executing loads and stores simultaneously can greatly increase bandwidth but at the expense of using compute resources (threads) for communications.
To overlap computation and communications, the available hardware copy engines can be used, running Xe-Links at full speed while the GPU compute cores are busy with computation but at the cost of incurring a startup latency.
Intel SHMEM, in different operating regimes, uses all these techniques to optimize performance, doing load-store directly, load sharing among GPU threads, and using a cutover strategy to use the hardware copy engines for large transfers and non-blocking operations.
⇒ You can find a more detailed discussion in the following publication: Alex Brooks et al. (2024), Intel® SHMEM: GPU-initiated OpenSHMEM using SYCL, arXiv:2409.20476 [cs.DC]
Intel SHMEM Code Execution Flow
- Include the following header file:
- Initialize the ishmem library with an OpenSHMEM runtime:
- Query for the PE identifier and total number of PEs:
- Allocate some symmetric objects:
- Allocate source and destination buffers from within a parallel SYCL kernel:
- Perform a barrier operation to assure that all the source data is initialized before doing any communication:
- Perform a simple ring-style communication pattern; that is, have each PE send its source data to the subsequent PE (the PE with the largest identifier value will send to PE 0):
- After completion, perform another barrier operation to ensure all the communication is complete:
- free all allocated memory and finalize the library. For symmetric ishmem objects, we must call ishmem_free:
Device -Side Implementation
Intel SHMEM requires a one-to-one mapping of PEs to SYCL devices. This 1:1 mapping of PE to a GPU tile ensures a separate GPU memory space as a symmetric heap for the corresponding PE. For the proxy thread to support host-sided OpenSHMEM operations on a symmetric heap residing in GPU memory, the buffer must be registered with the FI_MR_HMEM mode bit set. For Intel SHMEM to indicate which region to register, GPU memory registers as a device memory region on an external symmetric heap, which is supported alongside the standard OpenSHMEM symmetric heap residing in host memory.
The interfaces are:
- shmemx_heap_create(base_ptr, size, ...)
- shmemx_heap_preinit()
- shmemx_heap_preinit_thread(requested, &provided)
- shmemx_heap_postinit()
Intel SHMEM strives to support all the OpenSHMEM APIs. That said, some interfaces, such as the initialization and finalization APIs and all memory management APIs, must be called from the host only because only the host is well-suited to setting up the data structures that handle CPU/GPU proxy interactions and performing dynamic allocation of device memory.
On the other hand, most OpenSHMEM communication interfaces, including RMA, AMO, signaling, collective, memory ordering, and point-to-point synchronization routines, are callable from both the host and device with identical semantics.
New Features
The new Intel SHMEM release includes the complete Intel SHMEM specification detailing the programming model and supported API calls, with example programs, build and run instructions, and more.
You can target both device and host with OpenSHMEM 1.5 and 1.6 features, including point-to-point Remote Memory Access (RMA), Atomic Memory Operations (AMO), Signaling, Memory Ordering, Teams, Collectives, Synchronization operations, and strided RMA operations.
Intel SHMEM comes with API support on the device for SYCL work-group and sub-group level extensions of RMA, Signaling, Collective, Memory Ordering, and Synchronization operations and API support on the host for SYCL queue ordered RMA, Collective, Signaling, and Synchronization operations.
List of Key Recently Added Features
- Support for on_queue API extensions allowing OpenSHMEM operations to be queued on SYCL devices from the host. These APIs also allow users options to provide a list of SYCL events as a dependency vector.
- Support for OSHMPI. Intel® SHMEM can now be configured to run over OSHMPI with a suitable MPI back-end. More details are available at Building Intel® SHMEM.
- Support for Intel® SHMEM on Intel® Tiber™ AI Cloud. Please follow the instructions here.
- Limited support for OpenSHMEM thread models. Host API support for thread initialization and query routines.
- Device and host API support for vector point-to-point synchronization operations.
- Support for OFI Libfabric MLX provider-enabled networks via Intel® MPI Library.
- Updated specification with new feature descriptions and APIs.
- Improved larger set of unit tests covering functionality of the new APIs.
⇒ Check out the complete list of all supported Intel® SHMEM features here: Supported/Unsupported Features
Download Now
Intel® SHMEM is available standalone or as part of the Intel® oneAPI HPC Toolkit or in source at its’ GitHub* repository.
Give it a go and take multiarchitecture GPU-initiated remote data access and memory sharing in distributed multi-node networks to the next level!
Additional Resources
Articles
Documentation
- Documentation on GitHub*
- Release Notes
- System Requirements
- Get Started:
Code Samples