8/9/2024
Introduction
The demand for AI platforms that prioritize privacy is increasing, and the Prediction Guard large language model (LLM) platform running on an Intel® Gaudi® 2 AI accelerator is leading the way in meeting this need. LLMs are transforming industries by enabling powerful information extraction, chat, content generation, and automation applications. However, widespread enterprise adoption of LLMs remains slow because companies struggle to ensure data privacy and security without sacrificing accuracy and scalability. Prediction Guard has pioneered an LLM platform that addresses both these needs by hosting state-of-the-art, open source LLMs like Meta* Llama 3, Neural-Chat-7B, and DeepSeek. It does this in a privacy-conserving manner while seamlessly integrating output validations (for example, for factual consistency) and input filters (for example, for personally identifiable information [PII] and prompt injections).
To power their platform at scale, Prediction Guard has optimized the deployment of LLM inference on the latest Intel Gaudi 2 AI accelerators within Intel® Tiber™ Developer Cloud. This white paper details the work the Prediction Guard team did to unlock the massive performance capabilities of Intel Gaudi 2 AI accelerators for LLM applications.
Background
Companies can clearly see the value of integrating LLMs. However, to ensure that LLMs produce useful output, it is often necessary to integrate private, sensitive company data to "ground" and improve LLM outputs within domains relevant to the company. For example, a company might integrate existing support tickets and customer support messages into an LLM application to improve new LLM-generated customer responses. In another example, a healthcare company might integrate care guidelines or information about a customer's medical history to improve applications that provide decision support.
Because of this integration of private data, companies need to ensure that the LLMs they use are hosted in a secure, private manner. However, hosting LLMs in a low-latency, high-throughput, and cost-effective way is often prohibitively difficult. Companies can use local LLM systems, but these often sacrifice latency and high throughput in exchange for privacy. Alternatively, cloud-based model hosting platforms might enable scaling at a very high cost.
This hosting challenge can slow AI adoption. Even if a company figures out model hosting, LLMs could still introduce new concerns related to the accuracy of model outputs or new ways that privacy or security could be breached. It is possible for LLMs to generate text that is completely inaccurate (a phenomenon sometimes called hallucination), and, thus, it is necessary to somehow validate model outputs. Moreover, the inputs to LLMs could contain PII, which could leak into application outputs, or malicious instructions (called prompt injections).
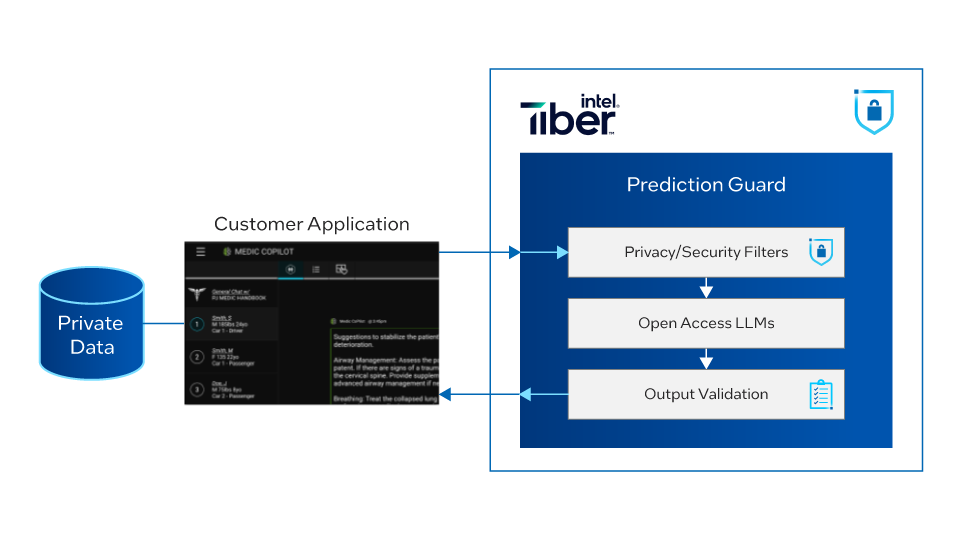
The Prediction Guard Platform
The Prediction Guard platform integrates best-in-class filters to detect and redact PII, block malicious prompts and toxic generations, and cross-check outputs against trusted data sources. Combined with hosting on price-performant, scalable Intel Gaudi 2 AI accelerators, this unlocks privacy-preserving LLM applications for enterprises across industries like finance, healthcare, legal, and more.
How Did Prediction Guard Achieve Success on Intel Gaudi 2 AI Accelerators?
Prediction Guard was an early pioneer in deploying LLM models on Intel Gaudi 2 AI accelerator instances in the Intel Tiber Developer Cloud and the first company to support paying customers using this configuration. Using the Optimum for Intel Gaudi libraries, NVIDIA* Triton* Inference Server, and insights from the Intel Gaudi product team, the key optimizations included are:
- Dynamic batching of inference requests
- Load balancing inference across model replicas on multiple Intel Gaudi 2 AI accelerators
- Optimizing and padding prompts to maintain static shapes between batches
- Tuning key-value (KV) caching and other hyperparameters based on Intel Gaudi AI accelerator guidance
Requests to the Prediction Guard system are dynamically batched with a maximum delay. This means that the server waits for up to a certain threshold of time for requests to come into the system. Requests that come in during this time are consolidated and run in a single batch. Prediction Guard API replicas are written concurrently in the Google Go* programming language and fan out requests as multiprompt requests are received. These fanned-out requests pass through a load balancer that spreads the requests out across multiple model replicas running on Intel Gaudi 2 AI accelerators.
Following is an example of dynamic batching using the PyTriton serving framework:
For optimal performance on an Intel Gaudi 2 AI accelerator, input shapes should remain static across and between batches. Prediction Guard implemented specialized logic to analyze a batch of prompts, pad them to a consistent length, and maintain static shapes even across dynamically batched requests from the NVIDIA Triton Inference Server.
One simple way of padding prompt inputs when running inference on Intel Gaudi 2 AI accelerators is to use padding to a maximum length parameter for the prompt. This, and other useful text generation functionality, is demonstrated in the Optimum for Intel Gaudi library examples on GitHub*.
See, for example:
Finally, Prediction Guard tuned the KV cache size, numerical precision, and other hyperparameters based on guidance from the Intel Gaudi product team. This allowed them to fully take advantage of the unique architecture of Intel Gaudi 2 AI accelerators.
Prediction Guard Hardware Setup
Prediction Guard model servers run on Intel Tiber Developer Cloud and Intel Gaudi 2 AI accelerator instances with the following specifications:
- Eight Intel Gaudi 2 AI accelerators for training
- Dual 3rd generation Intel® Xeon® Scalable processors
- Expanded networking capacity with 24x 100 Gb RoCE ports integrated into every Intel Gaudi 2 accelerator
- 700 GB per second scale within the server and 2.4 TB per second scale out
Ease of system build or migration with the Intel Gaudi software suite
Results
Prediction Guard optimizations for running LLM inference on Intel Gaudi 2 processors delivered breakthrough performance gains. When migrating their model servers from NVIDIA A100 Tensor Core GPUs to Intel Gaudi 2 AI accelerator deployments, they achieved up to 2x higher throughput for certain models like fine-tunes of Llama 2 and Mistral AI*.
Even more impressively, Prediction Guard demonstrated industry-leading latencies on their streaming end points powered by Intel Gaudi 2 AI accelerators. They recorded an average time-to-first-token of just 174 milliseconds for the Neural-Chat-7B model. This metric, which is critical for real-time applications like chatbots, matched or surpassed industry-leading cloud providers like Anyscale, Replicate*, and Together AI measured by LLMPerf benchmarks, with times ranging from 200 milliseconds up to 3.68 seconds for a Neural-Chat-7B model.
The LLMPerf benchmark suite evaluates LLM inference providers on two key metrics: output token throughput (for high-throughput use cases like summarization) and time-to-first-token (for streaming use cases). The Prediction Guard AI-accelerated platform using Intel Gaudi 2 processors delivered impressive performance on both fronts.
In addition to powering their enterprise customer applications, Prediction Guard validated their platform's scalability by supporting over 4,500 users across three major hackathons. These included Purdue University's Data 4 Good Case Competition with 1,000 students from a variety of US universities, Intel's Advent of GenAI Hackathon with 2,000 global developers, and the TreeHacks event at Stanford University with 1,500 students. Despite peak demands, Prediction Guard deployments on Intel Gaudi 2 processors handled the load seamlessly.
Conclusion
Prediction Guard has revolutionized the landscape of language AI by pioneering LLM deployments on Intel Gaudi 2 AI accelerators and meticulously implementing optimizations around batching, load balancing, static shaping, and hyperparameters. Through their commitment to innovation and efficiency, they have successfully unlocked performance and scalability levels previously unattainable. By seamlessly integrating data privacy measures with state-of-the-art LLM inference capabilities powered by Intel Gaudi 2 processors, Prediction Guard has positioned itself as the forefront leader in secure, high-performance language AI solutions tailored for enterprise adoption across various industries.