1 Introduction
Currently, Redis is the most popular NoSQL database in containers, and Kubernetes is the most popular orchestrator of containers. In this blog, we use resource management policy component provided by CRI-RM project based on container runtime interface (CRI) in a Kubernetes cluster to allocate resources within the node to accelerate Redis in containers. The CRI-RM component is an open-source project contributed by Intel, which is used to control resource allocation within the cluster node. We know that cloud service providers (CSP) usually offer CPU resources for Redis instances to customers, and the cost of CPU resources for an instance and the performance of the instance provided are critical for end user. for large CSPs with limited physical CPU resources, they may try to get the best performance on existing Redis instances. That is, running Redis on a traditional CPU server usually has poorer performance than the real capability of the CPU server provided, because the default CPU management of Kubernetes does not fully consider the affinity between CPU binding and NUMA. Newer versions of Kubernetes only take effect on pods whose QoS is guaranteed. Using native Kubernetes CPU management capabilities may have the following limitations:
- For scenarios where the Kubernetes version cannot be upgraded, CPU binding and NUMA affinity cannot be used.
- CPU binding and NUMA affinity by upgrading to a newer version of Kubernetes are available, but not enough to align real hardware topology, like Intel Xeon platform.
- The CPU manager and topology manager codes are integrated in the Kubelet component, which are not easy to expand and customize development.
2 Description
We are doing a lab practice for Redis solution based on CPU and CRI-RM resource management policy. By combining a Kubernetes cluster with CRI-RM, we got performance improvement in CPU scenarios and improved Input/Output Operations Per Second (IOPS) by more than 30%. This blog mainly introduces the Redis acceleration practice combined with CRI-RM in the Kubernetes cluster. Integrating the cri-resource-manager component in a Kubernetes cluster can realize the optimal allocation of physical hosts resource according to the topology resources in the Kubernetes cluster. Using this designed method to improve the performance of Redis on Kubernetes has the following advantages:
- The solution is decoupled from the Kubernetes source code and can be customized per demand. Without upgrading the Kubernetes version, CPU binding and NUMA affinity can be achieved through a simple configuration.
- The CRI-RM component enriches the resource topology view of the physical nodes. It will collect more topology information for resource scheduling.
2.1 Deploy
CRI-RM’s deployment contains three steps:
- Download the rpm package;
- Install the CRI-RM plugin on all k8s nodes, including both work and control nodes;
- Modify kublet parameters to include CRI-RM and restart kubelet.
For the topology aware policy, the above three steps are enough.
2.2 Overall architecture
Figure 2-1 illustrates the architecture of Redis with CRI-RM on Kubernetes. CRI-RM is a pluggable add-on for controlling how much and which type of resources are assigned to containers in a Kubernetes cluster. It is an add-on because you install it in addition to the normal selection of your components. It is pluggable since you inject it on the signaling path between two existing components with the rest of the cluster unaware of its presence. CRI-RM plugs in between the Kubernetes node agent (kubelet) and the container runtime running on the node (such as Containerd or CRI-O-o). It intercepts CRI protocol requests from the kubelet by acting as a non-transparent proxy towards the runtime. Proxying by CRI-RM is non-transparent in nature because it usually alters intercepted protocol messages before forwarding them.
CRI-RM keeps tracking the states of all the containers which are running on a Kubernetes node. Whenever it intercepts a CRI request that results in changes to the resource allocation of any container (container creation, deletion, or resource assignment update request), CRI-RM runs with one of its built-in policy algorithms. Users or Developers decide to select policies according to their use cases. The policy decides how the assignment of resources to containers to be updated. The policy can make changes to any container in the system, not just the one associated with the intercepted CRI request. After the policy has made its decision, any messages necessary to adjust affected containers in the system are sent, the intercepted request is modified according to the decisions, and is relayed.
The topology-aware policy optimizes workload placement in the node by using a detailed model of the actual hardware topology of the system. The goal of it is to give measurable benefits in an automated manner with minimal input required from the user point of view, while still enabling flexible user controls for fine-grained tuning where required. The policy automatically detects the hardware topology of the system and based on that, builds a fine-grained tree of resource pools from which resources are allocated to containers. The tree corresponds to the memory and CPU hierarchy of the system.
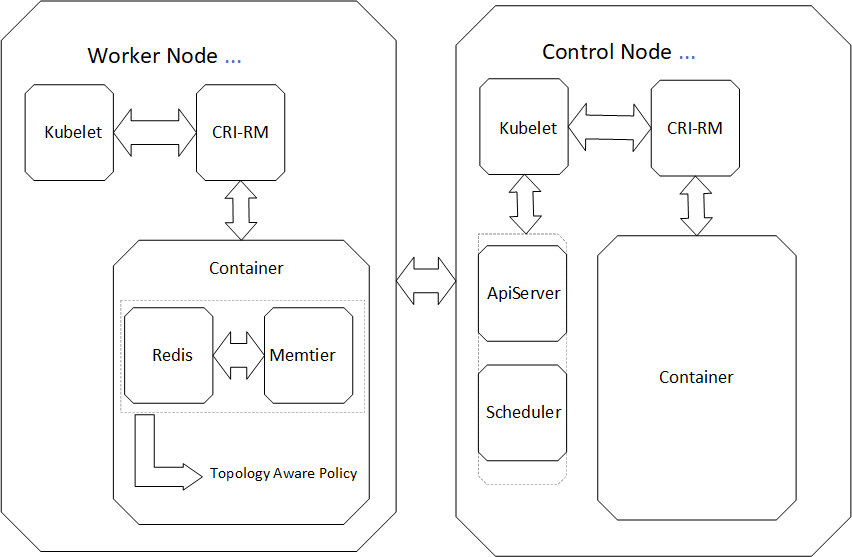
Redis and memtier are running inside the containers of two different pods. By adding some code changes to the yaml file that describes the memtier pod, the topology aware policy is applied to both Redis and memtier pods.
2.3 Detailed deployment steps
CRI-RM’s detailed deployment steps are shown below:
1. Prepare a K8S cluster with two nodes:
- Node1: worker node
- Node2: control node
2. Deploy CRI-RM to each node of the Kubernetes cluster:
- Download the CRI-RM rpm package from https://github.com/intel/cri-resource-manager/releases/download
- Install the CRI-RM rpm package: rpm -ivh cri-resource-manager-0.6.0-0.centos-7.x86_64.rpm
- Install the fallback config file: cp /etc/cri-resmgr/fallback.cfg.sample /etc/cri-resmgr/fallback.cfg
- Start the CRI-RM service: sudo systemctl enable cri-resource-manager && sudo systemctl start cri-resource-manager
3. Modify /etc/kubernetes/kubelet.env as shown in Figure 2-2 below.
Figure 2-2 Content of /etc/kubernetes/kubelet.env
4. Restart kubelet: systemctl restart kubelet
5. Apply the topology aware policy to memtier.yaml by adding the code shown in Figure 2-3
Figure 2-3 Content of memtier.yaml
6. Modify redis.yaml, set “replicas” to “1”, and change the “resource” field.
Figure 2-4 Content of redis.yaml
7. Run the Redis and memtier pods and start the all_run.sh script, which triggers the memtier benchmark.
Figure 2-5 Content of all_run.sh
3 Results and discussion
With the memtier benchmark tool running with all_run.sh, the result of Redis’s performance is shown in Figure 3-1:
Figure 3-1 Result of memtier
As a result, the IOPS of Redis improved by more than 30%, and latency improved by 20%. Those improvements come from CRI-RM’s behavior when allocating CPU cores for the Kubernetes pod. With CRI-RM, Kubernetes allocates all the CPU cores and memory of Redis and memiter pods from the same socket, socket #1 of a two-socket server. It binds Redis and memtier to the same NUMA node and gets the best performance.
Figure 3-2 Log of CRI-RM
Figure 3-2, displaying the content of the CRI-RM log, shows that Redis uses CPU 24-27, 72-75 of socket #1, memtier uses CPU 28-31, 76-79 of socket #1, and both run at the same socket.
4 Conclusion and future plans / use
CRI-RM definitely can accelerate the workload performance on a Kubernetes cluster. In the future, we plan to practice other policies such as the “static pool policy”, to use CRI-RM to control other hardware resources, such asL3 cache, and to combine with Intel® Resource Director Technology (Intel® RDT) to get how much performance improvement and any other benefits for Cloud workloads. We may also use CRI-RM to accelerate not just IMDB workloads, but other types of workloads, such as AI and others.
5 References
[1] https://en.wikipedia.org/wiki/Redis
[2] https://www.intel.com/content/www/us/en/partner-alliance/membership/benefits/partners-ai.html
[3] https://github.com/intel/cri-resource-manager