Ceph also provides the RADOS block device (RBD), the RADOS gateway (RGW) and the Ceph File System (CephFS). The architecture of Ceph is shown in Figure 1. RBD interfaces are a mature and common way to store data on media including HDDs, SSDs, CDs, floppy disks, and even tape.
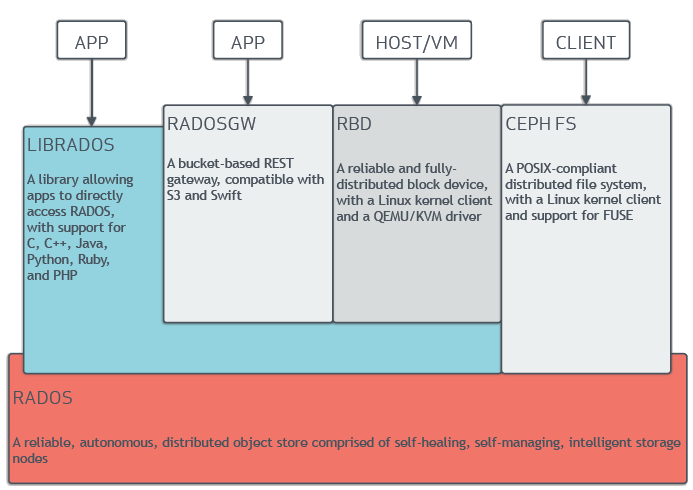
Librbd is a library that Ceph provides for block storage. It implements the RBD interface. The upper application like fio and Software Performance Development Kit (SPDK), can operate the Ceph cluster by calling the interfaces of librbd and librados, including creating and deleting pool/image, reading/writing data, etc. Figure 2 shows the thread model of RBD and the code flow.

Ceph performance tuning
Single image IO bottleneck of Ceph RBD
Fio, as a testing tool, is usually used to measure cluster performance. In our fio test, we found the results of a single image is much lower than multiple images with a high performance Ceph cluster. For example, the performance ceiling of the cluster is about 500K IOPs write performance. However, when we set one image to test write performance in a fio job and increase io-depth to remove the possible performance bottleneck, the result of the performance ceiling may be only 100k. While fio writes eight images at the same time, IOPS may reach 450k in total, which is close to the performance ceiling of the cluster.
Why is the performance of writing a single image so poor? From the analysis of the underlying storage of the cluster, even a single image is divided into many small objects, hashed to placement groups (PGs), and finally actually stored on each disk of the storage node. So, a single image will not cause a bottleneck on the cluster side. On the client side, “htop” or “top -H -p pid” gives visual information about threads, CPU usage, and memory status. Therefore, we can check the resource status of the threads that are created by fio via the commands shown in Figure 3. We can see that reading/writing an image generates 15 RBD threads. But we can ignore the threads when the CPU occupation time < 1s.
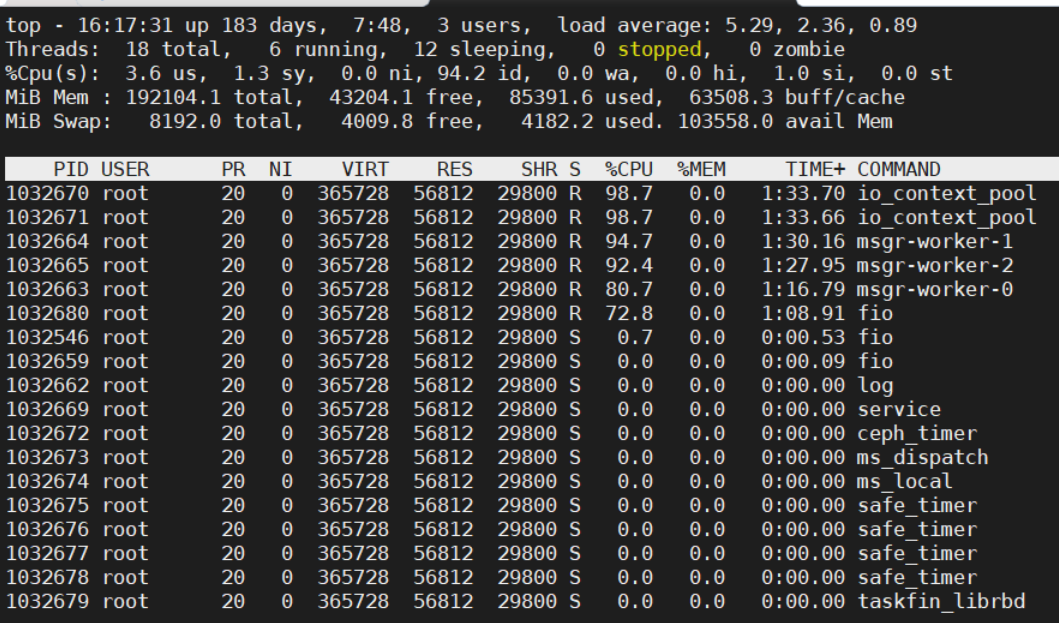
After ignoring the threads whose “TIME+” are almost 0, we focus on the threads named fio, io_context_pool and msgr-worker-x. Fio is an application thread that sends IO requests to RBD. The number of fio threads is determined by the “numjobs” parameter in the configuration. In Figure 3, the fio thread CPU utilization is less than full at 72.8%. If the fio thread were fully utilized, it would become a bottleneck and the “numjobs” parameter would need to be increased. Msgr-worker-x threads are the message threads of RBD. Through these threads, RBD sends encapsulated IO messages to the cluster, accepts replies, and handles them. Io_context_pool threads handle the IOs from application (fio thread here), encapsulates them as objects, then puts them in the queue of the msgr-worker-x threads. The io_context_pool threads in Figure 3 show nearly 100% CPU utilization, which causes a bottleneck.
After introducing the threads of io_context_pool and msgr-worker-x, you can adjust the number of these two kinds of threads to solve the bottleneck problem caused by a single image. Two Ceph configuration parameters, “librados_thread_count” and “ms_async_op_threads”, can adjust the number of io_context_pool and msgr-worker-x threads.
Multi images IO methods of Ceph RBD
The following steps comprise an implementation of fio calling the RBD interface to realize reading and writing.
- r = rados_create(&rbd->cluster, o->client_name);
- r = rados_connect(rbd->cluster);
- r = rados_ioctx_create(rbd->cluster, o->pool_name, &rbd->io_ctx);
- r = rbd_open(rbd->io_ctx, o->rbd_name, &rbd->image, NULL /*snap */);
- read, write, flush.
In step 2, in the process of connecting to the cluster, the threads are created, including io_context_pool and msgr-worker-x. For multiple images, the applications have two ways to read and write images.
If the same RADOS object is used and connected only once, the threads created by this connection will be shared by the read and write operations of multiple images. That is, execute steps 1 and 2 once, and execute steps 3 and 4 repeatedly, such as: 1->2->3->4->3->4.
If each image is read and written, a RADOS object must first be created. Then, the object is connected. When the object is connected for reading and writing multiple images, the threads are created. That is, steps 1, 2, 3, and 4 must be performed once for each image. Such as: 1->2->3->4->1->2->3->4.
Fio adopts the method of not sharing threads. Each fio job creates a new RADOS object and then creates the threads when connecting. In this way, the tasks of handling IO and sending messages is distributed to enough threads, and the CPU utilization of threads will not become a bottleneck. However, if there are too many threads and the CPU utilization rate of every thread is low, it still leads to performance degradation, and it is difficult to approach the performance ceiling of the cluster. This is because thread creation, switching, communication, synchronization, etc. consumes resources. More threads are not better. For example, if there are 500 images in the cluster and a client wants to access them at the same time, 2500 resident RBD threads will be generated by default by using the method of not sharing threads. This is disastrous for CPUs. Therefore, in a large-scale scenario, it is more reliable for a single client application to share threads. This is mainly determined by the implementation of the applications.
SPDK RBD bdev performance tuning
The Storage Performance Development Kit (SPDK[2]) provides a set of tools and libraries for writing high performance, scalable, user-mode storage applications. SPDK RBD bdev provides SPDK block layer access to Ceph RBD via librbd. In that case, the Ceph RBD images could be converted into a block device (bdev) that is defined by SPDK and used by various SPDK targets (such as SPDK NVMe-oF target, vhost-user target, and iSCSI target) to provide block device services for client applications. Figure 4 shows the call stack of SPDK.
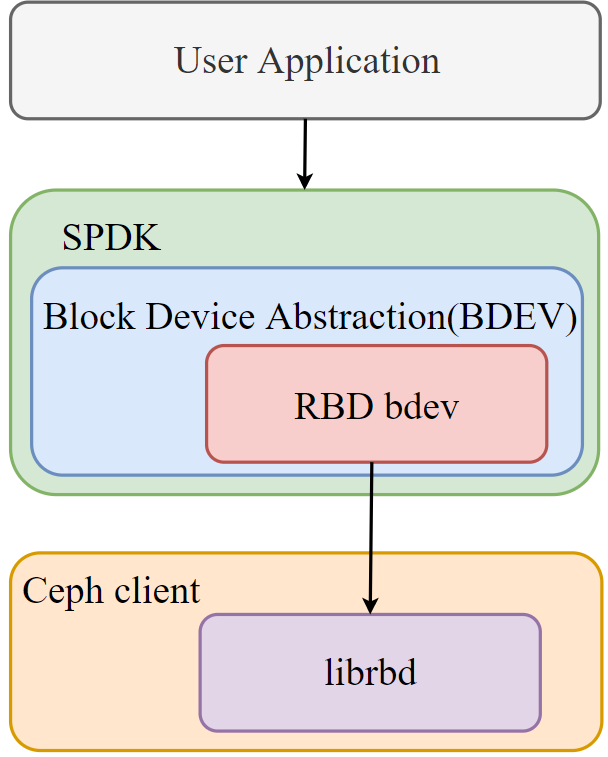
Unlike fio, SPDK provides two ways of creating an RBD bdev. One is to create a new RADOS object for each RBD bdev. Another is to share the same RADOS object for multiple RBD bdevs. Figure 5 and Figure 6 show the differences between the two types, respectively. As mentioned before, for a large number of image scenarios, it is very important to configure an application with a sharing threads mode since it can reduce the number of threads and improve the performance. But customers need to specify a suitable threads number via their experience or by testing. A simple way is to check the CPU utilization of threads through “htop” and find a suitable number of threads that approaches full utilization.


In large-scale scenarios, scalability needs to be considered. The number of images is not immutable. When you add images, you need to add an appropriate number of threads so that the CPU utilization of threads will not become a bottleneck. When the number of images is reduced, too many threads waste resources and even degrades performance. We take SPDK as an example to propose the optimization strategy of grouping, as shown in Figure 7.
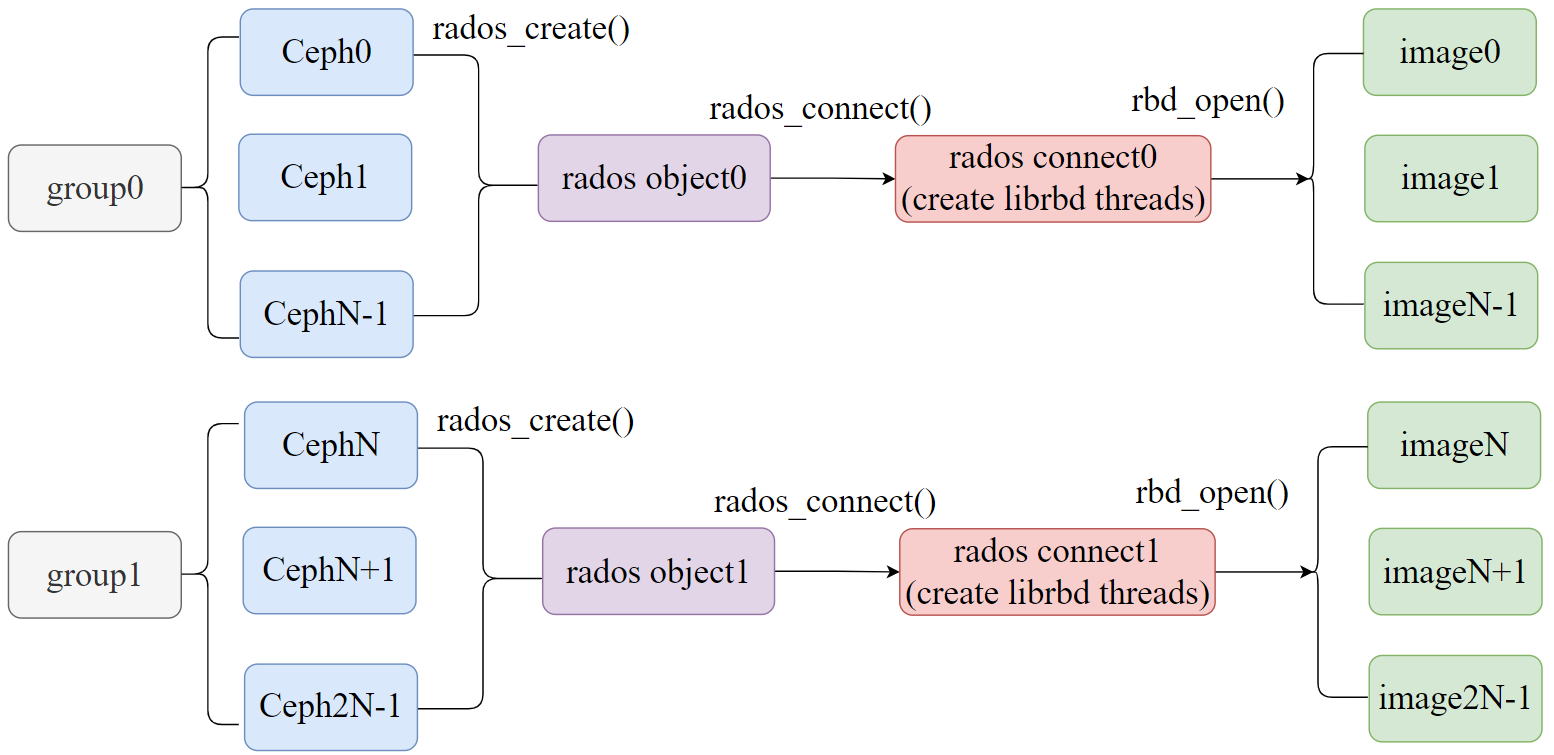
We first set the number of images in a group, such as 50 images, and divide 500 images into 10 groups. Through performance testing and “htop”, we can get the optimal number of threads in a group. When we want to add more images or scale the cluster, we only need to add new groups and follow the previous configuration to add the new images to the new groups. In this way, the optimal number of threads can be used.
Conclusion
In this article, we analyzed the threads model of Ceph and the method of application calling RBD inter-face at first and summarized some performance bottlenecks of Ceph RBD next. Finally, we introduced SPDK to further analyze multiple ways to access RBD image, achieve performance tuning, and provide better scalability solutions.
References
1. https://docs.Ceph.com/en/latest/architecture/
2. https://spdk.io/