By Louie Tsai
Starting with the TensorFlow* v2.9 release, Intel® Optimization for TensorFlow* has the oneDNN library optimizations turned on by default on AWS instance types such as C6i and C5 with 2nd or 3rd Gen Intel Scalable Processors. These oneDNN optimizations from TensorFlow v2.9 can provide up to a 3X out-of-box performance improvement over v2.8 where you would need to enable these optimizations manually to see similar performance improvements. Because these optimizations are enabled by default in TensorFlow v2.9, you’ll notice improved performance over the out-of-box performance of v2.8.
We benchmarked several popular TensorFlow models from Model Zoo for Intel® Architecture on inference, and compared out-of-box results using official TensorFlow 2.9 (Stock TF 2.9) and 2.8 on AWS C6i instance types powered by 3rd generation Intel® Xeon® Scalable Processor and C6a instance type powered by 3rd generation AMD EPYC Processors.
Inference was benchmarked using AWS c6i.2xlarge or c6a.2xlarge instance type for latency measurement and using AWS c6i.12xlarge or c6a.12xlarge instance type for throughput measurements.
Among different CPU instance types such as C6a with AMD EPYC and different TensorFlow optimization such as ZenDNN, the best performances from our benchmarking are achieved with Intel C6i instance type from TensorFlow v2.9.
Refer to this article for further performance optimizations in TensorFlow v2.8.
Throughput Improvement from Official TensorFlow* 2.8 to 2.9
We benchmarked different models on AWS c6i.12xlarge instance type with 24 physical CPU cores and 96 GB memory on a single socket.
Table 1 and Figure 1 show the related out-of-box performance improvement from v2.9 compared to v2.8 for inference across a range of models for different use cases. With v2.9, the oneDNN optimizations are enabled by default. You’d see similar performance optimizations if you manually enabled them in v2.8. For offline throughput measurement (using large batches), performance improvements are up to 3X, and performance boost varies among models. Most image recognition models achieve about a 2X performance boost, and language modeling model has a nearly 1.4X performance boost.
|
Use Case |
Model |
Batch Size |
|---|---|---|
| Image Recognition | resnet50v1.5 | 128 |
| resnet50 | 128 | |
| resnet101 | 128 | |
| densenet169 | 100 | |
| inceptionv3 | 128 | |
| inceptionv4 | 240 | |
| mobilenet | 100 | |
| Language Modeling | bert base | 32 |
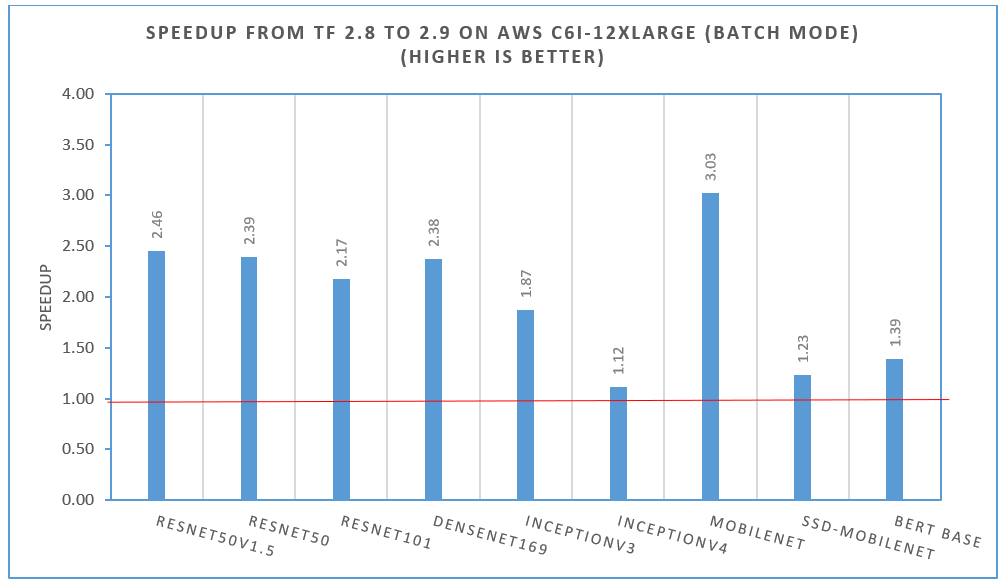
Latency Performance Improvement from Official TensorFlow* 2.8 to 2.9
We benchmarked different models on AWS c6i.2xlarge instance type with 4 physical CPU cores and 8 GB memory on a single socket.
For out-of-box real-time inference (batch size =1), the TensorFlow* v2.9 with oneDNN-enabled by default was faster, and performance improvements are up to 1.47X compared to TensorFlow* v2.8.

Throughput Improvement for int8 Models with Official TensorFlow* 2.9
In TensorFlow 2.9, Intel® DL Boost support for int8 model is enabled by default.
Figure 3 show the related out-of-box performance improvement on Official TensorFlow* 2.9 for inference with low precision data types across a range of models. For offline throughput measurement (using large batches), performance improvements are up to 3.5X with int8 data type compared to fp32 data type on the AWS c6i.12xlarge instance type.

Performance Improvement from 3rd Gen AMD EPYC to 3rd Gen Intel® Xeon®
Throughput Improvement
On Official TensorFlow* 2.8 and 2.9
We benchmarked different models on AWS c6a.12xlarge (3rd Gen AMD EPYC) and c6i.12xlarge (3rd Gen Intel® Xeon® Processor) instance type with 24 physical CPU cores and 96 GB memory on a single socket with both official TensorFlow* v2.8 and v2.9.
C6i.12xlarge uses 3rd Gen Intel® Xeon® scalable processors and C6a.12xlarge uses AMD 3rd Gen AMD EPYC processors.
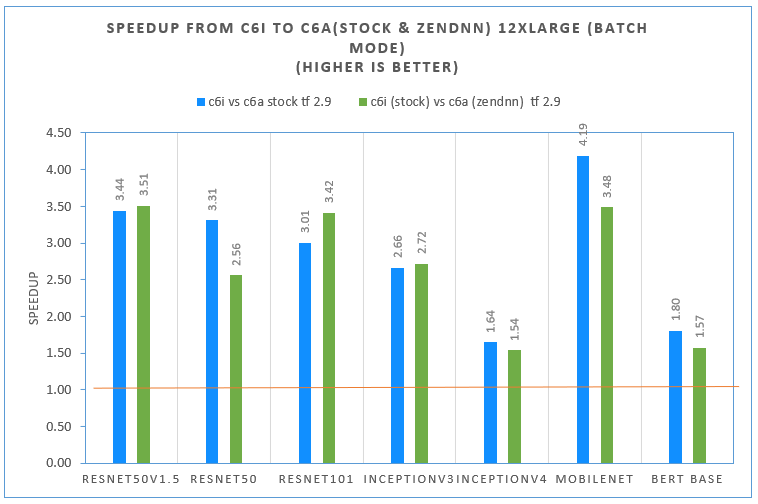
Figure 4 shows the related out-of-box performance improvement from c6i.12xlarge (3rd gen Intel® Xeon® processor) compared to c6a.12xlarge (AMD 3rd Gen EPYC) for inference across a range of models for different use cases on both TensorFlow v2.8 and v2.9.
For offline throughput measurement (using large batches) on TensorFlow v2.8 without oneDNN enabled, performance improvements (shown as orange bars) are up to 1.46X on c6i.12xlarge compared to c6a.12xlarge. Performance boost varies among models.
For offline throughput measurement (using large batches) on TensorFlow v2.9 with oneDNN enabled by default, performance improvements (shown as blue bars) show up to a 4X improvement on c6i.12xlarge compared to c6a.12xlarge. There’s a much higher speedup on c6i12xlarge compared to c6a.12xlarge if users update their TensorFlow* version from v2.8 to v2.9. The oneDNN optimizations enabled by default provide most of this performance boost.
Overall, 3rd Gen Intel® Xeon® processor instance types outperform AMD 3rd gen EPYC instance types on both TensorFlow* v2.8 and v2.9. Users could see an even higher speedup if they update TensorFlow* version from v2.8 to v2.9.

On Official TensorFlow* 2.9 and TensorFlow* 2.9 + ZenDNN
ZenDNN library targets deep learning application and framework developers with improved deep learning inference performance on AMD CPUs. To maximize TensorFlow* performance on the 3rd gen AMD EPYC, we also benchmarked c6a.12xlarge with TensorFlow* v2.9 optimized by ZenDNN v3.3.
We benchmarked different models on AWS c6i.12xlarge and c6a.12xlarge instance type with 24 physical CPU cores and 96 GB memory on a single socket.
C6i.12xlarge uses 3rd Gen Intel® Xeon® scalable processors and C6a.12xlarge uses AMD 3rd Gen AMD EPYC processors.
Figure 5 shows the related out-of-box performance improvement from c6i.12xlarge (3rd Gen Intel® Xeon® processor) compared to c6a.12xlarge (AMD 3rd Gen EPYC) for inference across a range of models for different use cases on both official TensorFlow v2.9 and TensorFlow v2.9 + ZenDNN.
For offline throughput measurement (using large batches) on TensorFlow v2.9 with oneDNN enabled by default, performance improvements (shown as blue bars) are up to 4X on c6i.12xlarge compared to c6a.12xlarge. Performance improvements (shown as green bars) are up to 3.48X on c6i.12xlarge with official TensorFlow* v2.9 compared to c6a.12xlarge with TensorFlow v2.9 + ZenDNN. We saw a little less performance speedup from c6a to c6i for those runs (shown as green bars) due to more performance with TensorFlow + ZenDNN on AMD 3rd gen EPYC c6a.12xlarge instance.
Overall, 3rd Gen Intel® Xeon® processor instance types outperform AMD 3rd gen EPYC instance types even using TensorFlow v2.9 + ZenDNN on AMD 3rd gen EPYC ca6.12xlarge instance.
On Official TensorFlow* v2.9, TensorFlow* v2.9 + ZenDNN, and Intel® Optimization for TensorFlow* v2.9
Intel® Optimization for TensorFlow* is a ready-to-run optimized solution that uses oneAPI Deep Neural Network Library (oneDNN) primitives, and it uses OpenMP for multithreading instead of default eigen thread in official TensorFlow. With proper OpenMP settings, Intel® Optimization for TensorFlow* could give even better performance than official TensorFlow* with oneDNN enabled by default.
We benchmarked different models on AWS c6i.12xlarge and c6a.12xlarge instance type with 24 physical CPU cores and 96 GB memory on a single socket.
C6i.12xlarge uses 3rd Gen Intel® Xeon® scalable processors and C6a.12xlarge uses AMD 3rd Gen AMD EPYC processors.
Figure 6 shows the related out-of-box performance improvement from c6i.12xlarge (3rd Gen Intel® Xeon® processor) compared to c6a.12xlarge (AMD 3rd Gen EPYC) for inference across a range of models for different use cases on official TensorFlow v2.9, TensorFlow v2.9 + ZenDNN and Intel® Optimization for TensorFlow* v2.9.
For offline throughput measurement (using large batches), performance improvements (shown as green bars) are up to 3.48X on c6i.12xlarge with official TensorFlow v2.9 compared to c6a.12xlarge with TensorFlow v2.9 + ZenDNN. Performance improvements (shown as dark blue bars) are up to 3.89X on c6i.12xlarge with Intel® Optimization for TensorFlow* v2.9 compared to c6a.12xlarge with TensorFlow v2.9 + ZenDNN.
We saw more performance speedup from c6a to c6i for those runs (shown as dark blue bars) due to more performance with Intel® Optimization for TensorFlow* v2.9 than official TensorFlow v2.9 on Intel 3rd gen Xeon processor c6i.12xlarge instance.
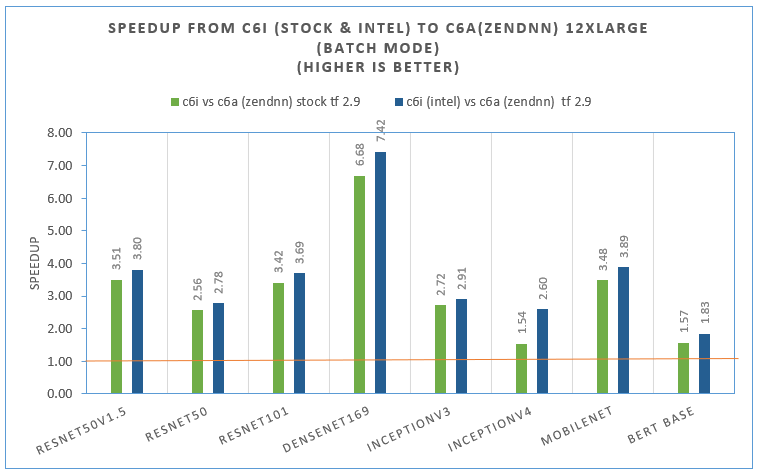
Table 2 shows the related out-of-box throughput performance improvement on different TensorFlow versions and distributions from 3rd Gen Intel® Xeon® processor c6a.12xlarge instance type over AMD 3rd Gen c6a.12xlarge instance type.
|
Use case |
Model |
c6i vs c6a stock tf 2.8 |
c6i vs c6a stock tf 2.9 |
C6i (stock) vs c6a (zendnn) tf 2.9 |
c6i (Intel) vs c6a (zendnn) tf 2.9 |
|---|---|---|---|---|---|
| Image Recognition | resnet50v1.5 | 1.39 | 3.44 | 3.51 | 3.80 |
| Image Recognition | resnet50 | 1.38 | 3.31 | 2.56 | 2.78 |
| Image Recognition | resnet101 | 1.39 | 3.01 | 3.42 | 3.69 |
| Image Recognition | densenet169 | 1.45 | 3.45 | 6.68 | 7.42 |
| Image Recognition | inceptionv3 | 1.42 | 2.66 | 2.72 | 2.91 |
| Image Recognition | inceptionv4 | 1.46 | 1.64 | 1.54 | 2.60 |
| Image Recognition | mobilenet | 1.40 | 4.19 | 3.48 | 3.89 |
| Language Modeling | bert base | 1.33 | 1.80 | 1.57 | 1.83 |
Latency Performance Improvement
On Official TensorFlow* 2.8 and 2.9
We benchmarked different models on AWS c6i.2xlarge and c6a.2xlarge instance type with 4 physical CPU cores and 8 GB memory on a single socket with both official TensorFlow v2.8 and v2.9.
C6i.2xlarge uses Intel 3rd Gen Intel® Xeon® scalable processors and C6a.2xlarge uses AMD 3rd Gen AMD EPYC processors.
Figure 7 shows the related out-of-box performance improvement from c6i.2xlarge (3rd Gen Intel® Xeon® processor) compared to c6a.2xlarge (AMD 3rd Gen EPYC) for inference across a range of models for different use cases on both TensorFlow v2.8 and v2.9.
For out-of-box real-time inference (batch size =1), on TensorFlow v2.8 without oneDNN enabled by default, performance improvements (shown as orange bars) are up to 1.1X on c6i.2xlarge compared to c6a.2xlarge, and performance boost varies among models.
For out-of-box real-time inference (batch size =1) on TensorFlow v2.9 with oneDNN enabled by default, performance improvements (shown as blue bars) are up to 1.65X on c6i.2xlarge compared to c6a.2xlarge. There is a larger speed-up on c6i2xlarge compared to c6a.2xlarge if users update their TensorFlow version from v2.8 to v2.9. Having oneDNN optimizations enabled by default provides most of this performance boost.

On Official TensorFlow* 2.9 and TensorFlow* 2.9 + ZenDNN
Figure 8 shows the related out-of-box performance improvement from c6i.2xlarge (3rd gen Intel® Xeon®) compared to c6a.2xlarge (AMD 3rd Gen EPYC) for inference across a range of models for different use cases on both official TensorFlow* v2.9 and TensorFlow* v2.9 + ZenDNN.
For out-of-box real-time inference (batch size =1) on TensorFlow* v2.9 with oneDNN enabled by default, performance improvements (shown as blue bars) are up to 1.65X on c6i.2xlarge compared to c6a.2xlarge. Performance improvements (shown as green bars) are up to 1.56X on c6i.2xlarge with official TensorFlow v2.9 compared to c6a.2xlarge with TensorFlow v2.9 + ZenDNN. We saw a little less performance speedup from c6i over c6a for those runs (shown as green bars) due to more performance with TensorFlow + ZenDNN on AMD 3rd gen EPYC c6a.2xlarge instance.

On Official TensorFlow* 2.9, TensorFlow* 2.9 + ZenDNN, and Intel® Extensions for TensorFlow* v2.9
Figure 9 shows the related out-of-box performance improvement from c6i.2xlarge (3rd Gen Intel® Xeon® processor) compared to c6a.2xlarge (AMD 3rd Gen EPYC) for inference across a range of models for different use cases on official TensorFlow v2.9, TensorFlow v2.9 + ZenDNN and Intel® Optimization for TensorFlow* v2.9.
For out-of-box real-time inference (batch size =1), performance improvements (shown as green bars) are up to 1.56X on c6i.2xlarge with official TensorFlow v2.9 compared to c6a.2xlarge with TensorFlow v2.9 + ZenDNN. Performance improvements (shown as dark blue bars) are up to 2X on c6i.2xlarge with Intel® Optimization for TensorFlow* v2.9 compared to c6a.2xlarge with TensorFlow v2.9 + ZenDNN.
We saw more performance speedup from c6i over c6a for those runs (shown as dark blue bars) due to more performance with Intel® Optimization for TensorFlow* v2.9 than official TensorFlow* v2.9 on Intel 3rd gen Xeon processor c6i.2xlarge instance.

Table 3 shows the relative out-of-box real-time latency performance improvement on different TensorFlow versions and distributions from Intel 3rd Gen Xeon processor c6a.2xlarge instance type over AMD 3rd Gen c6a.2xlarge instance type.
|
Use case |
Model |
c6i vs c6a stock tf 2.8 |
c6i vs c6a stock tf 2.9 |
c6i (stock) vs. c6a (ZenDNN) tf v2.9 |
c6i (Intel) vs. |
|---|---|---|---|---|---|
| Image Recognition | resnet50v1.5 | 1.10 | 1.65 | 1.53 | 2.02 |
| Image Recognition | resnet50 | 1.10 | 1.51 | 1.37 | 1.87 |
| Image Recognition | resnet101 | 1.11 | 1.63 | 1.56 | 1.92 |
| Image Recognition | densenet169 | 1.07 | 1.26 | 1.17 | 1.33 |
| Image Recognition | inceptionv3 | 1.08 | 1.48 | 1.17 | 1.45 |
| Image Recognition | inceptionv4 | 1.11 | 1.15 | 1.04 | 1.51 |
In summary, the oneDNN optimizations from TensorFlow v2.9 can provide up to a 3X out-of-box performance improvement over v2.8 where you would need to enable these optimizations manually to see similar performance improvements,.
Moreover, among different CPU instance types such as C6a with AMD EPYC and different TensorFlow optimization such as ZenDNN, the best performances from our benchmarking are achieved with Intel C6i instance type from TensorFlow* v2.9.