Learn how Modin* helps you break through the performance bottlenecks of pandas DataFrame processing. We will show you how changing one line of code can reduce the amount of time you have to wait for data processing operations to finish, all without leaving the comfort of pandas behind.
Note All runtimes cited were measured using the same hardware, operating system, and software configuration. Details are at the end of the article.
Break the Single-core Limitation of pandas
Imagine you are writing a data preprocessing notebook using pandas, and you are not satisfied having to wait for over four minutes every time you run it. You start measuring individual stages of the workload and see a picture, like in Table 1, with 97% of the workload spent performing a single operation, such as df.groupby(), df.apply(), or df.merge().
|
Operation |
Time (Seconds) |
Share of Time |
|
Reading and basic preprocessing |
1.034 |
0.39% |
|
groupby.apply(complex_aggregation) |
257.630 |
97.78% |
|
Prepare for fit/predict |
1.736 |
0.66% |
|
Fit/predict |
2.645 |
1.00% |
|
Interpret results |
0.422 |
0.16% |
|
Total |
263.467 |
100.00% |
Table 1. A breakdown of pandas processing time for processing the customer segmentation dataset. The original notebook is available on Kaggle*.
pandas operations are limited to single-core processing. Most data scientists would rather not have to take on the complexity and manual effort of partitioning and merging the data for multiple parallel tasks. Modin offers a drop-in replacement for pandas with parallel implementations of its API. Simply change your import statement to start using Modin:

Figure 1. Code changes required to use Modin to speedup data processing for the customer segmentation workload.
|
Operation |
pandas Time (Seconds) |
Modin Time (Seconds) |
|
Reading and basic preprocessing |
1.034 |
6.184 |
|
groupby.apply(complex_aggregation) |
257.630 |
30.687 |
|
Prepare for fit/predict |
1.736 |
7.444 |
|
Fit/predict |
2.645 |
7.358 |
|
Interpret results |
0.422 |
3.278 |
|
Total |
263.467 |
54.951 |
Table 2. Measurements for the customer segmentation workload after changing the import statement from pandas to Modin (see code).
Using Modin for the same workload sped up the total turnaround time by 4.8x. This came from greatly speeding up the operation that was taking over 97% of the time in pandas. Now, instead of waiting for over four minutes every time you run this notebook, it's less than a minute. Larger datasets will result in even more time savings for you.
In comparison with other distributed DataFrame libraries, Modin covers more than 90% of the pandas API, so you typically don’t need to modify your pandas code to apply Modin. Note how Modin can process the following call to groupby even though it uses a complex custom aggregation function (see code) that was written specifically for pandas:
Although Modin provides speedups for compute-heavy operations, it is not a magic pill that makes everything faster. As a practice-based observation, the Modin implementation of a given method works faster if the operation takes longer than five seconds in pandas. This behavior is previously shown in Table 2, where certain parts of the workflow were slower with Modin.
If you find that Modin performs worse in certain parts of your workflow, just like in our example, you can engage Modin only in the parts where it is beneficial. In our case, it is the section with the groupby.apply() call. Wrapping it into Modin objects as shown in the following code sample delivers nearly a 7x speedup for this groupby without losing time in the parts of the workflow where pandas works better:
|
Operation |
pandas Time (Seconds) |
Modin Time (Seconds) |
Modin and pandas (Seconds) |
|
Reading and basic preprocessing |
1.034 |
6.184 |
1.034 |
|
groupby.apply(complex_aggregation) |
257.630 |
30.687 |
34.979 |
|
Prepare for fit/predict |
1.736 |
7.444 |
1.736 |
|
Fit/predict |
2.645 |
7.358 |
2.645 |
|
Interpret results |
0.422 |
3.278 |
0.422 |
|
Total |
263.467 |
54.951 |
40.816 |
Table 3. Measurements for the customer segmentation workload, comparing pandas versus Modin to Modin and pandas.
Even if Modin doesn’t have a parallel implementation for a specific method, it defaults to using pandas implementation for that method, and issues a warning in the process. This ensures that the workflow proceeds without interruption.
Speed Up a Sequence of Heavy pandas Operations
Modin can also be seamlessly integrated into a sequence of intensive operations within your workflow by converting only the required DataFrames to Modin. As already mentioned, Modin works far beyond groupby(), apply(), and other popular pandas methods, so any intermediate calls between heavy operations wouldn’t be a problem for Modin:
|
|
pandas |
Modin–Single Conversion Step |
Modin–Convert From/To pandas for Each Operation |
|
Runtime (seconds) |
296.23 |
71.74 |
97.48 |
Table 4. Runtime comparisons for a single conversion step to and from Modin, versus converting for each operation, versus running completely in pandas (see code).
While the previous workload requires nearly five minutes for pandas to complete, you can reduce it to about a minute and a half by converting the DataFrame from pandas to Modin for each operation. In this case, simply converting to Modin once for all operations saves you nearly four minutes each run, which is a speedup of over 4x.
When Not to Use Modin
Certain operations benefit more from parallelization than others. Due to its distributed nature, Modin might not outperform pandas in speed for some methods under specific circumstances.
For example, it was already mentioned that applying Modin for a certain operation is recommended only if it takes more than five seconds on pandas. The explanation is simple: The overhead of data distribution and parallel running is only justifiable when working on substantial tasks. A common example is an operation in a for-loop:
In the previous example, the whole loop takes about 80 seconds, however each iteration is simple and takes less than a second in pandas. What makes this loop slow is the number of iterations.
|
|
pandas |
Modin |
|
Time (in Seconds) for Each Loop Iteration |
0.007 |
0.090 |
|
Time (in Seconds) for the Entire for-loop |
79.28 |
904.80 |
Table 5. Runtime comparison of a single iteration of a for-loop, along with the cumulative runtime for all iterations (see code).
Modin can’t magically parallelize Python* for-loops because each iteration is run sequentially. Moreover, the overhead of sequentially distributing each tiny iteration would outweigh any speedup of the operation. To speed this up with Modin, you could rewrite the loop using the pandas API and apply Modin afterward:
|
|
pandas |
Modin |
|
Time (in Seconds) for the Entire for-loop |
79.280 |
904.80 |
|
Time (in Seconds) for groupby() and .apply() |
26.42 |
4.98 |
Table 6. Runtime comparison for the for-loop versus restructuring the code to use groupby() and .apply(). Note that pandas runtime improved with this restructuring, but Modin is over 5x faster.
It is important to note that Modin is designed to efficiently process heavy tasks, rather than a large number of small tasks. Modin is under active development and one of its targets for a 1.0 release is to efficiently handle small DataFrames.
For now, it is best to introduce Modin into only the parts of your workflow where pandas underperforms. Consider a complete switch from pandas to Modin after you eliminate small DataFrame operations from your code and still find that pandas struggles with every operation of the workflow.
Minimal Hardware Requirements
Modin achieves speedup by distributing computations over CPU cores. To see a noticeable speedup, it is recommended to have a configuration with at least a 4-core or 8-thread CPU and 32 GB of RAM. Note that Google* Colab, the popular free environment for running Python notebooks, has only a one-core, two-thread CPU, which is not enough to use Modin.
How Modin Works
Modin starts by distributing the input data, splitting it small portions called partitions, along rows and columns. Each partition is a small pandas DataFrame that is stored in an immutable shared storage.
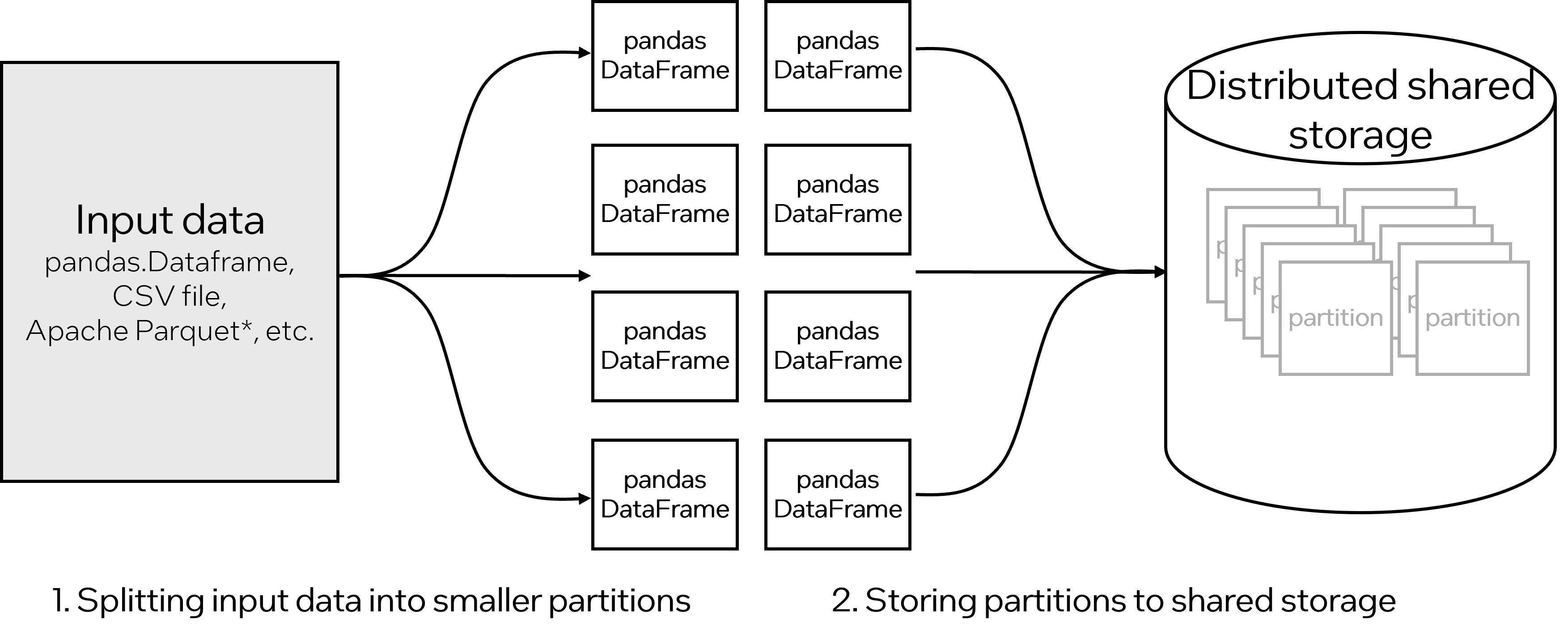
Figure 2. How Modin distributes data and performs operations in parallel.
Then, when an operation is invoked, different worker processes fetch a subset of partitions and apply an operation to each partition in parallel, writing the result back to the storage.
The Modin architecture is flexible, allowing it to use various implementations of shared storage and engines that run kernels. Modin supports four engines:
- Ray and Apache* Arrow In-Memory Plasma Object Store for in-process memory
- Dask* and in-process memory
- MPI for Python (through unidist) plus shared storage and in-process memory
- Heterogeneous Data Kernels (HDK) with its own storage based on Apache Arrow* (natively supports SQL queries)
You can select the running engine by specifying it in a configuration variable before the first use of Modin. No other changes are necessary:
If you do not specify the running engine, Modin will detect what you have installed and automatically use that. If you have multiple engines installed, running with Ray is the default.
If you are familiar with Ray, you can use all its infrastructure tools with Modin, like Ray timeline profiling or Ray Dashboard. Also, if you already have a configured Ray cluster, you can use it to distribute your pandas computations with Modin.
Get Started with Modin
You can install Modin along with one of the running engines on Linux*, Windows*, or macOS* using the pip command for Python Package Index (PyPI)*:
Alternatively, you can install using Anaconda*, which also provides the option to install the HDK running engine:
Then, the simplest way to get started is to replace your pandas import statement with:
Here are some resources to learn more and explore all Modin has to offer:
Hardware, Operating System, and Software Configuration for Runtime Comparisons
Test date: Performance results are based on testing by Intel as of February 12, 2024 and may not reflect all publicly available security updates.
Configuration details and workload setup:
- HP ZCentral* 4R workstation
- Intel® Xeon® W-2245 processor (3.9 GHz, up to 4.5 GHz with Intel® Turbo Boost Technology, 16.5 MB cache, 2933 MHz, 8 cores and 16 threads, 155 W)
- 64 GB DDR4 memory up to 2933 MT/s data rate
- Ubuntu* v22.04.2 LTS
- Python v3.9.18
- pandas v2.2.1
- Modin v0.28.0
- Running engine: Ray v2.9.1
Notices and Disclaimers
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See the previous section for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel® Distribution of Modin*
Scale your pandas workflows to distributed DataFrame processing by changing only a single line of code.