Overview
This article describes the design and implementation of Open vSwitch* (OvS) with the Data Plane Development Kit (DPDK) (OvS-DPDK) datapath classifier, also known as dpcls. We recommend that you first read the introductory article where we introduce the high-level dpcls design, the Tuple-Space search (TSS) implementation and its performance optimization strategy, and a few other scenarios. Part 2 (this article) focuses on call graphs and the subroutines involved.
OvS-DPDK has three-tier look-up tables/caches. Incoming packets are first matched against Exact Match Cache (EMC) and in case of a miss are sent to the dpcls (megaflow cache). The dpcls is implemented as a tuple space search (TSS) that supports arbitrary bitwise matching on packet header fields. Packets that miss the dpcls are sent to the OpenFlow* pipeline, also known as ofproto classifier, configured by an SDN controller as depicted in Figure 1.

Figure 1. Open vSwitch* three-tier cache architecture.
Packet Reception Path
The poll mode driver (PMD) thread continuously polls the input ports in its poll list. From each port it can retrieve a burst of packets not exceeding 32 (NETDEV_MAX_BURST). Each input packet then can be classified based on the set of active flow rules. The purpose of classification is to find a matching flow so that the packet can be processed accordingly. Packets are grouped per flow and each group will be processed to execute the specified actions. Figure 2 shows the stages of packet processing.

Figure 2. Packet-processing stages.
Flows are defined by dp_netdev_flow data structure (not to be confused with the struct flow) and are stored into a hash table called flow_table. Some of the information stored in a flow are
- Rule
- Actions
- Statistics
- Batch (queue for processing the packets that matched this flow)
- Thread ID (owning this flow)
- Reference count
Often the words “flows” and “rules” are used interchangeably; however, note that the rule is part of the flow.
The entries stored in the dpcls subtables are {rule, flow pointer} couples. The dpcls classification can then be summarized as a two-step process where:
- A matching rule is found from the subtables after lookup.
- The actions of the corresponding flow (from the flow pointer) are then executed.
Figure 3 shows a call graph for packet classification and action execution.

Figure 3. Lookup, batching, and action execution call graph.
When a packet is received, the packet header fields get extracted and stored into a “miniflow” data structure as part of EMC processing. The miniflow is a compressed representation of the packet that helps in reducing the memory footprint and cache lines.
Various actions can be executed on the classified packet, such as forwarding it to a certain port. Other actions are available, for example adding a VLAN tag, dropping the packet, or sending the packet to the Connection Tracker module.
EMC Call Graph
EMC is implemented as a hash table where the match must occur exactly on the whole miniflow structure. The hash value can be pre-computed by the network interface card (NIC) when the RSS mode is enabled; otherwise hash is computed in the software using miniflow_hash_5tuple().

Figure 4. EMC processing call graph.
In emc_processing(), after the miniflow extraction and hash computation, a lookup is performed in EMC for a match. When a valid entry is found, an exact match check will be carried out to compare that entry with the miniflow extracted from the packet. In case of a miss, the check is repeated on the next linked entry, if any. If no match is found, the packet will be later checked against the dpcls, the second level cache. Figure 4 depicts the call graph of packet processing in exact match cache.
Datapath Classifier Call Graph
Figure 5 shows the main dpcls functions involved in the overall classification and batching processes.

Figure 5. dpcls call graph.
As described in our introductory article a dpcls lookup is performed by traversing all its subtables. For each subtable the miniflow extracted from the packet is used to derive a search key in conjunction with the subtable mask. See netdev_flow_key_hash_in_mask() function in Figure 6 where also hash functions are displayed.

Figure 6. dpcls lookup call graph.
A dpcls lookup involves an iterative search over multiple subtables until a match is found. On a miss, the ofproto table will be consulted. On a hit, the retrieved value is a pointer to the matching flow which will determine the actions to be performed for the packet. A lookup on a subtable involves the following operations:
- The subtable mask will determine the subset of the packet miniflow fields to consider. The mask is then applied on the subset of fields to obtain a search-key.
- A hash value is computed on the search-key to point to a subtable entry.
- If an entry is found, due to the possibility of collisions (as is the behavior in hash table data structures), a check has to be performed to determine whether or not that entry matches with the search key. If it doesn’t match, the check is repeated on the chained list of entries, if any.
Due to their wildcarded nature, the entries stored in dpcls are also referred to as “megaflows,” because an entry can be matched by “several” packets. For example with “Src IP = 21.2.10.*”, incoming packets with Src IPs “21.2.10.1” or “21.2.10.2” or “21.2.10.88” will match the above rule. On the other hand, the entries stored in EMC are referred to as “microflows” (not to be confused with the miniflow data structure).
Note that the term “fast path” comes from the vanilla OvS kernel datapath implementation where the two-level caches are located in kernel space. “Slow path” refers to the user-space datapath that involves the ofproto table and requires a context switch.
Subtables Creation and Destruction
The order of subtables in the datapath classifier is random, and the subtables can be created and destroyed at runtime. Each subtable can collect rules with a specific predefined mask, see the introductory article for more details. When a new rule has to be inserted into the classifier, all the existing subtables are traversed until a suitable subtable matching the rule mask is found. Otherwise a new subtable will be created to store the new rule. The subtable creation call graph is depicted in Figure 7.

Figure 7. Rule insertion and subtable creation call graph.
When the last rule in a subtable is deleted, the subtable becomes empty and can be destroyed. The subtable deletion call graph is depicted in Figure 8.

Figure 8. Subtable deletion call graph.
Slow Path Call Graph
On a dpcls lookup miss, the packet will be classified by the ofproto table, see Figure 9.
An “upcall” is triggered by means of dp_netdev_upcall(). The reply from Ofproto layer will contain all the information about the packet classification. In addition to the execution of actions, a learning mechanism will be activated: a new flow will be stored, a new wildcarded rule will be inserted into the dpcls, and an exact-match rule will be inserted into EMC. This way the two-layer caches will be able to directly manage similar packets in the future.
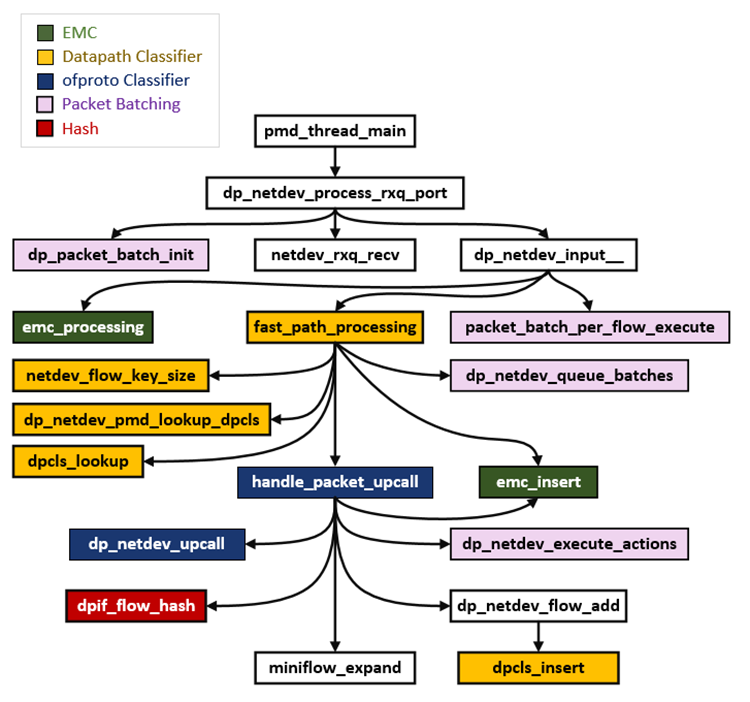
Figure 9. Upcall processing call graph.
Packet Batching
Packet classification categorizes packets with the active flows. The set of received packets is divided into groups depending on the flows that were matched. Each group is enqueued into a batch specific to the flow, as depicted in Figure 10.

Figure 10. Packet are grouped depending on the matching flow.
All packets enqueued into the same batch will be processed with the list of actions defined by that flow. To improve the packet forwarding performance, the packets belonging to the same flow are batched and processed together.
In some cases there could be very few packets in a batch. In a worst case scenario each packet of the fetched set is hitting a distinct flow, so each batch will enqueue only one packet. That becomes particularly inefficient when it comes to transmitting fewer packets over the DPDK interfaces as it incurs expensive MMIO writes. In order to optimize the MMIO transactions and improve the performance, an intermediate queue is implemented. Enqueued packets are transmitted when their count is greater than or equal to 32. Figure 11 depicts how the packet batching is triggered from emc_processing() and fast_path_processing().

Figure 11. Packet batching call graph.
Action Execution Call Graph
The action execution is done on a batch basis. A typical example of an action can be to forward the packets on the output interface. Figure 12 depicts the case where the packets are sent on the output port by calling netdev_send().

Figure 12. Action execution call graph.
Example of Packet Forwarding to a Physical Port

Figure 13. Overall call graph in case of a forwarding to a physical port.
The call graph in Figure 13 depicts an overall picture of the packet path from ingress until the action execution stage, wherein the packet of interest is forwarded to a certain output physical port.
Accelerating the Classifier on Intel® Processors
A hash table is a data structure that associates keys with values and provides constant-time O(1) lookup on average, regardless of the number of items in the table. The essential ingredient of a high-performance hash table is a good hash function that can reduce collisions and the speed at which the hash can be calculated.
Hash tables have been used in OvS-DPDK for implementing EMC and the dpcls. As mentioned before, the EMC lookup can leverage the hash value computed by the NIC with RSS enabled. Instead, in the dpcls the hash is fully computed in software using murmuhash3. Improving the performance of the dpcls is critical to improve the overall OvS-DPDK performance.
In real-world deployments where the virtual switch is handling a few thousand flows, EMC gets quickly saturated due to its limited capacity (8192 entries). So most of the input packets will be checked against the dpcls. Though a single subtable lookup is inherently fast, significant performance degradation is seen with tens of subtables. The classifier performance suffers because the hash value computation has to be repeated for every subtable until a match is found.
To speed up the hash computation, the built-in CRC32 intrinsics can be leveraged on Intel processors. On an X86_64 processor with Intel® Streaming SIMD Extensions instruction set support, CRC32 intrinsics can be used by passing ‘-msse4.2’ during software configuration. For example, to leverage intrinsics, OvS-DPDK can be configured with the appropriate CFLAGS as shown below.
./configure CFLAGS="-g -O2 -msse4.2"
If you are on a different processor and don't know what flags to choose, we recommend using ‘-march=native’ settings. With this, GCC will detect the processor and automatically set the appropriate flags for it. Do not use this method if you are compiling OVS outside the target machine.
./configure CFLAGS="-g -O2 -march=native"
Conclusion
In this article, we discussed the different stages in packet processing pipeline with a focus on the dpcls. We also discussed batching and the positive impact of flow batching and intermediate queue on performance when the packets are forwarded to a physical port. Also we described the intrinsics that can be used to accelerate the dpcls and the overall switching performance on Intel processor-based platforms.
For Additional Information
For any question, feel free to follow up with the query on the Open vSwitch discussion mailing thread.
Part 1 of this two part series: OVS-DPDK Datapath Classifier
Tuple Space Search
To learn more about the Tuple Space Search:
About the Authors
Bhanuprakash Bodireddy is a network software engineer at Intel. His work primarily focuses on accelerated software switching solutions in user space running on Intel architecture. His contributions to OvS-DPDK include usability documentation, the Keep-Alive feature, and improving the datapath Classifier performance.
Antonio Fischetti is a network software engineer at Intel. His work primarily focuses on accelerated software switching solutions in user space running on Intel architecture. His contributions to OVS with DPDK are mainly focused on improving the datapath Classifier performance.