With increasing energy demand globally, the need for accurate and efficient monitoring of utility assets is crucial in being able to provide reliable services and avoid costly and unexpected downtimes. Current manual problem identifications are less than 50% accurate and the costs of maintenance and replacement of utility poles are over $10 billion. (Source: Utility Poles: Maintenance or Replacement. Utility Partners of America. August 3, 2020.)
In collaboration with Accenture, Intel has developed a Predictive Asset Analytics Reference Kit, designed to predict the health of utility assets and the probability of failure in order to proactively maintain assets, improve system reliability, and avoid outages, downtime, and operational costs. Included in this reference kit are the training data; an open source, trained, predictive asset analytics model; libraries; user guides; and oneAPI components to optimize the training cycles, prediction throughput, and accuracy.
To demonstrate how to implement this reference kit, the dataset in this tutorial was generated following the steps in the User Guide. The workflow is shown in Figure 1. It consists of 34 features on the overall health of the utility, including the age of the pole, maintenance history, outage records, and geospatial data. Our target variable is a binary indicator of whether or not the utility pole is failing.
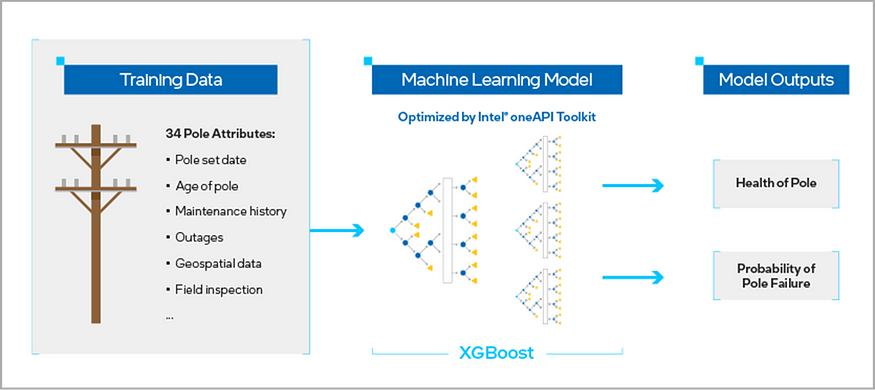
Figure 1. Workflow of the Predictive Asset Analytics Reference Kit
A key benefit of this reference kit is the ability to optimize model training and inference across a heterogeneous XPU architecture with little or no code changes. This is enabled by the Intel® AI Analytics Toolkit (AI Kit) and the Intel® oneAPI Data Analytics Library (oneDAL). The main libraries from the AI Kit that we’ll be working with in this guide are the Intel® Distribution of Modin*, Intel® Extension for Scikit-learn*, and Intel® Optimization for XGBoost*, all of which can be downloaded as part of the AI Kit or as standalone libraries. In addition, daal4py from oneDAL is used to speed up the inference time of the XGBoost* model.
Data Processing
To get started, we’ll use Modin* to process and explore the data. Modin is a distributed DataFrame library designed to scale your pandas workflow with the size of your dataset, supporting datasets that range from 1 MB to 1 TB+. With pandas, only one core is used at a time. Modin’s Dask engine can take advantage of all available CPU cores, which allows you to work with very large datasets at much faster speeds.
Figure 2 shows Modin (left) and pandas (right) performing the same pandas operations on a 2 GB dataset. The only difference between the two notebook examples is the import statement.
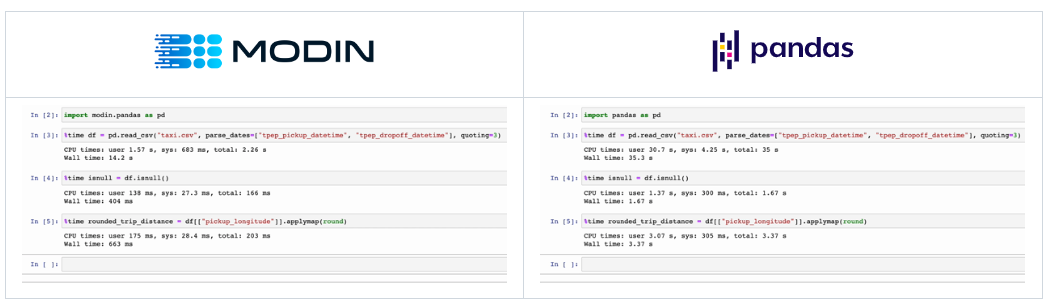
Figure 2. Comparing the performance of Modin* (left) and pandas (right)
To use Modin with the Dask engine, you can first import the drop-in replacement for pandas and then initialize the Dask execution environment in the engine call statement, shown in the following code cell:
import modin.pandas as pd from modin.config import Engine Engine.put("dask")
Exploratory Data Analysis
Once Modin’s Dask engine has been initialized, you can continue processing and exploring the data using the same pandas functions that will be parallelized across the available CPU cores. About 40% of the utility poles in our data have been identified as failing, shown as State 1 in Figure 3. Given the slight imbalance in the target distribution, we will use stratified sampling during cross-validation. For a further exploration of the data, please refer to this notebook.
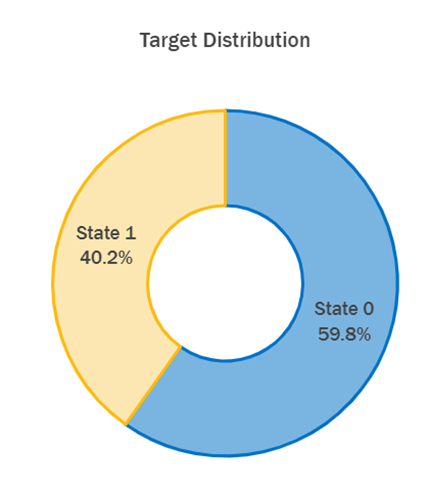
Figure 3. Distribution of the target variable: Asset Label
Building the Solution
To predict the probability of a utility pole failure, several machine learning algorithms were considered. Due to the nonlinearity in the data, two nonparametric models were selected: a Support Vector Classifier (SVC) and XGBoost. Both are highly performant classifiers that are able to capture nonlinear relationships between the features and the target variable. However, they can also take a long time to tune hyperparameters and train models for increasingly large industrial datasets. This is where the AI Analytics Toolkit comes in.
Analysis with a Support Vector Classifier
To optimize the training and inference of the SVC model, we will use the accelerations provided by the Intel Extension for Scikit-learn. The Intel Extension for Scikit-learn reduces algorithm run time through the use of vector instructions, threading, and memory optimizations for both Intel® CPUs and GPUs. It supports many estimators and functions within the scikit-learn* library, including support vector machines, k-nearest neighbors, and random forests.
There are a few different ways to implement this extension. To dynamically patch all supported algorithms globally, all you need to do is call the function shown in the code cell below:
from sklearnex import patch_sklearn patch_sklearn()
The patch will replace supported stock scikit-learn algorithms with their optimized versions, and you can continue to import and use the same AI packages and scikit-learn libraries without any other changes to your code. To learn more about applying this extension, please see the Developer Guide.
Using stratified 3-fold cross-validation to tune the SVC, the best hyperparameters found were a radial basis function kernel with a regularization parameter of 10. On the out-of-sample test set, the SVC achieved an Area Under the ROC Curve (AUC) of 0.919 and an Average Precision (AUPRC) score of 0.902 (Figure 4).
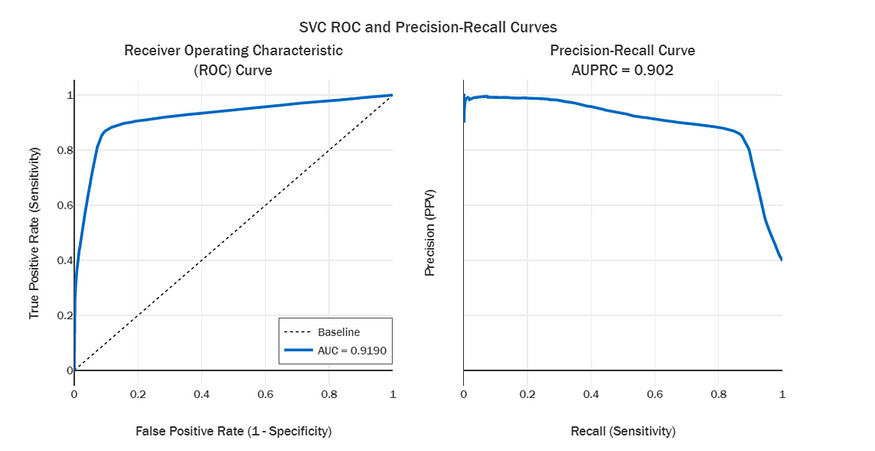
Figure 4. SVC performance on the test set
Analysis with the Intel® Optimization for XGBoost*
To see if further improvement on the performance of the SVC could be achieved, an XGBoost model was tuned following the same steps above using stratified 3-fold cross-validation. During development of the reference kit, XGBoost v1.4.3 was used. XGBoost v0.81 and later contains the optimizations that Intel has been directly upstreaming into the package. The following graphs show the training (Figure 5) and prediction (Figure 6) time improvements that XGBoost v1.4.3 provides when compared to stock XGBoost v0.81 with default hyperparameters on this dataset.
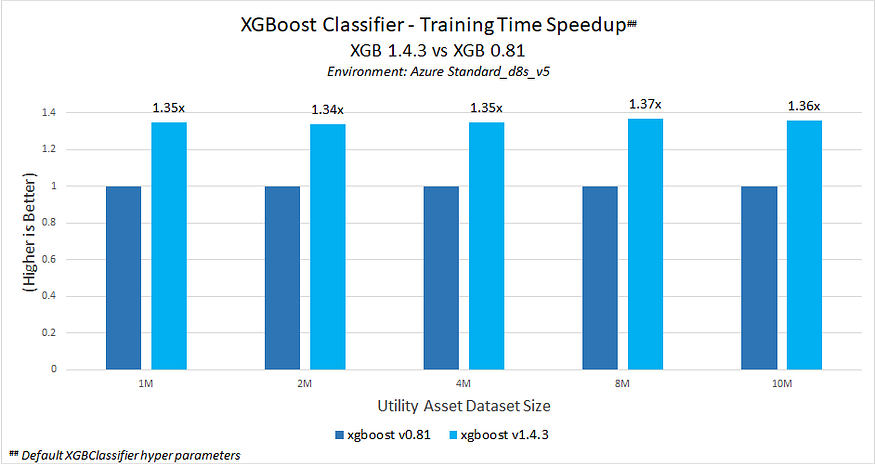
Figure 5. Intel optimizations available in XGBoost* v1.4.3 provide nearly 1.37x faster training than stock XGBoost v0.81.
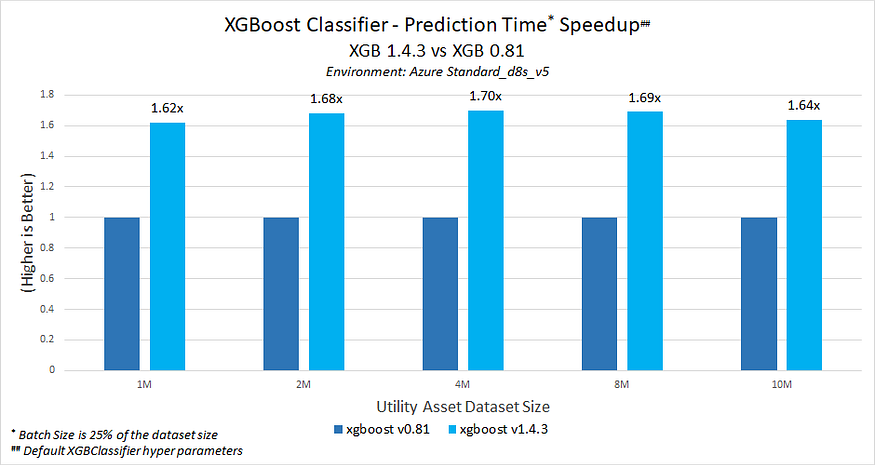
Figure 6. Intel optimizations available in XGBoost* v1.4.3 provide faster prediction ranging between 1.62x and 1.70x better performance than stock XGBoost v0.81.
For further improved performance on prediction time, the tuned XGBoost model can be converted to a daal4py model. Daal4py is the Python* API for oneDAL. It uses Intel® AVX-512 vectorization to maximize gradient boosting performance on Intel® Xeon® processors (Figure 7).
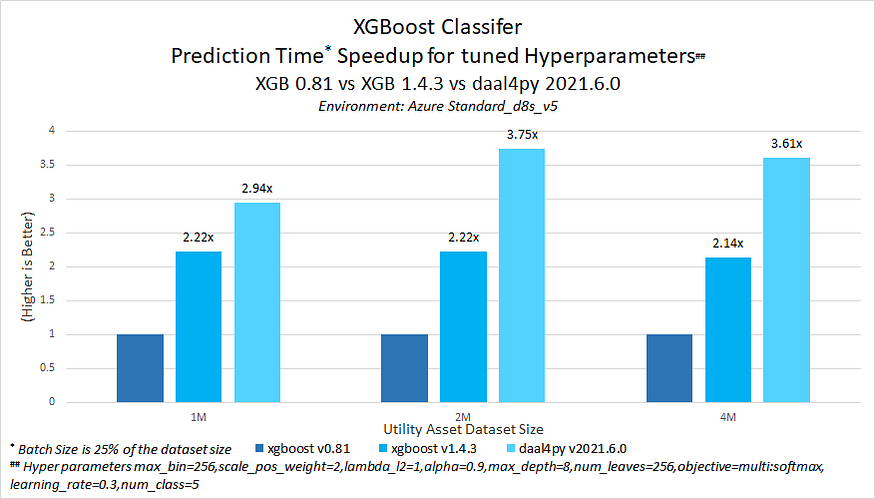
Figure 7. Prediction time speedup from Intel optimizations available in XGBoost* v1.4.3 and daal4py v2021.6.0 vs. stock XGBoost v0.81.
With tuned hyperparameters, Intel Optimization for XGBoost offers faster prediction times, ranging between 2.14x and 2.22x speedup. Daal4py offers an additional improvement in prediction time, ranging between 2.94x to 3.75x speedup, compared to stock XGBoost v0.81. Converting a tuned XGBoost model to daal4py can be done very easily with the following lines of code:
import daal4py as d4p daal_model = d4p.get_gbt_model_from_xgboost(xgb.get_booster())
Then, you can send the trained model along with the input data into daal4py’s prediction function to calculate the probabilities on the test set:
daal_prob = d4p.gbt_classification_prediction(nClasses = 2, resultsToEvaluate = "computeClassLabels|computeClassProbabilities", fptype = 'float').compute(X_test, daal_model).probabilities
Figure 8 shows the prediction performance attained by the XGBoost model using daal4py accelerations on the out-of-sample test set. XGBoost was able to outperform the SVC with an AUC of 0.9401 and an Average Precision score of 0.937.
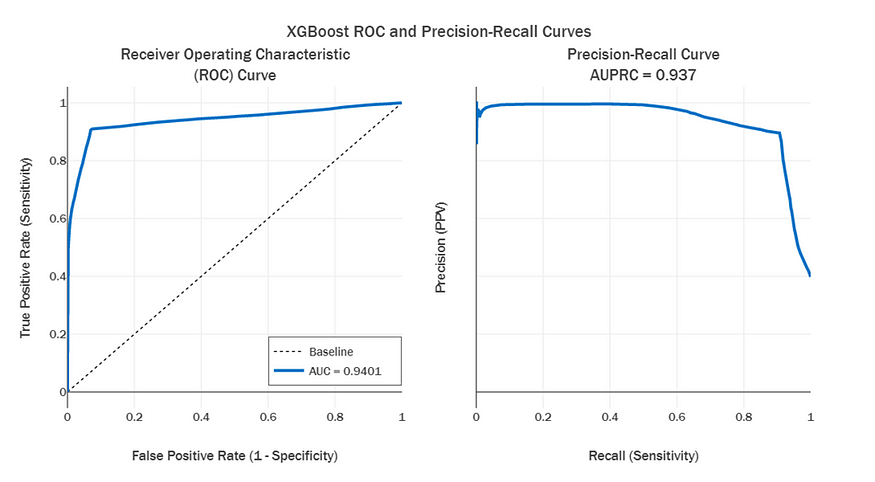
Figure 8. XGBoost* performance on the test set using daal4py optimizations
Conclusion
Predictive maintenance solutions of huge scale typically require acceleration in training and inference. Using the optimizations available in the Intel AI Analytics Toolkit, we developed an efficient, end-to-end probabilistic classification tool to predict the likelihood of a utility pole failure. Faster training and inference results in less compute time, higher productivity, and fewer costs to produce predictive utility health forecasts for hundreds of thousands of assets. This reference provides a performance-optimized guide to the prediction of asset maintenance for utility customers that can easily be scaled across similar industries and use-cases.
The Parallel Universe Magazine
Intel’s quarterly magazine helps you take your software development into the future with the latest tools, tips, and training to expand your expertise.