Background
Cloud native environments support multiple tenants and host applications and data for multiple customers in a single architecture or in single physical computing nodes. Both solutions are common and are broadly accepted today. However, cloud workloads (such as business applications) running on the same server frequently interfere with each other. The classic scenario is co-location of online and offline business workloads. Without isolation, online business is frequently impacted by offline workloads. When a non-business-critical, offline application interferes with critical online business workloads, it is referred to as a “noisy neighbor”. How do we resolve this type of problem? That is the purpose of this blog.
Problem description
The term “noisy neighbor” describes a scenario in cloud infrastructure where an application experiences degradation in performance, such as long latency, when needed resources are fully occupied by other applications in the same cloud computing node. Sometimes, this situation cannot be easily identified and the service that application provides is critical for the end user on the other side. The problem arises when resources are shared without strict isolation, such as CPU sharing. CPU cores are closely connected with other sharable resources, such as last level cache and memory bandwidth. When shared resources are allocated to workloads without an isolation policy, it is easier to generate a noisy neighbor problem. Workloads running on sibling hyper threads (hyper threads are a concept of Intel x86 architecture) use the same physical CPU core. Workloads running on different physical CPU cores share the same last level cache, memory controller, and I/O bus bandwidth. Even workloads running on different physical CPU sockets, using different cache and memory channels share CPU interconnect bandwidth, the same storage devices, or I/O bus. Meanwhile, noisy neighbor workloads usually require more resources and take a long time. In this situation, the critical workload is suspended because it can't get the required resources.
Kubernetes has a CPU manager and a device plugin manager for hardware resource allocations, such as CPUs and Devices (SR-IOV, GPUs). The latest release of Kubernetes has a topology manager for NUMA topology awareness to achieve optimal performance with coordinated resources and a guarantee for critical workloads. But it doesn’t provide a policy to resolve the problem of noisy neighbors.
Solution
When critical workloads are co-located with one or more noisy neighbors, it is important to ensure that the critical workloads can get their required resources, such as CPU, cache, memory, I/O bandwidth, and smooth operation at any point in time.
This is only a partial solution because resource allocation policies are not sufficient and effective for potential performance benefits offered by computing nodes powered by Intel® architecture. There is no isolation of noisy neighbors in Kubernetes because Kubernetes is not aware of and does not detect some resources, such as hierarchy of memory controllers, high/low clock frequency CPU cores, and Intel® Resource Director Technology (Intel® RDT).
Those resources must be shared by applications, VMs, and containers. As an example, on Intel platforms, according to the hardware design, last-level cache has these rules:
- Each logical core (hyper-threading) has exclusive L1 cache (L1 is divided into Icache and DCache).
- Each physical core (including two logical cores) shares L2 cache.
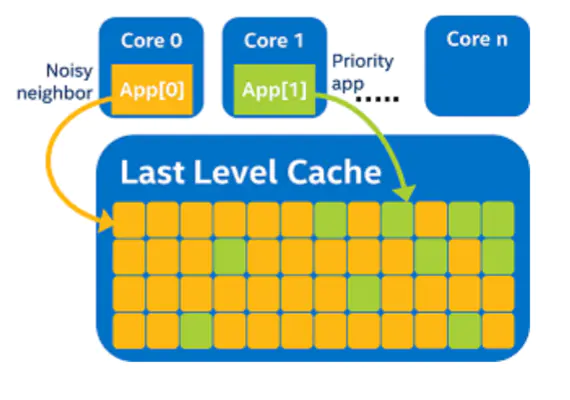
- The core of each socket shares L3 cache, which is referred to as last level cache and is shown in Figure 1 below.
Sharing cache may easily lead to the “noisy neighbors” problem. As shown in Figure 1, there are two applications. Since L3 is shared and follows the principle of "first come, first served", the application “APP [1]” has only a small amount of L3 cache available, which is obviously detrimental to its performance.
The Kubernetes container runtime interface resource manager (CRI-RM) is an open-source reference implementation of advanced resource management running on Intel® architecture. CRI-RM is a proxy service with hardware resource aware workload placement policies. CRI-RM runs one of its built-in policy algorithms that decides how the assignment of resources to containers should be updated. There are several policies available within CRI-RM, each with a different set of goals and implementing different hardware allocation strategies.
Intel RDT policies provide additional control over last-level cache and memory bandwidth, which help control noisy neighbors. The Intel RDT controller allows you to limit access to shared resources for non-critical workloads by configuring corresponding Intel RDT classes for the three Kubernetes QoS classes: Besteffort, Burstable, and Guaranteed.
Usage of Intel Resource Director Technology
The concept of classes of service (CLOS) is defined in Intel RDT, which can be compared to a cgroup. In a cgroup, a CLOS corresponds to hardware config (such as 20% L3 cache). By mapping the upper application to the CLOS, we can control the resource. Figure 2 below shows an overview of Intel RDT usage:
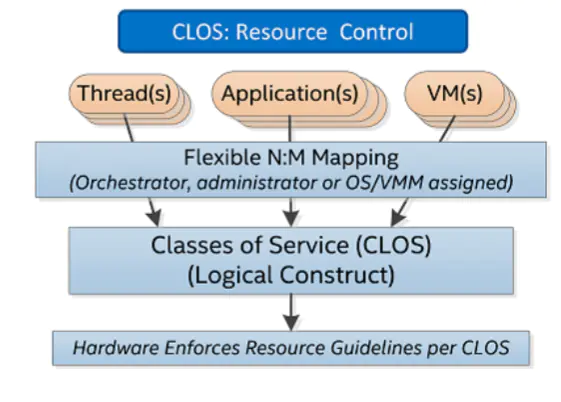
The Linux kernel exposes the user space interface to developers through the “resctrl” filesystem.
An example of using resctrl is shown in the steps below:
Step 1. Mount resctrl
Step 2. Create CLOS
There are three main types of files in each CLOS:
- Tasks: indicates the task ID that belongs to this CLOS
- CPUs: indicates the CPU ID of this CLOS
- Schemata: indicates a cache configuration
There are two modes to be used: tasks and CPUs. Choose one of the configurations shown below.
Task and schemata
Achieve resource isolation by binding task and schemata. When the scheduler switches, the CLOS ID of the corresponding CPU also changes
CPUs and schemata
Achieve resource isolation by binding CPU and schemata. This is equivalent to fixing the CLOS ID in the CPU and then pinning a different thread to these cores.
If both tasks and CPUs are configured and there is a conflict (the actual CPU core of the task is inconsistent with the CPU configured by the CLOS), the CLOS to which the tasks belong shall prevail.
Step 3. Schemata config
First, each L1 / L2 / L3 cache has a corresponding ID. For example, the L3 cache index on socket 0 is set to 0 and L3 cache index on socket 1 is set to 1.
Then, write the following rules into schemata:
The left side of the equation is the cache ID, and the right side of the equation is the bitmask:
Step 4. Echo tasks
The steps above are the basis of using Intel RDT, but with CRI-RM, we configure Intel RDT using classes. That means each container is assigned to an Intel RDT class. In turn, all processes of the container are assigned to the Intel RDT class of service (CLOS) under /sys/fs/resctrl that correspond to the Intel RDT class. CRI-RM configures the CLOSes according to its configuration at startup or whenever the configuration changes. CRI-RM maintains a direct mapping between pod QoS classes and Intel RDT classes. If Intel RDT is enabled, CRI-RM tries to assign containers into an Intel RDT class with a name matching their pod QoS class. This default behavior can be overridden with pod annotations.
Class assignment is explained below:
By default, containers get an Intel RDT class with the same name as its pod QoS class (Guaranteed, Burstable, or Besteffort). If the Intel RDT class is missing, the container is assigned to the system root class.
The default behavior can be overridden with pod annotations:
- rdtclass.cri-resource-manager.intel.com/pod: <class-name> specifies a pod-level default that is used for all containers of a pod
- rdtclass.cri-resource-manager.intel.com/container.<container-name>: <class-name> specifies container-specific assignment, taking preference over possible pod-level annotation (above)
With pod annotations it is possible to specify Intel RDT classes other than Guaranteed, Burstable, or Besteffort.
The default assignment could also be overridden by a policy, but currently none of the built-in policies do that.
Use the configuration file below in CRI-RM to control resources.
For more information about the CRI-RM open-source project and how to use CRI-RM, go to: CRI-RM. You can read more about Intel RDT usage for cache level isolation here: documentation
About Intel Resource Director Technology
Intel RDT brings new levels of visibility and control over how shared resources, such as last-level cache (LLC) and memory bandwidth, are used by applications, virtual machines (VMs), and containers. Intel RDT can be used for driving workload consolidation density, performance consistency, and dynamic service delivery. Intel RDT helps ensure that administrator or application Quality of Service (QoS) targets can be met.
Intel RDT provides a framework with several component features for cache and memory monitoring and allocation capabilities, including Cache Monitoring Technology (CMT), Cache Allocation Technology (CAT), Code and Data Prioritization (CDP), Memory Bandwidth Monitoring (MBM), and Memory Bandwidth Allocation (MBA).see below figure [3], These technologies enable tracking and control of shared resources, such as the last level cache (LLC) and main memory (DRAM) bandwidth, in use by many applications, containers, or VMs running on the platform concurrently. Intel RDT may aid “noisy neighbor” detection and help to reduce performance interference, ensuring the performance of key workloads in complex environments.
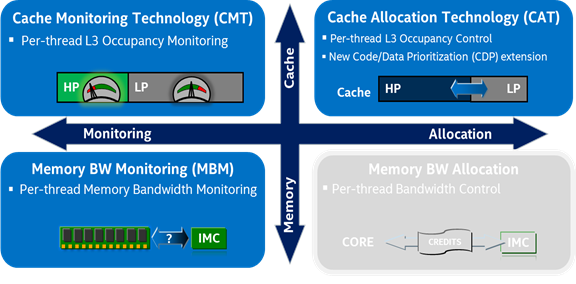
Finally, Intel RDT helps isolate resources at the cache level and is a key technology to fix the "noisy neighbor" problem in Cloud Native.
Resource management and isolation references
[1] Documentation of CRI-RM open-source project: https://intel.github.io/cri-resource-manager/stable/docs/index.html
[2] white page of Topology-Aware Resource Assignment in Kubernetes: https://builders.intel.com/docs/networkbuilders/cri-resource-manager-topology-aware-resource-assignment-in-kubernetes-technology-guide-1617431283.pdf
[3] Unlock System Performance in Dynamic Environments with intel RDT: https://www.intel.com/content/www/us/en/architecture-and-technology/resource-director-technology.html
[4] Introduction to Cache Allocation Technology in the Intel® Xeon® Processor E5 v4 Family: https://www.intel.cn/content/www/cn/zh/developer/articles/technical/introduction-to-cache-allocation-technology.html
[5] useful links of Intel RDT: https://github.com/intel/intel-cmt-cat/wiki/Useful-links