Migrate Deformable Convolution Networks from CUDA* to SYCL* with Intel® Extension for PyTorch*
Contributors
From Intel Corporation: Huiyan Cao, Jie Lin, Jing Xu, Ying Hu, and Chao Yu
Introduction
In this document, we introduce a guide on migrating Deformable Convolutional Networks V2[1], which is used by CenterNet[2], from CUDA* to SYCL* using the Intel® DPC++ Compatibility Tool[3], and run CenterNet on an Intel GPU using Intel® Extension for PyTorch*[4].
CenterNet & Deformable Convolutional Networks
The CenterNet we are using is based on modeling an object as a single point — the center point of its bounding box. The detector uses keypoint estimation to find center points and regresses to all other object properties, such as size, 3D location, orientation, and even pose. CenterNet's center point-based approach is end-to-end differentiable, simpler, faster, and more accurate than corresponding bounding box-based detectors.
In this CenterNet, ResNet and DLA are modified to use deformable convolution layers with some operators implemented using CUDA*.
SYCL*
SYCL* offers a powerful and flexible programming model for implementing customized algorithms as extensions to AI frameworks. It simplifies the development process, provides abstraction from hardware details, and enables efficient use of heterogeneous computing resources:
-
Heterogeneous Computing: SYCL* is designed for heterogeneous computing, allowing developers to leverage the computational power of diverse accelerators. This is crucial in the field of AI, where different tasks may benefit from specialized hardware such as GPUs or FPGAs.
-
Portability: SYCL* is a portable programming model that lets developers to write code that can be executed across a variety of devices without modification. This portability is particularly valuable when working with different hardware architectures and accelerators commonly found in AI applications.
-
Parallelism and Performance: SYCL* lets developers express parallelism in algorithms, which is essential for optimizing performance in AI workloads. SYCL* provides flexibility in algorithm design and lets developers express parallelism and optimizations directly in the code. This is beneficial when tailoring algorithms to specific AI tasks, as it provides fine-grained control over the execution on different devices.
-
Standardization and Ecosystem: SYCL* is an open standard maintained by the Khronos Group, fostering a standardized programming model for heterogeneous systems. This standardization can lead to a more robust and interoperable ecosystem, with tools and libraries that support SYCL* development.
Intel® DPC++ Compatibility Tool
The Intel DPC++ Compatibility Tool assists in migrating your existing CUDA* code to SYCL* code. Here are several ways the tool is beneficial for this migration process:
-
Code Analysis and Syntax Mapping:The Compatibility Tool can analyze existing CUDA* codebases and identify potential areas of concern or incompatibility with SYCL*. While CUDA* and SYCL* have different syntaxes, many concepts are similar so the tool can automatically map CUDA* constructs to their equivalent SYCL* counterparts. This minimizes code-migration time to update a program written in CUDA* to a program written in SYCL*.
-
API Compatibility: CUDA* and SYCL* have distinct API sets for managing devices, memory, and other runtime features. The Compatibility Tool can help find differences in these APIs, and automatically generate SYCL* or Intel oneAPI Library code wherever possible. For those CUDA* APIs the Compatibility Tool could not handle automatically, it generates inline comments in the generated SYCL* code to guide developers where to manually update their code.
By providing these capabilities, the Intel DPC++ Compatibility Tool simplifies the process of migrating CUDA* code to SYCL*, making SYCL* more accessible for developers. The resulting SYCL* code lets developers use diverse hardware platforms for their parallel computing workloads.
Intel® Extension for PyTorch*
Intel® Extension for PyTorch* extends PyTorch with the latest performance optimizations for Intel hardware. Optimizations take advantage of Intel® Advanced Vector Extensions 512 (Intel® AVX-512) Vector Neural Network Instructions (VNNI), Intel® Advanced Matrix Extensions (Intel® AMX) on Intel CPUs, as well as Intel XeMatrix Extensions (XMX) AI engines on Intel discrete GPUs. Intel® Extension for PyTorch* offers GPU acceleration for Intel discrete GPUs through the PyTorch* xpu device.
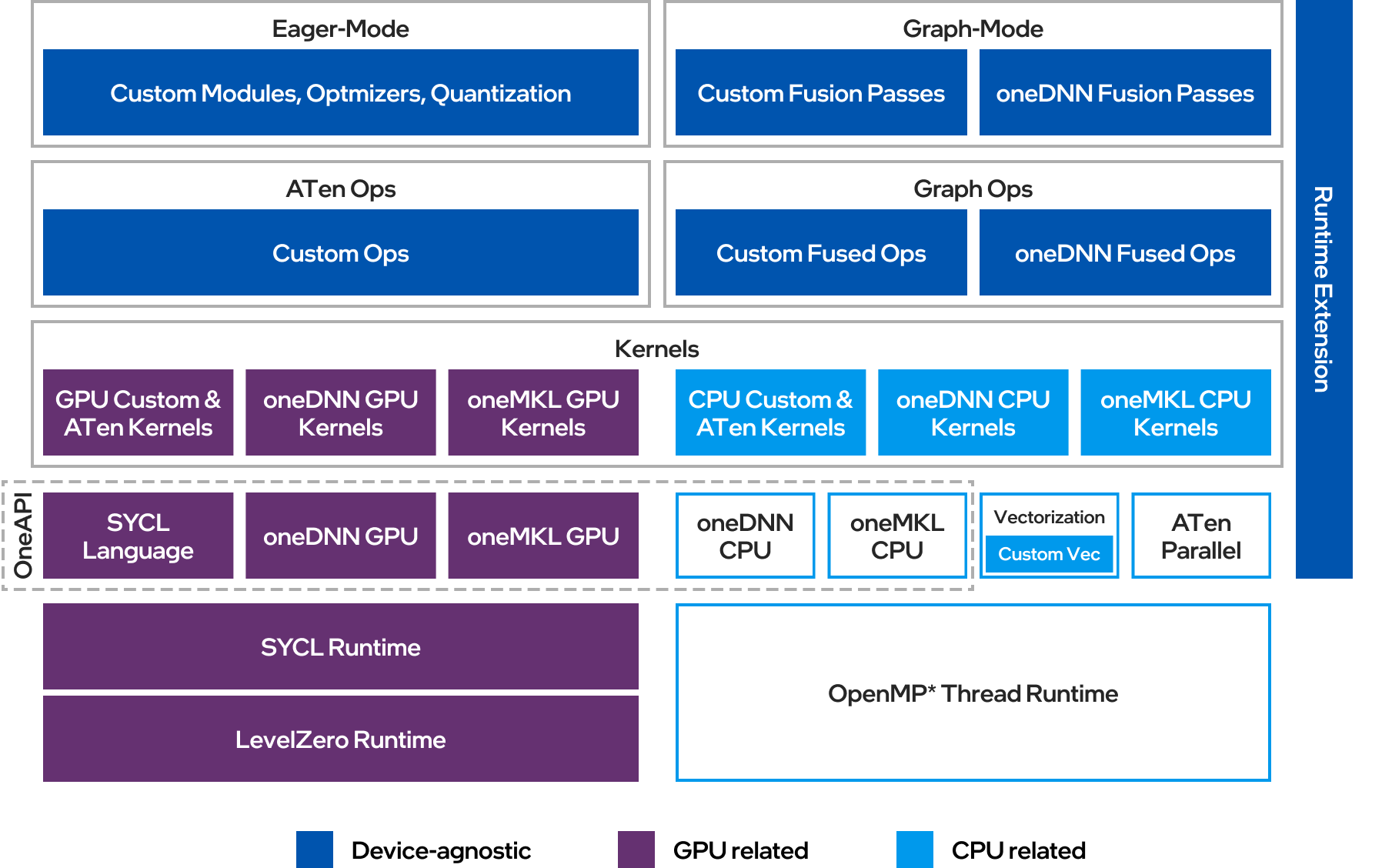
Figure 1: Intel® Extension for PyTorch* Structure
C++ extension is a mechanism developed by PyTorch that lets you create customized and highly efficient PyTorch operators defined out-of-source, i.e., separate from the PyTorch backend. (For more details, see https://pytorch.org/tutorials/advanced/cpp_extension.html). Based on the PyTorch C++ extension mechanism, Intel® Extension for PyTorch* lets you create PyTorch operators with custom DPC++ kernels to run on the xpu device.
Migration
The following sections explain these four steps for the migration solution for Deformable Convolution Networks:
- Migrate CUDA* code of deformable convolution layers to SYCL* code using the Intel® DPC++ Compatibility Tool.
- Build SYCL* code of deformable convolution layers using
DpcppBuildExtension. - Use
xpudevice in CenterNet with Intel® Extension for PyTorch*. - Align memory format between Python operators and customized SYCL* operators.
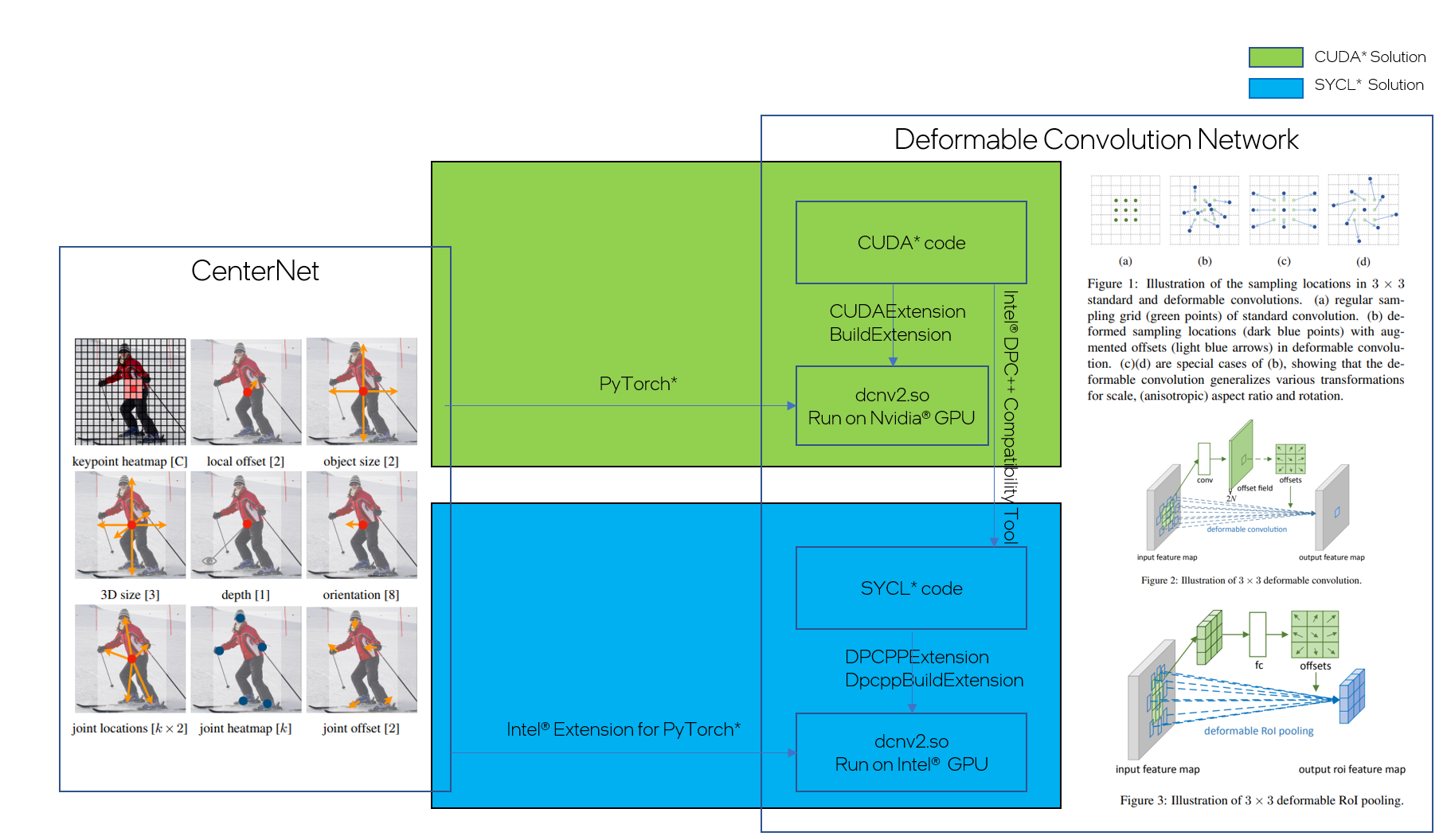
Figure 2: CUDA* to SYCL* Migration Solution
Migrate CUDA* Code
The original DCNv2 code in CenterNet is incompatible with the latest version of PyTorch, so we use DCNv2_latest instead.
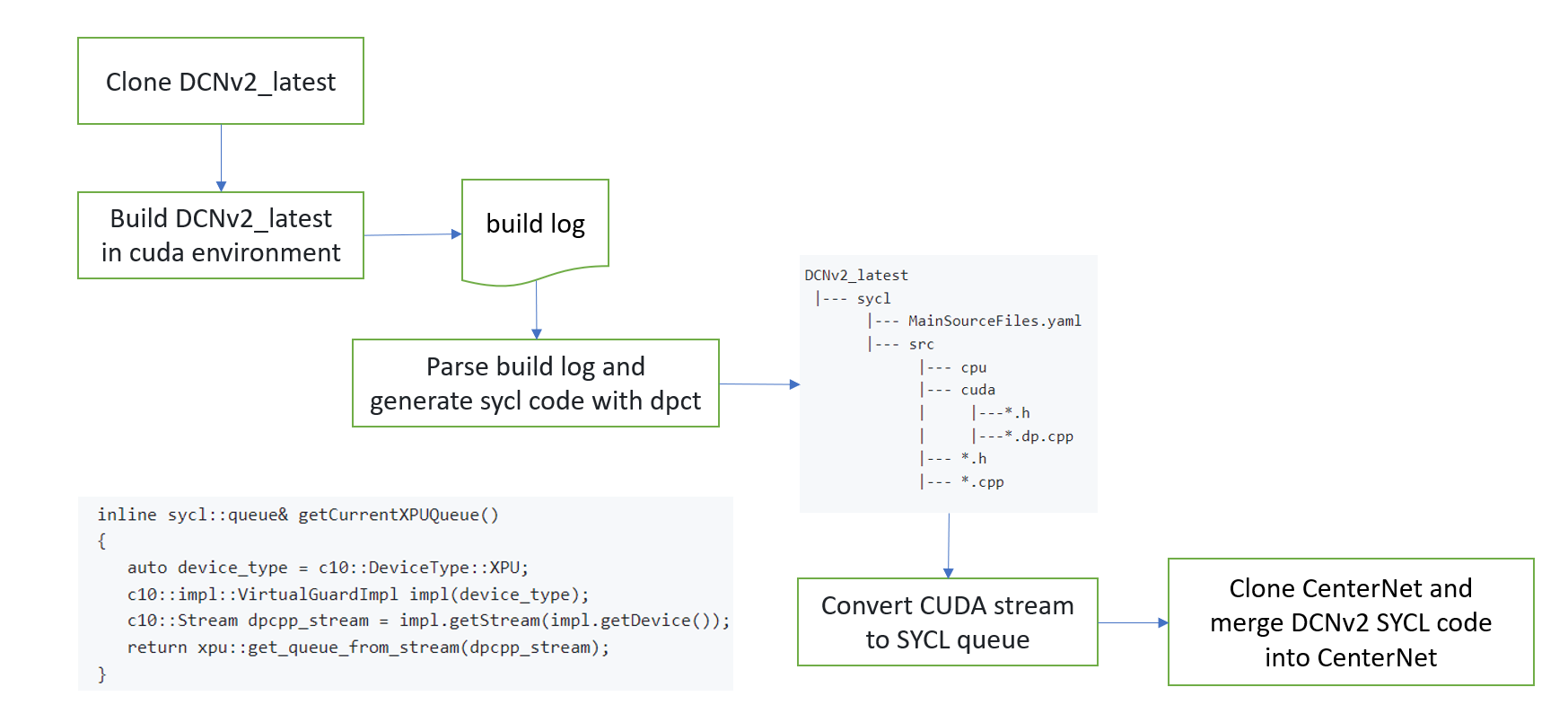
Figure 3: Migrate CUDA* code
- Build
DCNv2_latestand generate log file
-
Convert CUDA* code to SYCL* code using Intel® DPC++ Compatibility Tool
Intel® DPC++ Compatibility Tool can be downloaded as part of Intel® oneAPI Base Toolkit or stand-alone.
The generated DPC++ code is output to the sycl/src/cuda folder:
DCNv2_latest |--- sycl |--- MainSourceFiles.yaml |--- src |--- cpu |--- cuda | |---*.h | |---*.dp.cpp |--- *.h |--- *.cpp
-
Convert CUDA* stream to SYCL* queue
During this conversion, we found that
c10::cuda::getCurrentCUDAStream()was not converted automatically and needs to be converted manually, as shown here:-
Create utils.h in
sycl/src/cuda -
Replace all
c10::cuda::getCurrentCUDAStream()with&getCurrentXPUQueue()insycl/src/cudaFor example, in
sycl/src/cuda/dcn_v2_cuda.dp.cpp:
-
-
Check all places with
You need to rewrite this code, comment all CUDA* related code.
-
Merge DCNv2 SYCL* code into CenterNet
-
Clone CenterNet repo
-
Remove CUDA* code of DCNv2
-
Copy SYCL* code of DCNv2
-
Modify
CenterNet/src/lib/models/networks/DCNv2/src/dcn_v2.has below: -
Replace
dcn_v2.pyinCenterNet/src/lib/models/networks/DCNv2from DCNv2_latest
-
Build DPC++ Extension for DCNv2
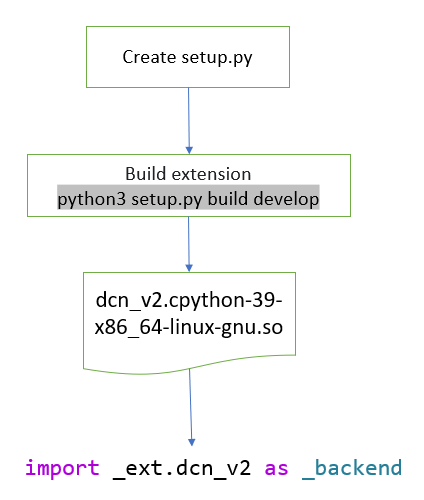
Figure 4: Build DPC++ Extension
-
Install Intel® oneAPI Base Toolkit
-
Intel® oneAPI DPC++/C++ Compiler, Intel® DPC++ Compatibility Tool, Intel® oneAPI Math Kernel Library, and Intel® oneAPI Deep Neural Network Library are needed at least
-
source environment variables after installation
-
-
Create python environment
-
Create conda environment
-
Check this installation guide to install the latest xpu version of Intel® Extension for PyTorch*.
-
Install other dependencies
-
-
Create
CenterNet/src/lib/models/networks/DCNv2/setup.py
- Build extension
Use 'xpu' device in CenterNet with Intel® Extension for PyTorch*
- Add
--xpuparameter inCenterNet/src/lib/opts.py
- Set
opt.deviceaccordingly inCenterNet/src/lib/detectors/base_detector.py
- Replace all calls to
torch.cuda.synchronize()as shown here, and addimport intel_extension_for_pytorch as ipexin each modified Python file.
Align Memory Format
The oneDNN library uses blocked memory layout[4] for weights by default to achieve better performance on Intel® Data Center GPU Flex Series and Intel® Arc™ GPU. While on Intel® Data Center GPU Max Series, plain data format[5] is used by default, which is NCHW in PyTorch. To get correct output on Intel® Data Center GPU Flex Series and Intel® Arc™ GPU, and to get better performance on Intel® Data Center GPU Max Series, we need to align memory format between layers implemented by oneDNN and customized operators by SYCL*.
- Convert memory fomat to
NHWCfor input images and model at the beginning ofprocessfunction, usesrc/lib/detectors/ctdet.pyas shown here:
- Convert input tensors to
Contiguousmemory format when calling customized operators, as shown usingmodulated_deformable_im2col_cudaas an example:
-
Replace all
.viewwith.reshapeinCenterNet/src/lib/models/networks/DCNv2/src/sycl/ -
For example, in
CenterNet/src/lib/models/networks/DCNv2/src/sycl/dcn_v2_cuda.dp.cpp:
Run Demo
- Download models (for example: ctdetcocodla_2x) from model zoo to
CenterNet/models - Run demo
- Result

Figure 5: Result
Conclusion
The Khronos SYCL* C++ standard is the open path for developing heterogeneous code that runs across multiple architectures. The Intel® DPC++ Compatibility Tool assists in migrating your existing CUDA* code to SYCL* code. You can use Intel® Extension for PyTorch* to build generated SYCL* code as a PyTorch extension and run on Intel GPUs easily.
Acknowledgement
We would like to thank Hui Wu from Intel® Extension for PyTorch* development team, and David Kinder for the article review.
Reference
[1] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017.
https://github.com/CharlesShang/DCNv2
https://github.com/lucasjinreal/DCNv2_latest
[2] "Objects as Points"
https://arxiv.org/abs/1904.07850
https://github.com/xingyizhou/CenterNet
[3] Intel® DPC++ Compatibility Tool
https://www.intel.com/content/www/us/en/developer/tools/oneapi/dpc-compatibility-tool.html
[4] Intel® Extension for PyTorch*
https://github.com/intel/intel-extension-for-pytorch
[5] Blocked Layout in oneDNN
https://oneapi-src.github.io/oneDNN/dev_guide_understanding_memory_formats.html#blocked-layout
[6] Plain Data Format
https://oneapi-src.github.io/oneDNN/dev_guide_understanding_memory_formats.html#plain-data-formats
Notices & Disclaimers
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.