Authors: Lisha Guo, Junwei Fu, Ningxin Hu, Mingming xu, Intel
Abstract
In recent years, the deep learning has been getting increasingly important and widely applied in many applications. Hardware vendors, including Intel, are actively optimizing the performance of DL workloads, not only by extending the capabilities of CPU and GPU, but also by introducing new specialized accelerators.
Edge devices have limited memory, computing resources and power, so these dedicated accelerators not only help optimize the performance but also help reduce the power consumption. Vector Neural Network Instructions (VNNI, Intel® Advanced Vector Extensions 512 [Intel® AVX-512])1 is an x86 extension instruction set and is a part of the Intel AVX-512 ISA which is designed to accelerate convolutional neural network for INT8 inference. INT8 inference offer improved performance over higher precision types since it allows packing more data into a single instruction, at the cost of reduced but acceptable accuracy.
For power saving, Intel® Gaussian & Neural Accelerator (Intel® GNA)2 is designed for offloading continues inference workloads such as noise suppression and speech recognition to free CPU resources available in ICL+ platform. However, applications running on the Web Platform are still disconnected from these hardware improvements. Considered that, we are proposing a new domain specific Web Neural Network (WebNN) API to access those hardware accelerations for machine learning. By taking advantage of these new hardware features, WebNN can help access a purpose-built machine learning hardware and close the gap between the web and native.
Introduction
Machine Learning (ML) technology, especially those in the subfield of Deep Learning (DL), have been successfully used in advanced computationally-heavy applications such as image recognition, speech recognition, and natural language processing. To push higher performance during inference computations, hardware vendors, including Intel, are actively optimizing on-device DL performance through several strategies, from extending CPU instruction sets with DL-specific instructions (e.g VNNI) is designed to accelerate convolutional neural network for INT8 inference.
INT8 computations offer improved performance over higher precision types because it allows packing more data into a single instruction, at the cost of reduced but acceptable accuracy. The process to lower the precision of a model from FP32 to INT8 is called quantization and it is a great practice to accelerate the performance of certain models on hardware that supports INT8. oneDNN4 is an open-source cross-platform performance library for deep learning applications optimized for processors with Intel® architecture that can achieve int8 inference capability. Intel also builds new specialized accelerators for reducing power consumption named Intel Gaussian & Neural Accelerator (Intel GNA) that is a specialized hardware for noise suppression and speech recognition with minimum power consumption.
Native applications can access all these hardware improvements through OS (Operating System) APIs (Application Programming Interfaces) or native framework and libraries. As these APIs are usually OS-specific, porting a native application to a different platform usually requires code modification. By contrast, applications running on the Web Platform require no such modifications, and, unsurprisingly, the Open Web Platform is becoming the largest application development platform, with millions of developers targeting it for its global reach, economies of scale and cross-platform nature. Several Javascript* libraries/frameworks exist to help web app developers deploy DL applications in the browser across multiple platforms. Among these we find TensorFlow*.js5, ONNX*.js6 and Brain.js. To achieve acceptable performance, these frameworks usually avail themselves to the highest-performant components of the Web Platform: WebGL/WebGPU and WebAssembly, for efficient DL computation on GPU and CPU, respectively.
This is currently the most effective design, as the Web Platform has only limited access to the DL-specific hardware improvements listed above. This leads to web-based DL applications which have much lower performance and higher power consumption compared to native ones.

WebNN: Efficient Access to DL Capabilities from the Web Platform
Architecture of WebNN
Web Neural Network (WebNN) is a new dedicated Web API for accessing hardware accelerations from web browsers that is incubating to W3C community group7. Developers can utilize the WebNN for deep learning inference with JavaScript* libraries or framework. We prototyped the WebNN API in the open-sourced Chromium browser. It introduces the primitives of the deep neural network to the web platform which include tensor operand and tensor operation. Tensor operand represents the multi-dimensional array in different data type including FLOAT32, FLOAT16, and INT32, INT8.The tensor operations consist of convolution, matrix multiplication, pooling, element wise and activation. Currently, WebNN mainly focuses on the optimization of computation-heavily operations, such as convolution and matrix multiplication, since these operations occupy most of the inference time. For other operations which WebNN does not support will be delegated to WebAssembly or WebGPU. Besides, WebNN cannot support custom operations currently.
The acceleration of them is critical to the inference performance. By using these primitives, the JavaScript* machine learning framework can define a computational graph which can represent part or whole of a machine learning inference model. Then, the framework can use WebNN API to compile and execute the graph for hardware acceleration. The execution of the WebNN graph can interact with kernels written in WebAssembly or WebGPU compute shader. With that, the frameworks can be flexible by using the WebNN for hardware acceleration and using WebAssembly, WebGPU for custom operation support.
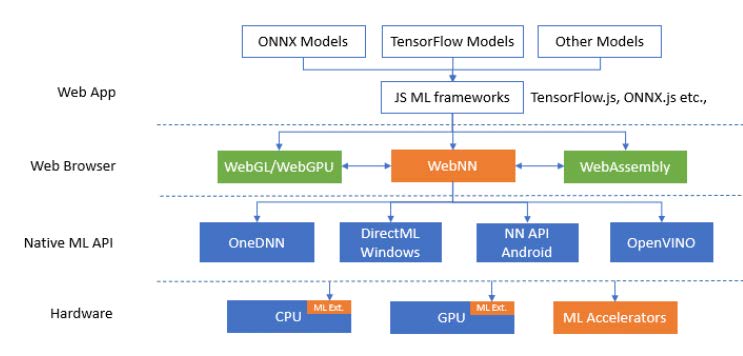
The primitives of WebNN can be mapped to the native machine learning API available on different operating systems, such as Android Neural Networks API*, DirectML on Windows*, Metal Performance Shader on macOS*, iOS, and OpenVINO, Intel® oneAPI Deep Neural Network Library (oneDNN). Eventually, these native APIs will talk with compilers and drivers to run these primitives on various machine learning hardware. The user can select the most proper underlying native ML backend for accelerations before compiling the constructed graph. For the deep learning framework or library which are not embedded in OS, such as OpenVINO and Intel® oneAPI Deep Neural Network Library (oneDNN), we need to compile and install them for usage in advance. Otherwise, the WebNN will throw error if the user wants to use the corresponding framework to acceleration.
- The Android* Neural Networks API (NNAPI)8 is an Android C API designed for running computationally intensive operations for machine learning on Android devices. NNAPI is designed to provide a base layer of functionality for higher-level machine learning frameworks, such as TensorFlow Lite and Caffe2, that build and train neural networks.
- DirectML9 is a high-performance, hardware-accelerated DirectX* 12 library for machine learning. DirectML provides GPU acceleration for common machine learning tasks across a broad range of supported hardware and drivers.
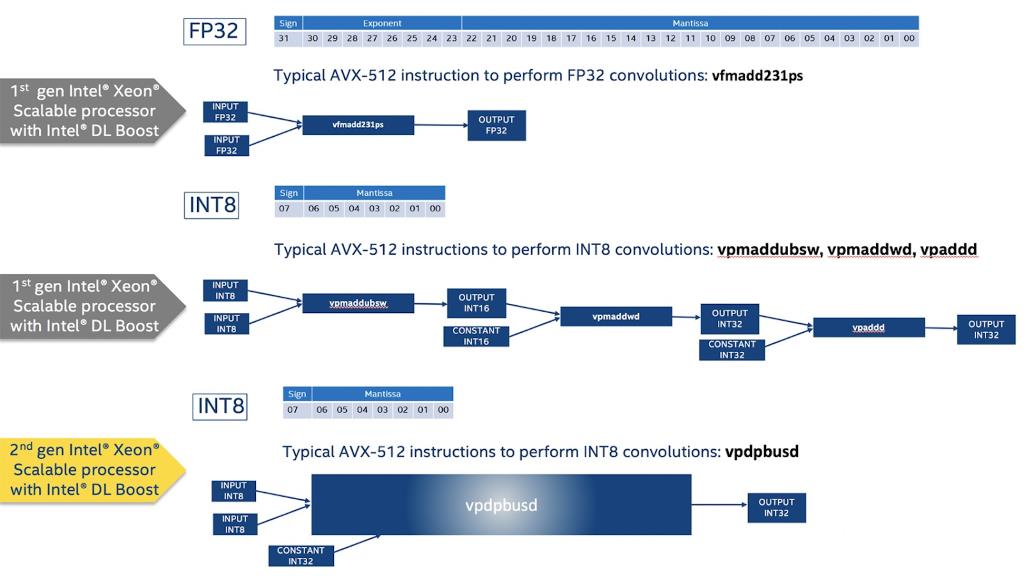
- oneAPI Deep Neural Network Library (oneDNN) is intended for deep learning applications and framework developers interested in improving application performance on Intel® CPUs (Central Processing Units) and GPUs (Graphics Processing Units) and it’s an important part of Intel oneAPI. Although Intel® oneAPI Deep Neural Network Library (oneDNN) only support a small fraction of operations defined for neural networks, they cover most computation-heavily operations which are critical for inference time optimization. Besides, Intel® oneAPI Deep Neural Network Library (oneDNN) implements matrix multiplication such as operations with u8 and s8 operands on the VNNI by using a sequence of VPMADDUBSW, VPMADDWD, VPADDD instructions. The figure below illustrates how to implement int8 convolution using VNNI.
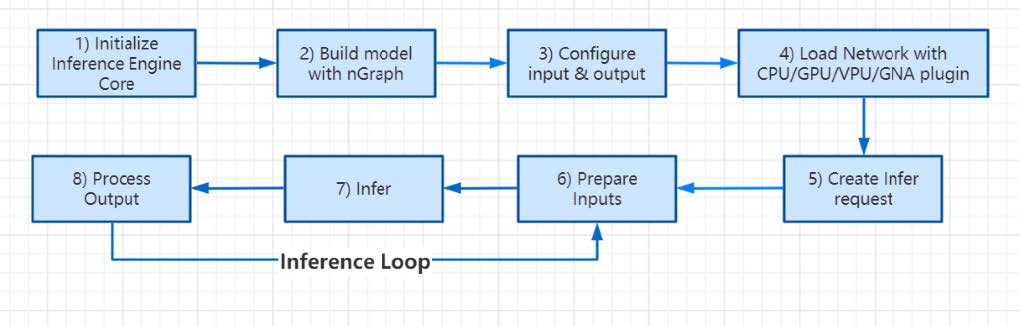
- OpenVINO toolkit for Linux* and Windows that is a comprehensive toolkit allowing to develop and deploy deep learning based solutions on Intel® platforms for native applications, the Inference Engine10 in Intel Distribution of OpenVINO toolkit is a set of C++ libraries providing a common API to access hardware including CPU, GPU, VPU and GNA, so the Inference Engine need to be implemented as a backend in Chromium using nGraph API to create Neural Network, set input and output formats, and execute the model on GNA, We wrapped the flow of building network with C API that is similar with Android NN API for C++ compatibility and generated a new binary to useofficial Intel Distribution of OpenVINO toolkit libraries.
Chromium Implementation
Chromium features is a multi-process architecture for security and stability reasons: the rendering engine and JavaScript* engine run in the unprivileged process hardened by sandbox and rely on privileged process to access hardware acceleration. We extended the Chromium rendering engine, “Blink” which runs inside a renderer process, to expose the WebNN JavaScript API. The WebNN JavaScript API was proxied to gain privileged access to the GPU process so that it could make use of hardware acceleration. We used shared-memory inter-process-communication (IPC) to improve the efficiency of transferring (pre-)trained data, inputs, and outputs.
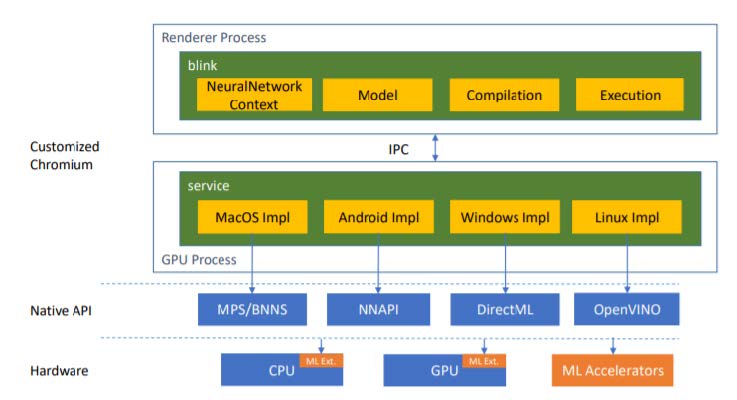
We implemented WebNN API proposal in JavaScript* “polyfill”, which can be understood as an emulated implementation of proposed functionality using pre-existing mechanisms. Polyfills are commonly used by the Web community and standards organizations to understand and illustrate proposed APIs. WebNN has four major interfaces including the neural network, model, compilation and execution, you can get a neural network context object from global navigator object, the object has method of tensor operand and operations such as conv2d, add and relu as below that is to define computational graph, then we can create a model object based on this graph that represents hardware independent form, we need to create a compilation object for hardware acceleration with compilation options such as high performance or low power, at last, we can start compute the compiled graph on hardware acceleration. For the case of speech recognition to use GNA, anOpenVINO toolkit model is parsed by JavaScript* importer library into operands and operations including fully connected and sigmod that will be used for WebNN JavaScript API, creating model will use nGraph to build Inference Engine executable network that can be inferenced with GNA plugin on GNA hardware.

Results
We adopted a use-case-driven methodology to ensure results that were meaningful and relevant to the Web Community. In this way we first collected DL use cases on the browser. These turned out to heavily favor two areas: computer vision such as image classification and text/natural language processing such as speech recognition.
VNNI Performance
For VNNI case, we select MobileNet* V1 as the test model and complete the quantization process using PyTorch*. There is a 2.56x speedup compared with fp32 model on CPU with WebNN. What’s more, for INT8 WebNN inference time, there is a 20X speedup compared with WebAssembly -optimized with SIMD(fp32) and Multi-Thread on CPU and a 16X speedup compared with WebGL(fp32). Compare with the native Intel Distribution of OpenVINO toolkit, the performance gap between native and web is much smaller. For the machine with a VNNI accelerator from Intel, the web applications can achieve much more efficient AI computation by accessing to Intel® hardware accelerators.

GNA Power and Performance
For speech recognition, we complete acoustic model inference based on Kaldi* neural networks and speech feature vectors.
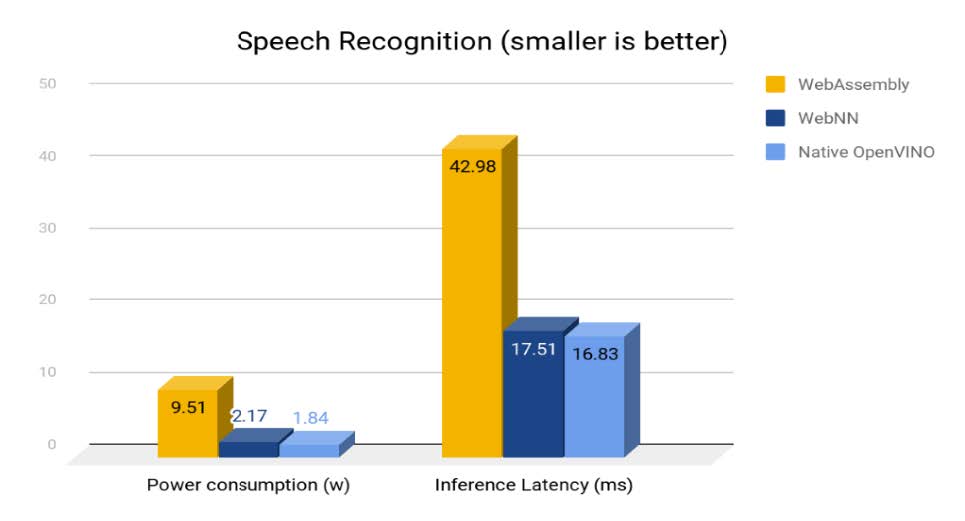
We use wsj_dnn5b_smbr model to implement the Speech Recognition that is trained by Kaldi deep learning framework and converted by the Model Optimizer tool in the Intel Distribution of OpenVINO toolkit, the input data is kaldi ARK speech feature vector file that store all speech utterances. We implemented the JavaScript* model importers that read the model format and output result as the WebNN neural network specifications. we tested the system power consumption with electricity meter and inference latency for this workload on ASUS* ZenBook i7-1165G7 Tiger Lake laptop. There are a 6x power reduction comparing to WebAssembly backend running on CPU. It also hits 96% of native performance of OpenVINO. We will continue to enable GNA on Chrome OS* for TGL platform and align with CCG Project Athena.
Summary and Standardization Work
In this paper, we presented VNNI to optimize performance and GNA to reduce power consumption with WebNN that is a dedicated low-level Web API for accessing DL hardware accelerations. Through our prototype, we have proved that, through WebNN, web applications and JavaScript ML frameworks can access Inter hardware accelerators for DL. This capability can bring much higher performance and lower power consumption to DL computation on the web.
Based on our solid results, we have launched the “Machine Learning for the Web” Community Group (WebML CG)7 in the World Wide Web Consortium (W3C) and got strong industry support including major browser vendors. The W3C* Web Machine Learning Working Group (WG) will be launched in first half of 2021 as well, formalizing hardware-accelerated Web Neural Network API optimized for Intel AI use cases per Intel®’s XPU vision.
References
1. VNNI for Intel AVX-512
2. GNA
3. Intel Distribution of OpenVINO toolkit
4. oneDNN
5. TensorFlow.js
6. ONNX.js
7. W3C Machine Learning for the Web Community Group
8. The Android Neural Networks API (NNAPI)
9. DirectML
10. Inference Engine