This article was originally published on huggingface.co on June 11, 2024.
Large multimodal models (LMM) integrate different modes of data into AI models. These L M Ms, distinct from L L Ms, can make deductions from text, audio, video, and image data, which is a recent paradigm shift in AI. The example I have for you here is one that uses text and image data, the llava-gemma-2b model. It is a derivative of the Google* Gemma-2B model and the LLaVa-1.5 model, and because of its smaller size, it can run well on a laptop.
Intel has introduced the neural processing unit (NPU) as an integrated component in its latest AI PC laptop processor — the Intel® Core™ Ultra processor. The NPU is a low-power, energy-efficient processor engine that elevates the game of AI model deployment on your local machine. One option for deployment is to use the new Intel® NPU Acceleration Library. As stated on its GitHub* page, "The Intel NPU Acceleration Library is a Python* library designed to boost the efficiency of your applications by leveraging the power of the Intel Neural Processing Unit (NPU) to perform high-speed computations on compatible hardware."
Note The Intel NPU Acceleration Library is currently in active development, with our team working to introduce a variety of features that are anticipated to dramatically enhance performance. It is not intended as a production-ready performant path but as a way to enable the developer and machine learning community to play and experiment with the NPU by prioritizing an easy developer experience. For performant, production-ready solutions, see OpenVINO™ toolkit or DirectML.
How to Get Started with the Intel® NPU Acceleration Library
In order to get up and running with the NPU on your machine, start by installing the Intel NPU Acceleration Library:
pip install intel-npu-acceleration-library
Make sure to update to the latest NPU driver for all of the latest features and best performance:
A couple of lines of code should enable the NPU on your laptop to run small LLMs or, in this case, LMMs.
After beginning running your code, to see that the NPU is working, open the Task Manager program on Windows and take a look at the usage of the NPU, as figure 1 shows.
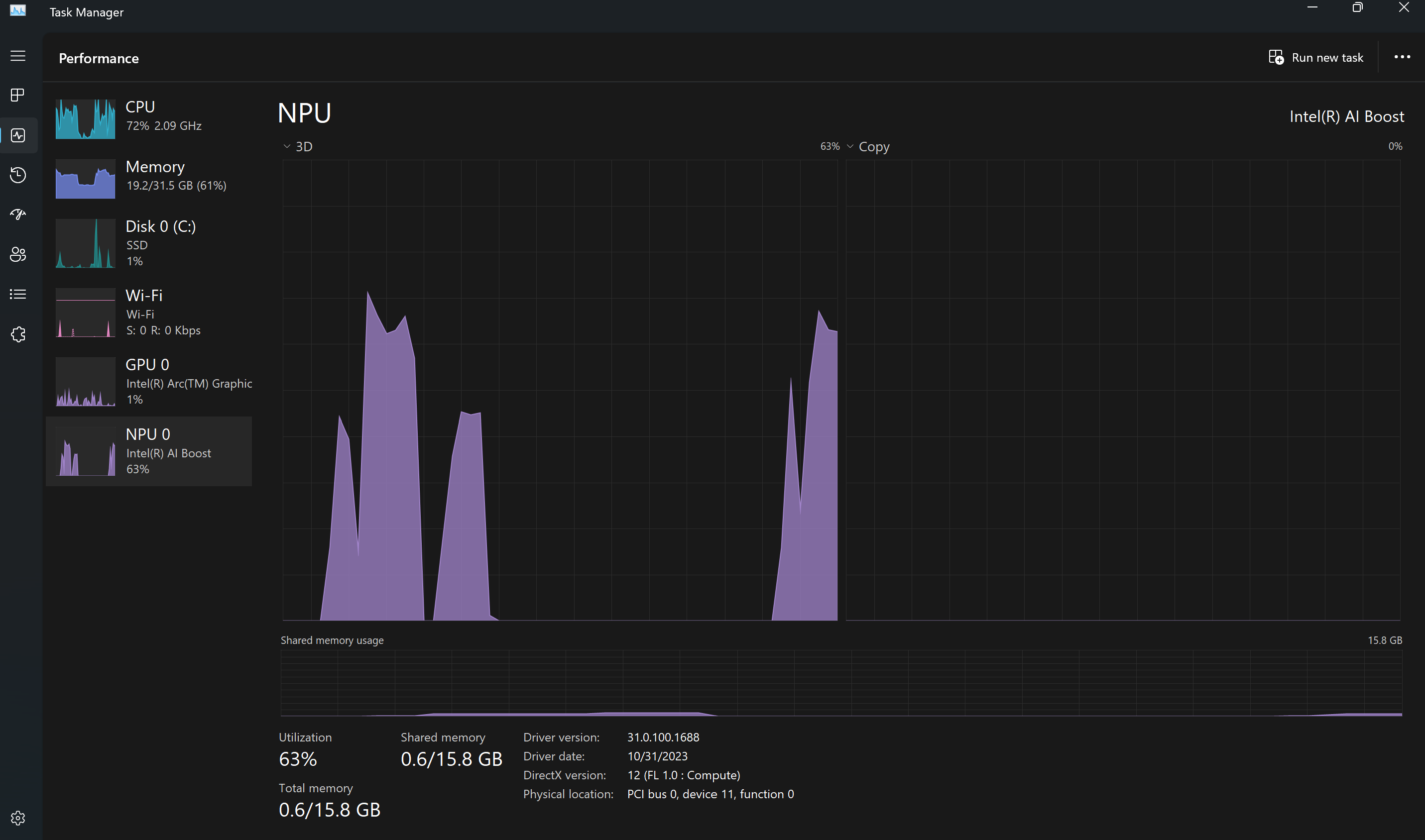
Figure 1. NPU usage on AI PC shows around 63% utilization for running inference with this model.
Following and running the example found on the model card of llava-gemma-2b, we can ask, "What's the content of the image?"

Figure 2. An example image of a stop sign courtesy of Ilan Kelman.
The model returns the following statement:
The image features a red stop sign on a
Notice that it is cut off after 30 characters. You can adjust the length that it returns by modifying the max_length=30 argument to increase the character count. You should find that inference does take longer if you increase the length.
generate_ids = model.generate(**inputs, max_length=30)
Conclusions
I showed how to run a large multimodal model (LMM) on the NPU engine of an Intel Core Ultra processor, specifically the llava-gemma-2b model. For more technical details about this model, see LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model by Hinck et al. (2024) on arXiv*.
Additional Resources
- Learn more about boosting LLM inference on AI PCs with the NPU on Medium*.
- Try the Intel NPU Acceleration Library hosted on GitHub.
- Join the Intel® DevHub on Discord* for more discussion on the AI PC. We even have an #ai-pc channel.
- Visit AI Development for all Intel® AI development software and resources.
- Incorporate Intel's other AI/machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow.
- oneAPI Unified Programming Model
- Generative AI
- AI and Machine Learning Ecosystem: Hugging Face*