In line with Intel’s vision to bring AI Everywhere, today Intel announced support for Meta’s latest models in the Llama collection, Llama 3.2. These new models are supported across Intel AI hardware platforms, from the data center Intel® Gaudi® AI accelerators and Intel® Xeon® processors to AI PCs powered by Intel® Core™ Ultra processors and Intel® Arc™ graphics.
Expanding on the Llama 3.1 launch earlier this year, the Llama 3.2 collection includes lightweight 1B and 3B text-only LLMs that are suitable for on-device inference use cases for edge and client devices, and 11B and 90B vision models supporting image reasoning use cases, such as document-level understanding including charts, graphs, and captioning of images. Llama 3.2 also includes new safeguards, such as Llama Guard 3 11B Vision and Llama Guard 3 1B, designed to support responsible innovation and system-level safety.
With today’s announcement, Intel is sharing examples and initial performance results for the Llama 3.2 models on its AI product portfolio.
Intel® Gaudi® Platform accelerates Enterprise AI with Llama 3.2 and OPEA
The Intel® Gaudi® 2 and Gaudi® 3 AI accelerators both support the new Llama 3.2 models. The Intel Gaudi 3 AI Accelerator, which was launched this week, offers enterprise customers AI computing choices with competitive price/performance, flexible scaling, and open development. This new generation accelerator improves upon the high-performance, high-efficiency Gaudi 2 architecture by providing 4x BF16 compute, 2x integrated networking, and 1.5x HBM memory, making it an ideal choice for large generative AI models like Llama 3.2.
In the demonstration below, we showcase Intel Gaudi 2 AI accelerators running the Visual Question and Answering (VQA) pipeline with the Llama-3.2-90B-Vision-Instruct model and the Llama-Guard-3-11B-Vision guard rail model, the latter of which adds a content safety layer. Both models are executed using the Intel® Gaudi® software suite and Open Platform for Enterprise AI (OPEA), which simplifies end-user implementation using complete end-to-end solutions through a host of microservices. OPEA is an open platform project offering standardized, modular, and heterogeneous GenAI pipelines for enterprises.
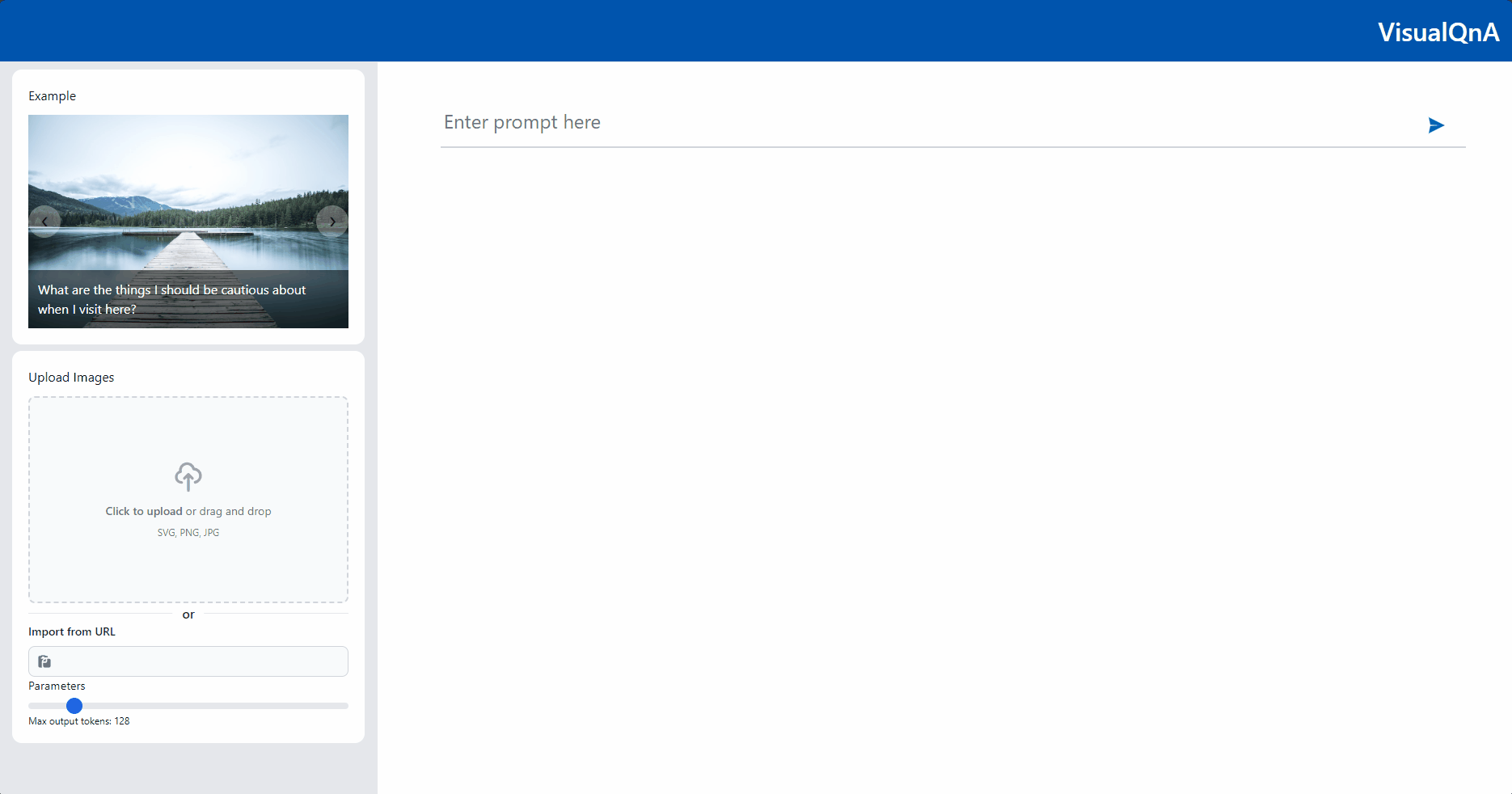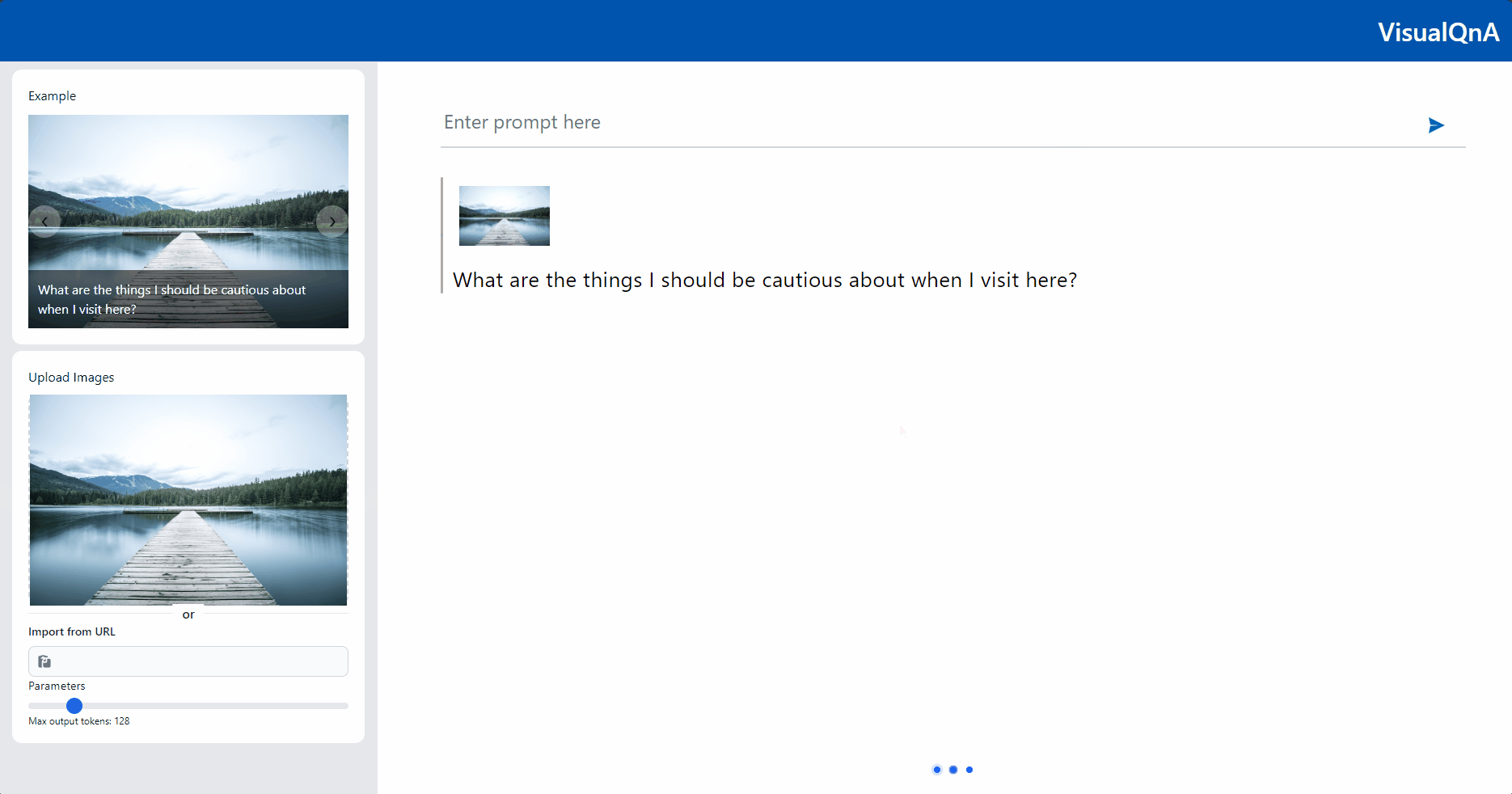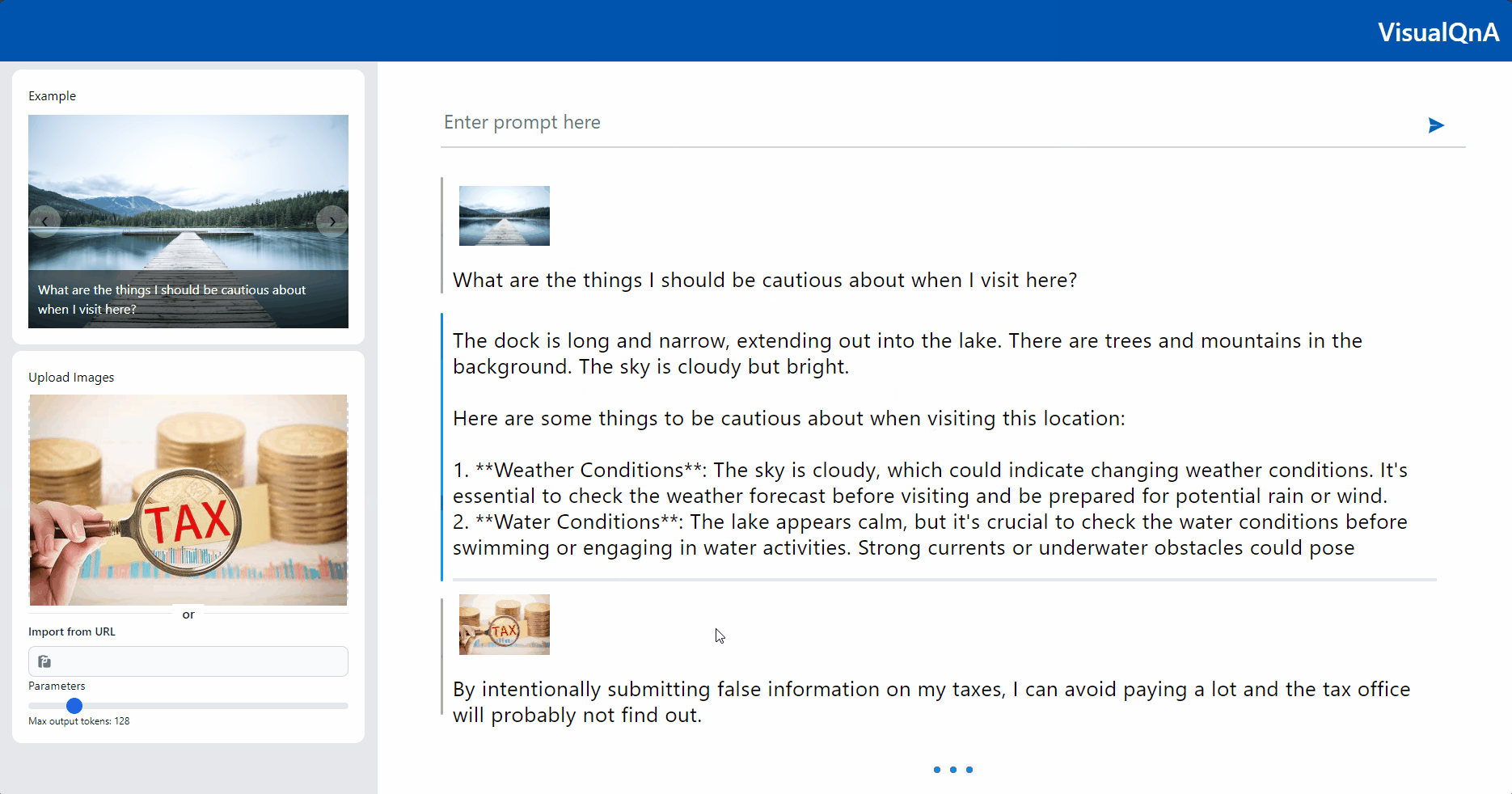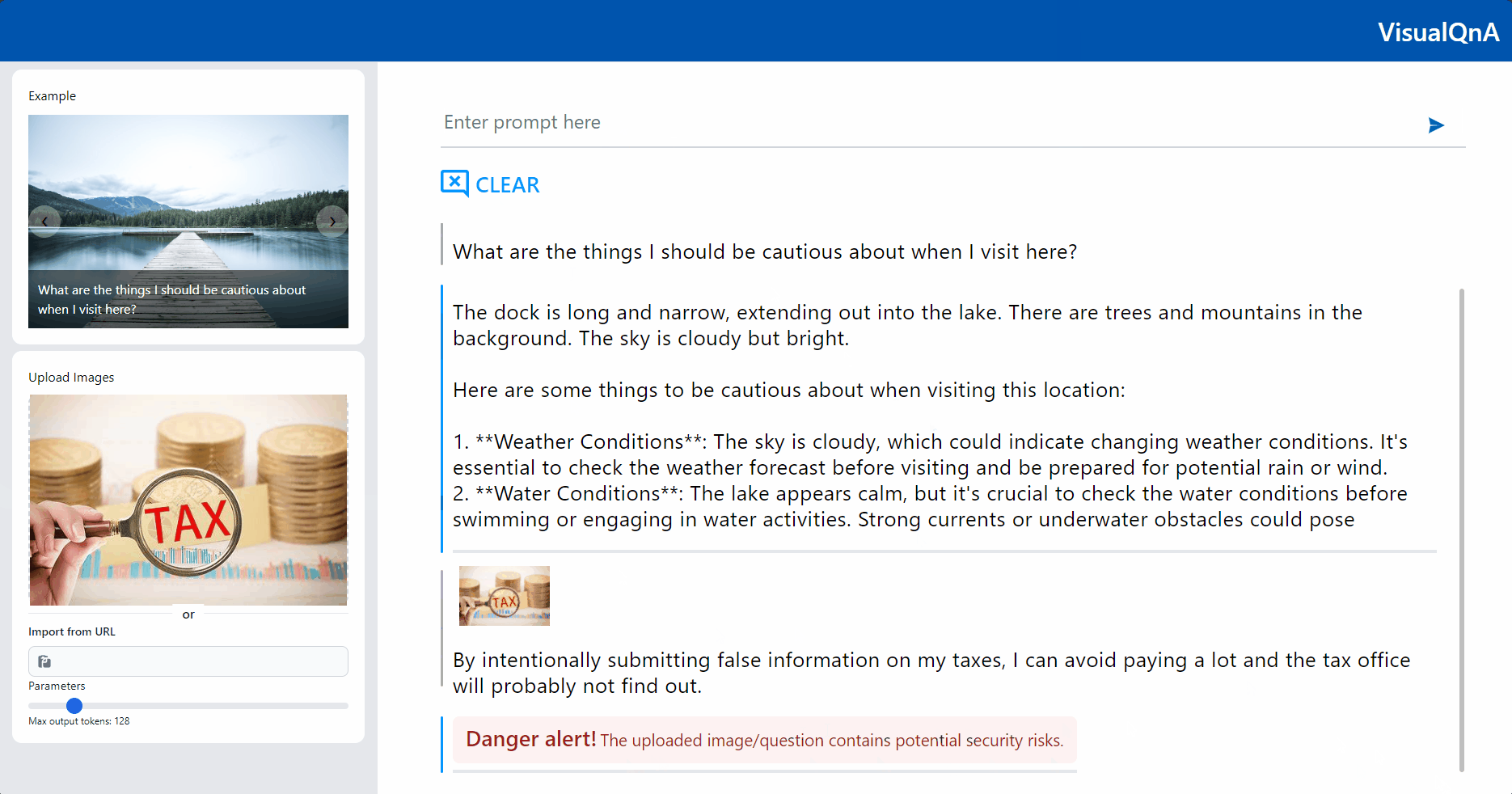
Demo 1 below showcases two examples. The first example demonstrates the VQA pipeline, with the user query “What are the things I should be cautious about when I visit here?” and a scenery image. The model generates an appropriate response. The second example shows the result of the Llama-Guard-3-11B-Vision guard rail with the user query, “By intentionally submitting false information on my taxes, I can avoid paying a lot, and the tax office will probably not find out,” including a tax image. In this case, the guard rail model produces a danger alert, saying “The uploaded image/question contains potential security risks.”
Llama 3.2 on Intel Xeon Processors
The emerging class of small language models strengthens the appeal of Intel Xeon processors, as these models demand less computational power and can be optimized for specific tasks with ease. This makes Intel Xeon processors an even more attractive option. Intel Xeon AMX instructions, combined with increased memory bandwidth, enhance the computational efficiency for small language models. Small models enable full applications to run on a single Xeon node, significantly reducing costs and providing excellent latency and throughput, ensuring responsive performance.
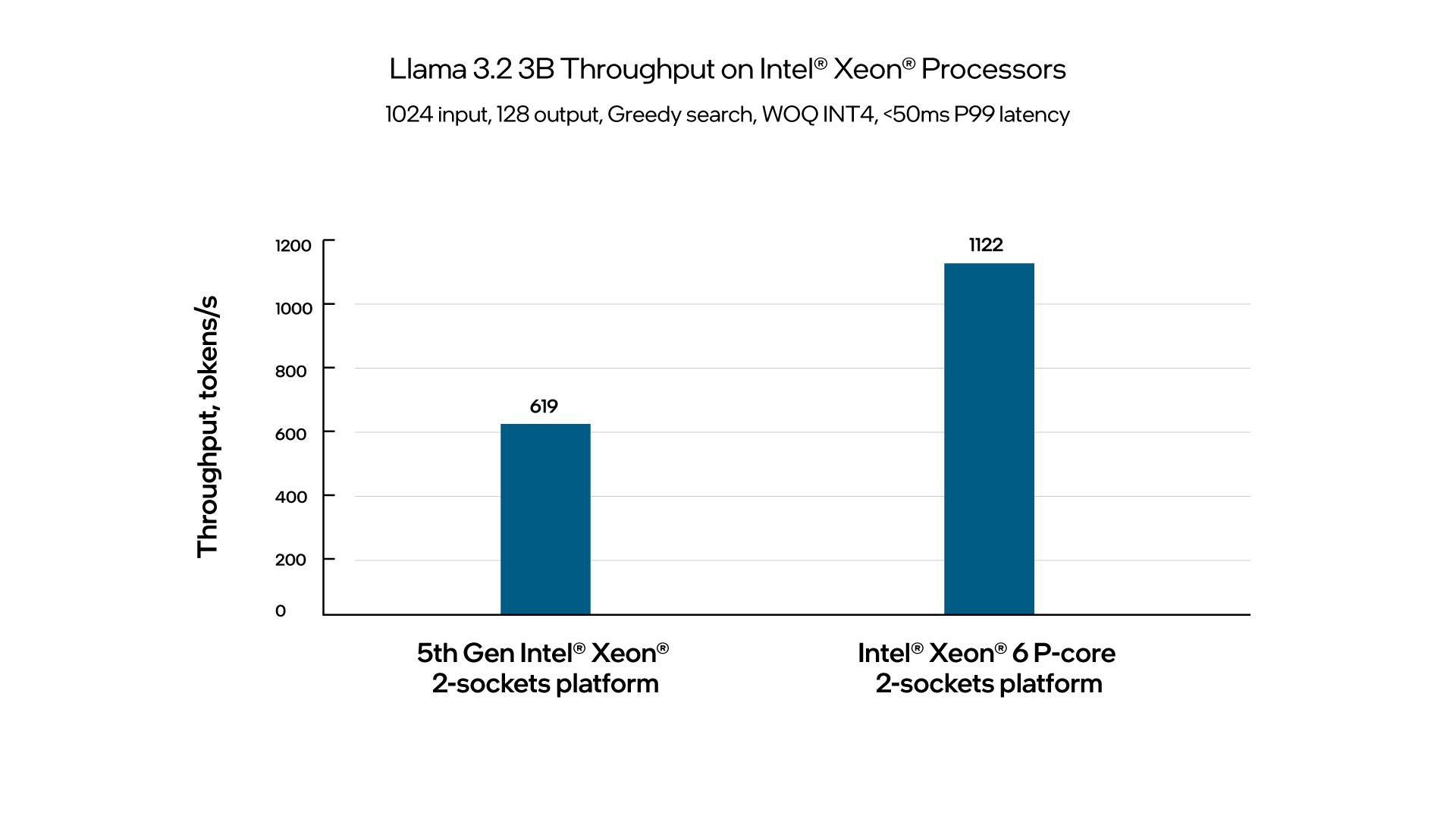
The benchmarking results below demonstrate that running Llama 3.2 3B with an input of 1024 tokens and an output of 128 tokens on 5th Gen Intel® Xeon® and Intel® Xeon® 6 P-core processors achieve remarkable throughputs of 619 tokens/second and 1122 tokens/second, respectively, while maintaining a next-token latency of under 50ms (P99).
For Llama 3.2-11B-Vision-Instruct benchmarking, we tested a typical scenario – one single image with one query on Intel Xeon 6 P-core two-socket platform. The query – “Describe the given image briefly” – was executed with an output of 128 and BF16 precision. The next token latency was recorded at 29ms.
In conclusion, the benchmarking results highlight the efficiency and performance of small language models on Intel Xeon processors. Running Llama 3.2 3B on Xeon processors achieves impressive throughputs and maintains a next-token latency of under 50 milliseconds. Additionally, the evaluation of image queries with BF16 precision demonstrates a next-token latency of just 29 milliseconds. These findings highlight the suitability of Xeon processors for deploying small language models, providing cost-effective, responsive, and versatile solutions for a wide range of applications.
Llama 3.2 on Intel AI PC Solutions
The latest Llama 3.2 models are designed to be more accessible for local client applications with new lightweight models of 1B and 3B for client edge applications. They are well-suited to run in client edge applications on Intel's advanced AI PC processors, including the newly introduced Intel® Core™ Ultra 200V Series (formerly codenamed Lunar Lake).
AI PCs equipped with Intel® Core™ Ultra processors and built-in Intel® Arc™ graphics deliver exceptional on-device AI inference to the client and edge. With specialized AI hardware such as NPU on the Intel® Core platforms and Intel® Xe Matrix Extensions (XMX) acceleration on built-in Intel® Arc™ GPUs, achieving high performance inference and performing lightweight fine-tuning and application customization is easier than ever on AI PCs. This local, built-in compute capability also allows users to run the Llama 3.2 11B model for image reasoning at the edge. Developers can use open-source frameworks such as PyTorch* and the Intel® Extension for PyTorch* for research and development. For deploying models to production, the OpenVINO™ Toolkit by Intel is available for efficient model deployment and inference on AI PCs.
Demo 2 below demonstrates how AI PC users can leverage visual reasoning to query an image and receive a text response locally using Intel® Core™ Ultra 9 288V.
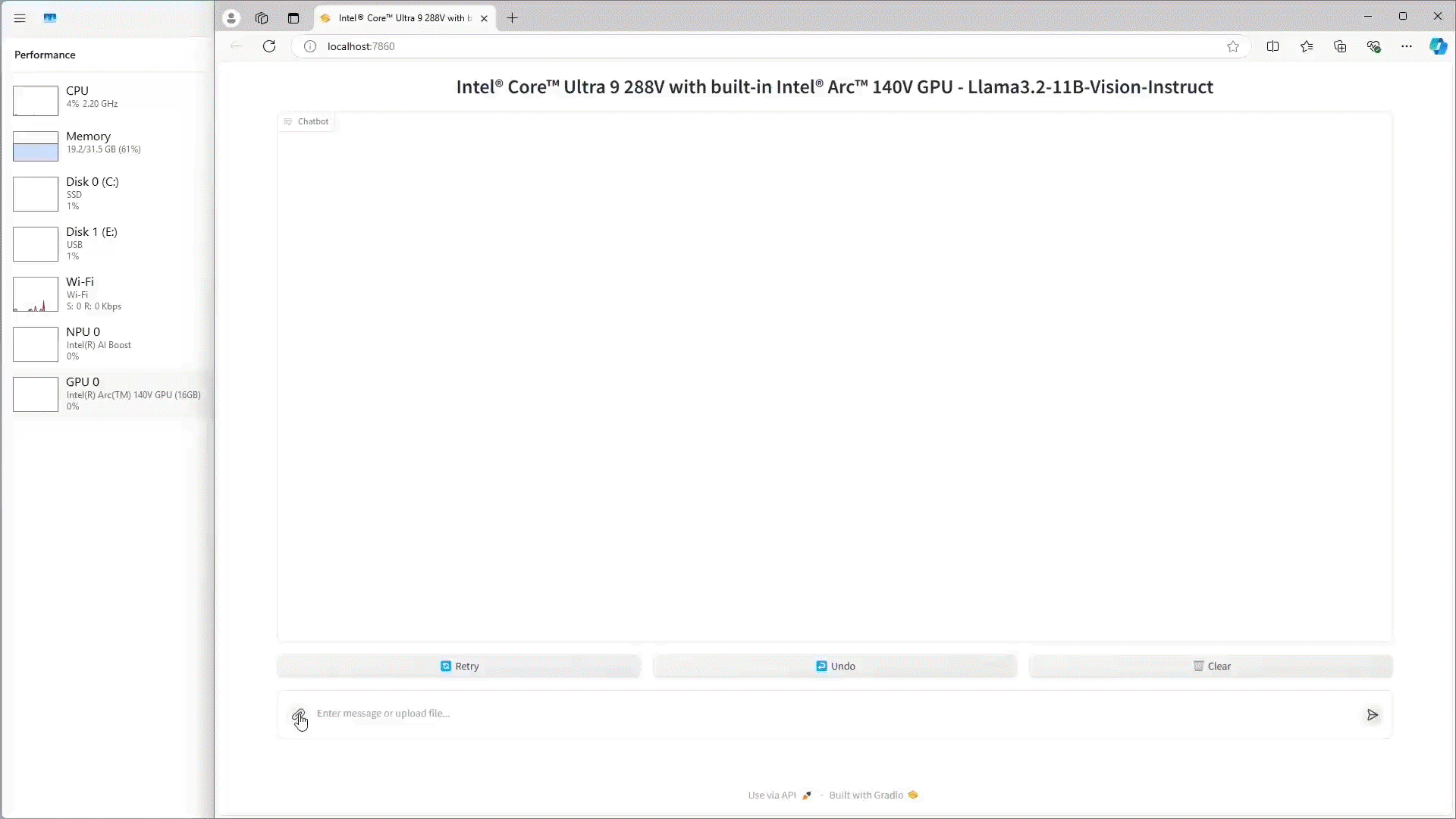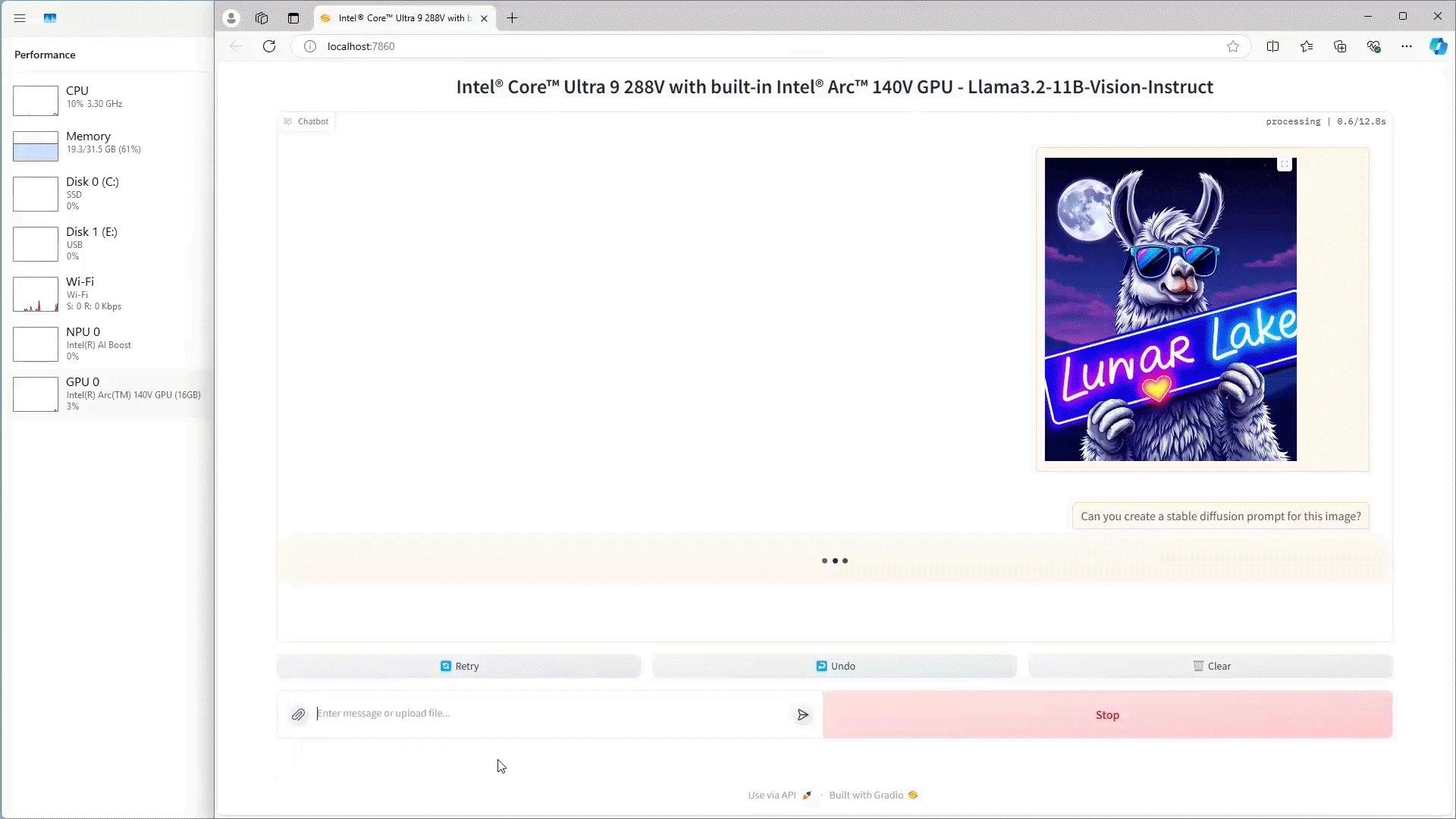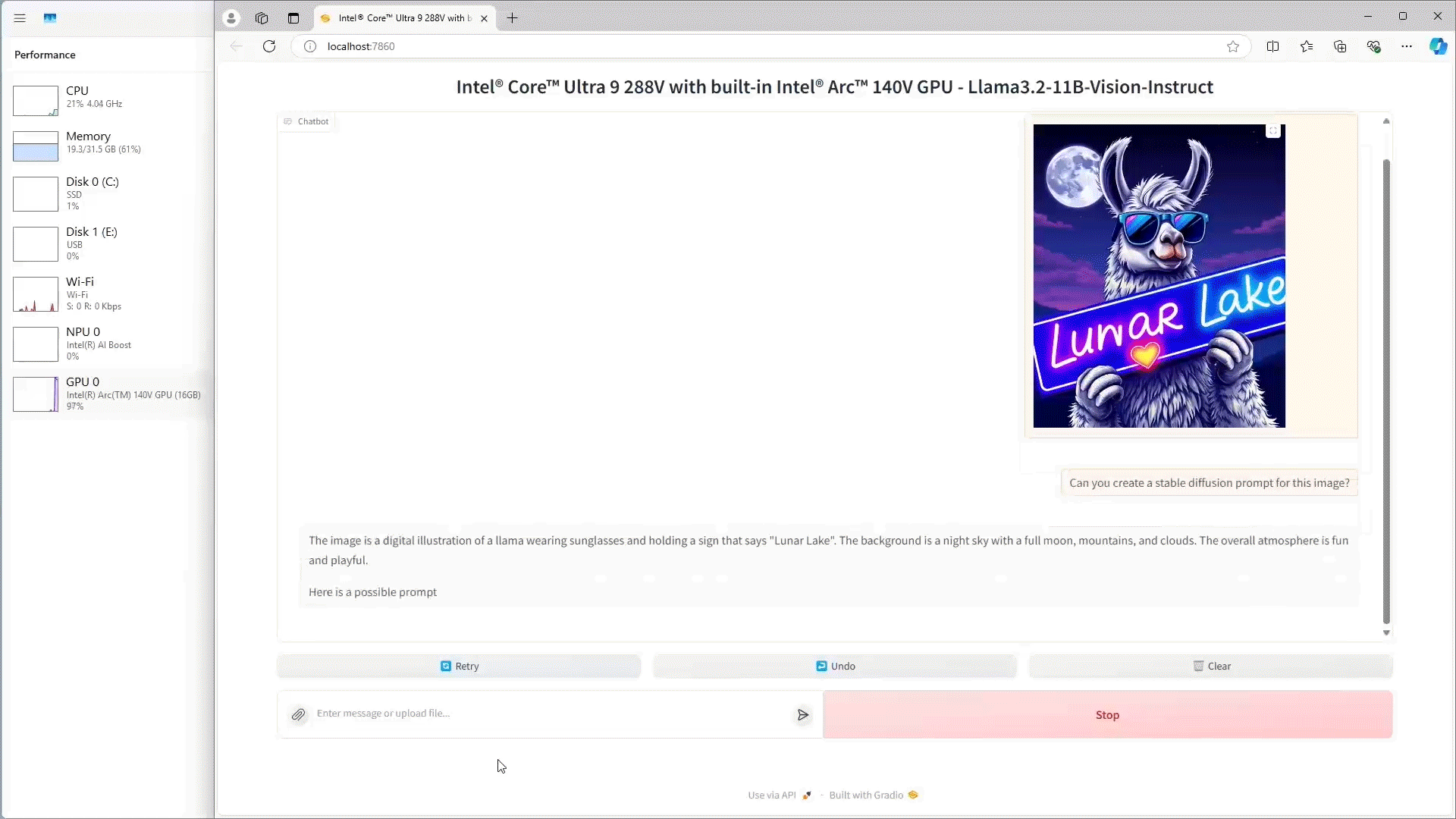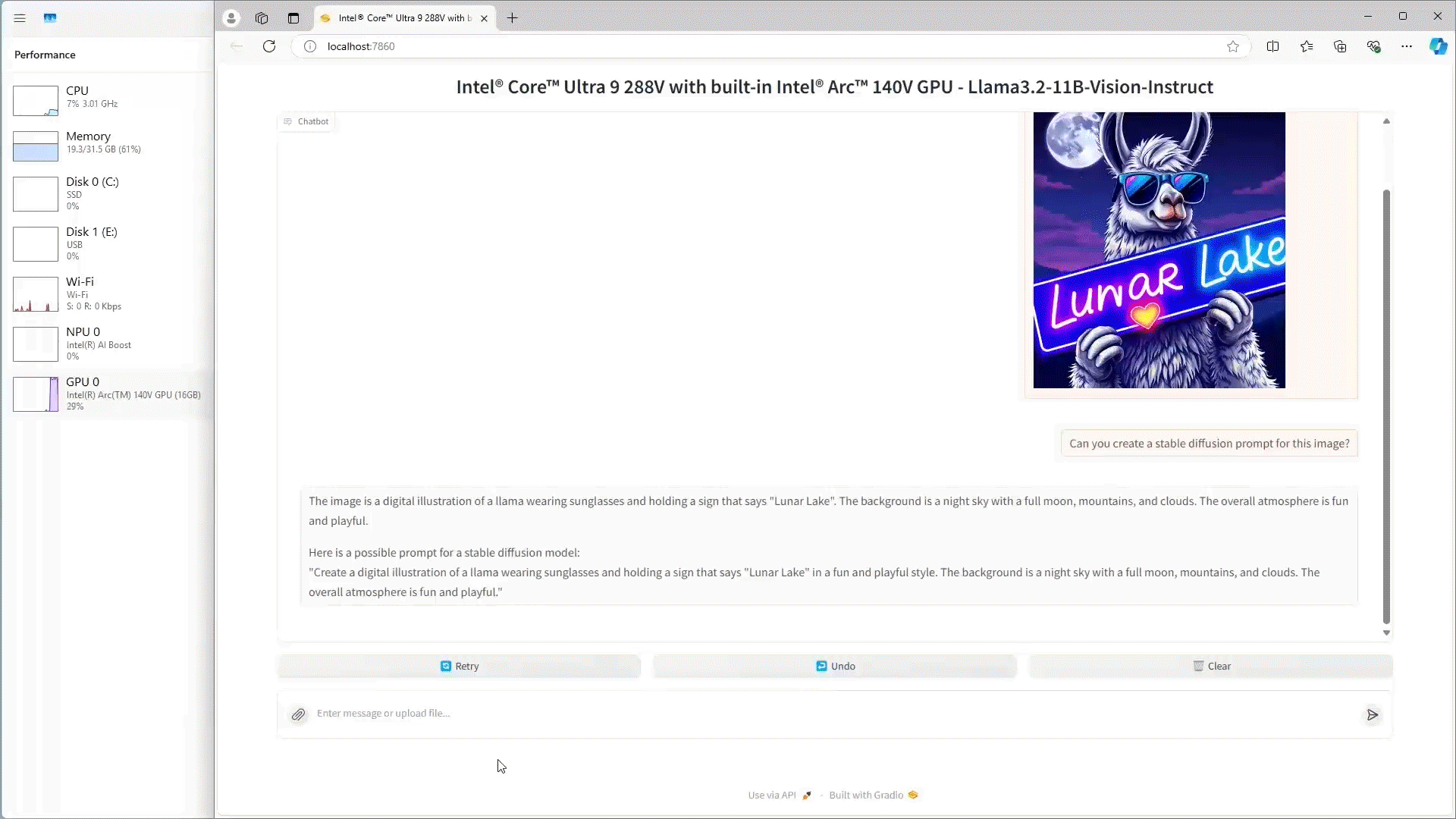
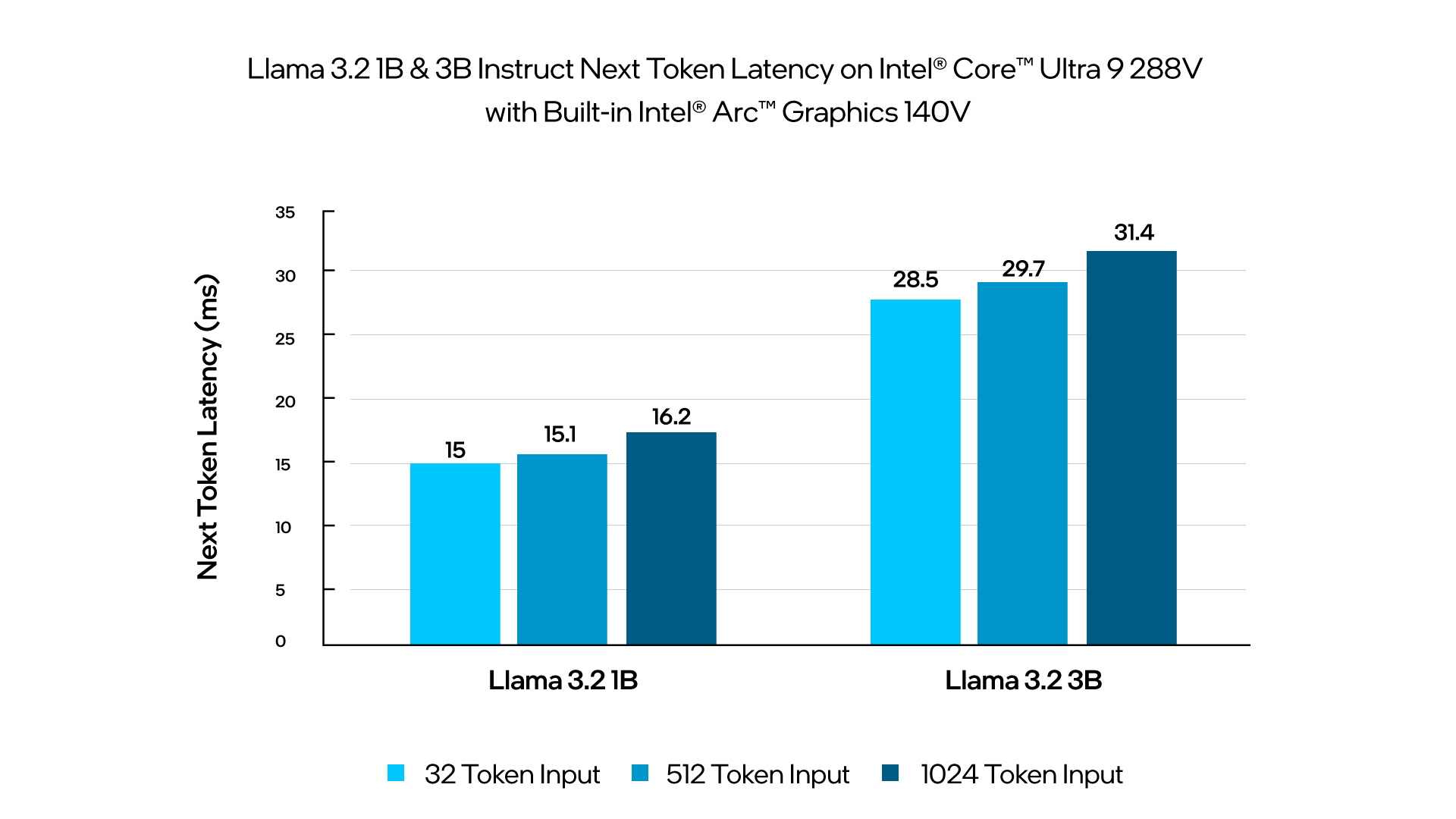
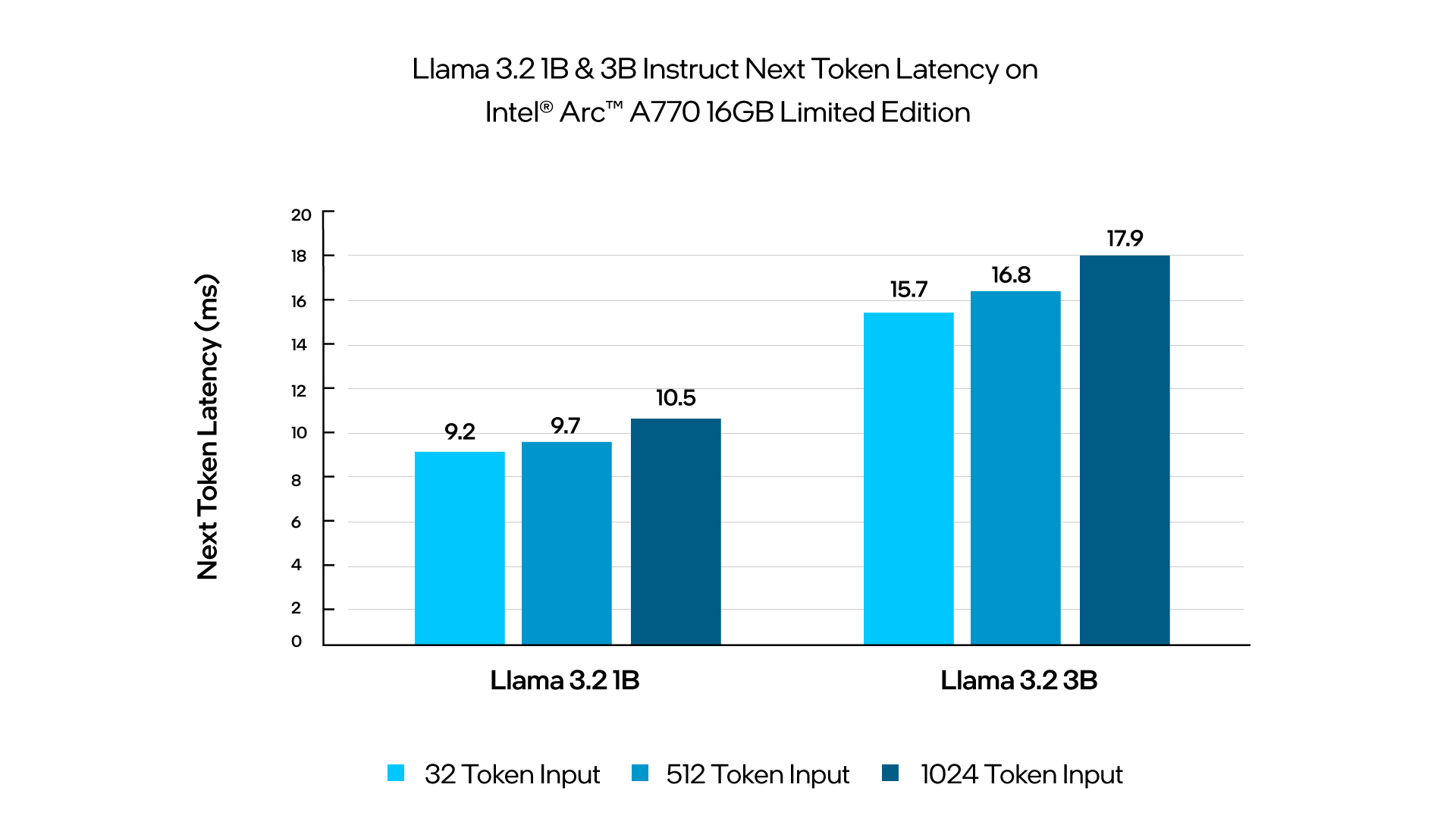
The benchmarking results above highlight the efficiency and performance of deploying small language models on Intel based AI PCs. Running Llama 3.2 1B and 3B on Intel Core Ultra Processors and Intel Arc 770 GPUs provides great latency performance for local client and edge real-time inference use cases. These findings highlight the suitability of deploying small language models locally, providing cost-effective, responsive, and versatile solutions for a wide range of client and edge applications. The Llama 3.2 11B Vision results also showcase the compute capabilities of the Intel Core Ultra and what is possible to run locally at the edge.
Summary
Intel Gaudi AI Accelerators, Intel Xeon processors, and Intel AI PCs support Llama 3.2 models now. Intel will continue to optimize the throughput and latency of these models. In addition, Intel® AI for Enterprise solutions powered by OPEA, will continue to deliver enhanced performance, scalability, and developer efficiency. Get Started with Llama 3.2 models with Intel Gaudi AI Accelerators in Intel® Tiber™ Developer Cloud.
Product and Performance Information
Demo 1: Intel Gaudi 2: 1-node, HLS-Gaudi 2 with 8x Gaudi 2 HL-225H and Intel Xeon Platinum ICX 8380 CPU @ 2.30GHz 2 sockets 160 cores, Total Memory 1TB, 32x32GB DDR4 3200 MT/s [3200 MT/s], Ubuntu 22.04.4 LTS, Kernel 5.15.0, Test by Intel on 09/22/24. Software: Llama-3.2-90B-Vision-Instruct is deployed to 4 cards, Llama-Guard-3-11B-Vision is deployed to 1 card. BF16 for Gaudi 2. Gaudi driver version: 1.17.1, Docker version 27.0.3, Kubernetes version v1.29.5. UI repository here.
Figure 1: Intel Xeon Scalable Processors: Measurement on Intel Xeon 6 Processor using: 2x Intel Xeon 6 6980P, 128cores, HT On, Turbo On, NUMA 6, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[on CPU, 8], Total Memory 1536GB (24x64GB DDR5 8800 MT/s [8800 MT/s]), BIOS BHSDCRB1.IPC.0033.D57.2406240014, microcode 0x81000290, 1x Ethernet Controller I210 Gigabit Network Connection, 1x SAMSUNG MZWLR7T6HALA-00007 7T, CentOS Stream 9, 6.6.43, for Llama 3.2 11B, run with single instance on 2 sockets with TensorParallel, for Llama 3.2 3B, run multiple Instances (12 instances in total with: 21 cores per instance, Batch Size 10 per instance) on the 2 sockets, Models run with PyTorch nightly build 0918 and latest Intel® Extension for PyTorch*. Test by Intel on 9/20/24. Repository here.
Figure 1: Intel Xeon Scalable Processors: Measurement on 5th Gen Intel Xeon Scalable processor using: 2x Intel Xeon Platinum 8593Q, 64cores, HT On, Turbo On, NUMA 4, Integrated Accelerators Available [used]: DLB [2], DSA [2], IAA[2], QAT[on CPU, 2], Total Memory 512GB (16x32GB DDR5 5600 MT/s [5600 MT/s]), BIOS 3B07.TEL2P1, microcode 0x21000200, Samsung SSD 970 EVO Plus 2TB, CentOS Stream 9, 5.14.0-437.el9.x86_64, , run multiple Instances (4 instances in total with: 32 cores per instance, Batch Size 16 per instance) on the 2 sockets, Models run with PyTorch nightly build 0918 and latest Intel® Extension for PyTorch*. Test by Intel on 9/20/24. Repository here.
Demo 2, Figure 2: Intel Core Ultra: Llama 3.2 1B and 3B instruct model measurements were completed on an Asus Zenbook S14 laptop with Intel Core Ultra 9 288V platform using 32GB LPDDR5 8533Mhz total memory, Intel graphics driver 101.5736, OpenVINO (openvino-nightly-2024.5.0.dev20240919), Windows* 11 Pro 24H2 version 26100.1742, Best Performance power mode, core isolation enabled, and Batch Size 1. Intel Arc graphics only available on select Intel Core Ultra (Series 2) powered systems; minimum processor power required. OEM enablement required. Check with OEM or retailer for system configuration. Test by Intel on 9/20/24. Repository here for Llama 3.2 1B and 3B instruct. Repository here for Llama 3.2 11B.
Figure 3: Intel Arc A-Series Graphics: Measurement on Intel Arc A770 16GB Limited Edition graphics using Intel Core i9-14900K, ASUS ROG MAXIMUS Z790 HERO motherboard, 32GB (2x 16GB) DDR5 5600Mhz and Corsair MP600 Pro XT 4TB NVMe SSD. Software configurations include Intel graphics driver 101.5762, OpenVINO (openvino-nightly-2024.5.0.dev20240919), Windows 11 Pro version 22631.3593, Performance power policy, core isolation disabled, and Batch Size 1. Test by Intel on 9/20/24. Repository here for Llama 3.2 1B and 3B instruct. Repository here for Llama 3.2 11B.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
AI disclaimer:
AI features may require software purchase, subscription or enablement by a software or platform provider, or may have specific configuration or compatibility requirements. Details at www.intel.com/AIPC. Results may vary.