To bring AI everywhere, Intel continuously invests in the AI software ecosystem and ensures new models are optimized for Intel’s AI hardware. Today, Intel is providing performance data and optimizations across its data center, edge, and client AI products for Llama 3.1, the latest large language models (LLMs) from Meta*.
Following the launch of Llama 3 in April, Meta today released Llama 3.1, its most capable models to date. Llama 3.1 brings several new, updated models across a spectrum of sizes and capabilities, including Llama 3.1 405B – the largest openly available foundation model. These new models are enabled and optimized on Intel AI products with open ecosystem software such as PyTorch* and Intel® Extension for PyTorch*, DeepSpeed*, Hugging Face* Optimum libraries, and vLLM. These models are also supported by Open Platform for Enterprise AI (OPEA), a new open platform project within the LF AI & Data Foundation for creation of open, multi-vendor, robust, and composable GenAI solutions that harness the best innovations across the ecosystem.
The Llama 3.1 collection of multilingual LLMs is a collection of pre-trained and instruction tuned generative models in 8B, 70B and 405B sizes (text in/text out). All models support long context length (128k) with support across eight spoken languages. Llama 3.1 405B has state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation. It will enable the community to unlock new capabilities, such as synthetic data generation and model distillation. For more information on Llama 3.1, see the blog.
Today, we are sharing our initial performance results of Llama 3.1 models on the Intel AI product portfolio, including Intel® Gaudi®, Intel® Xeon®, and AI PCs powered by Intel® Core™ Ultra processors and Intel® Arc™ graphics.
Get optimal performance with Llama 3.1
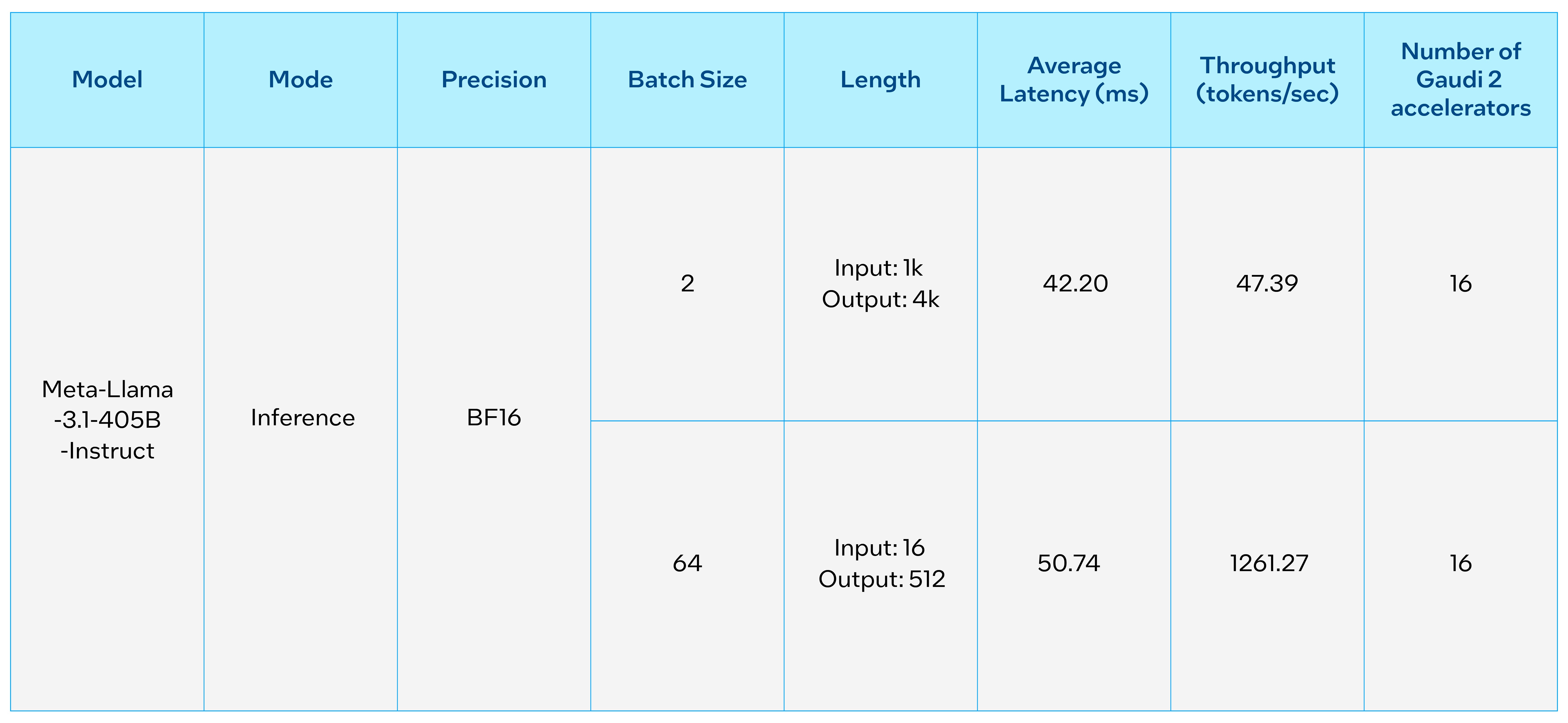
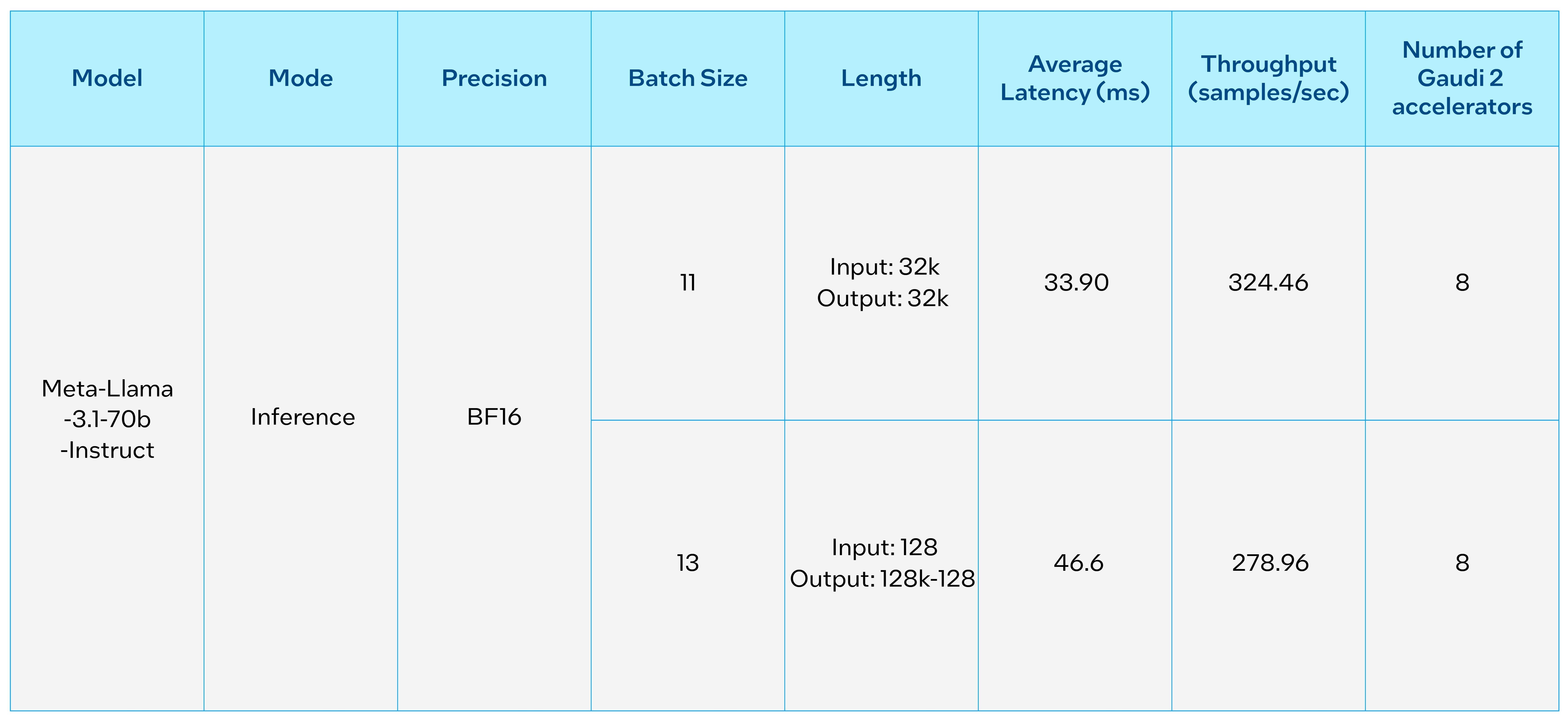
The Intel® Gaudi® AI accelerators are designed for high-performance acceleration of Generative AI and LLMs. The tables below provide Intel Gaudi 2 performance measurements for inference on the new Llama 3.1 70B and 405B models. These initial performance measurements for the 405B model were done on two nodes with 8 Gaudi 2 accelerators each. With the maturity of Intel Gaudi software, users can easily run the new Llama 3.1 models and quickly generate results for inference.
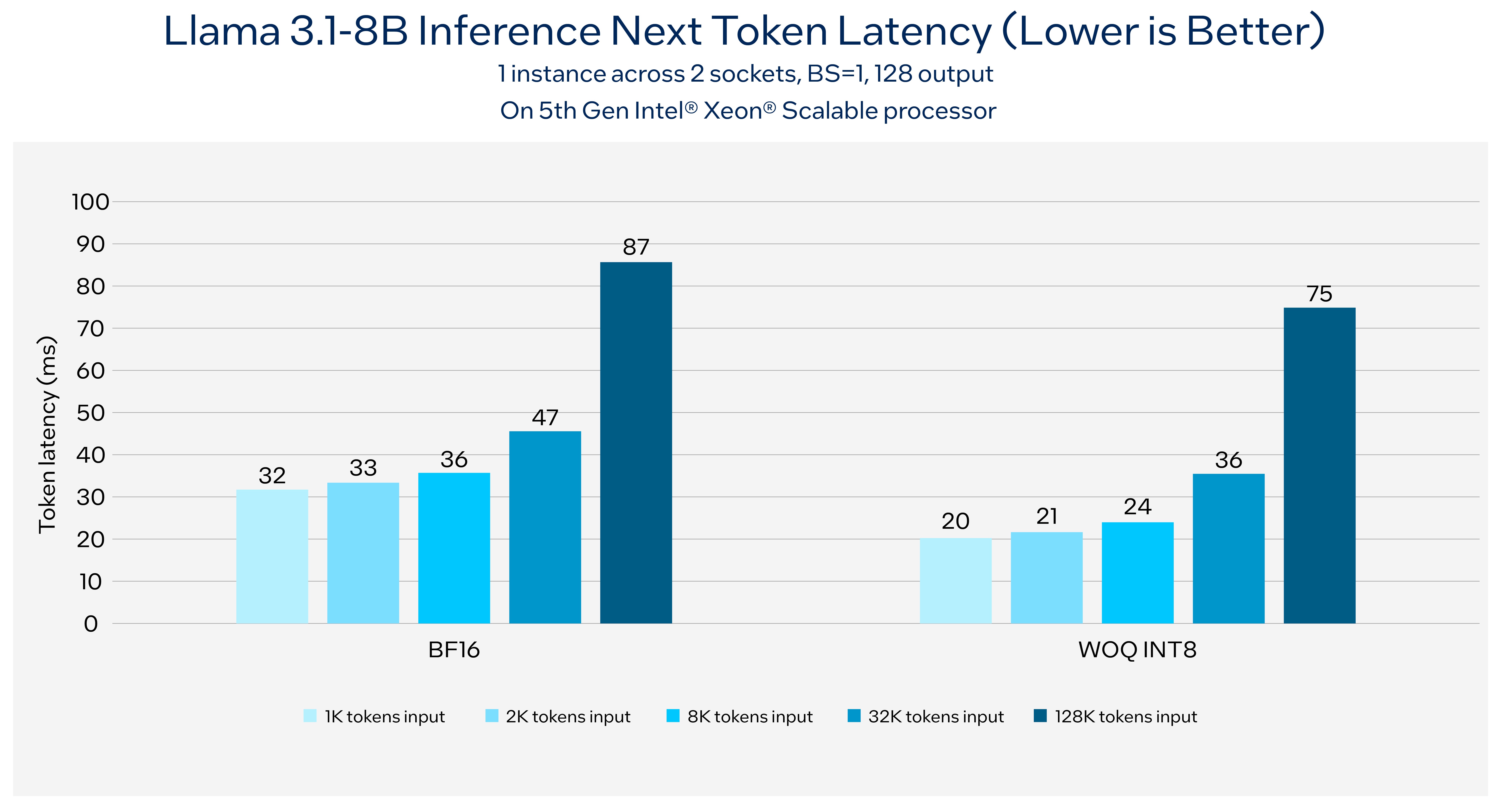
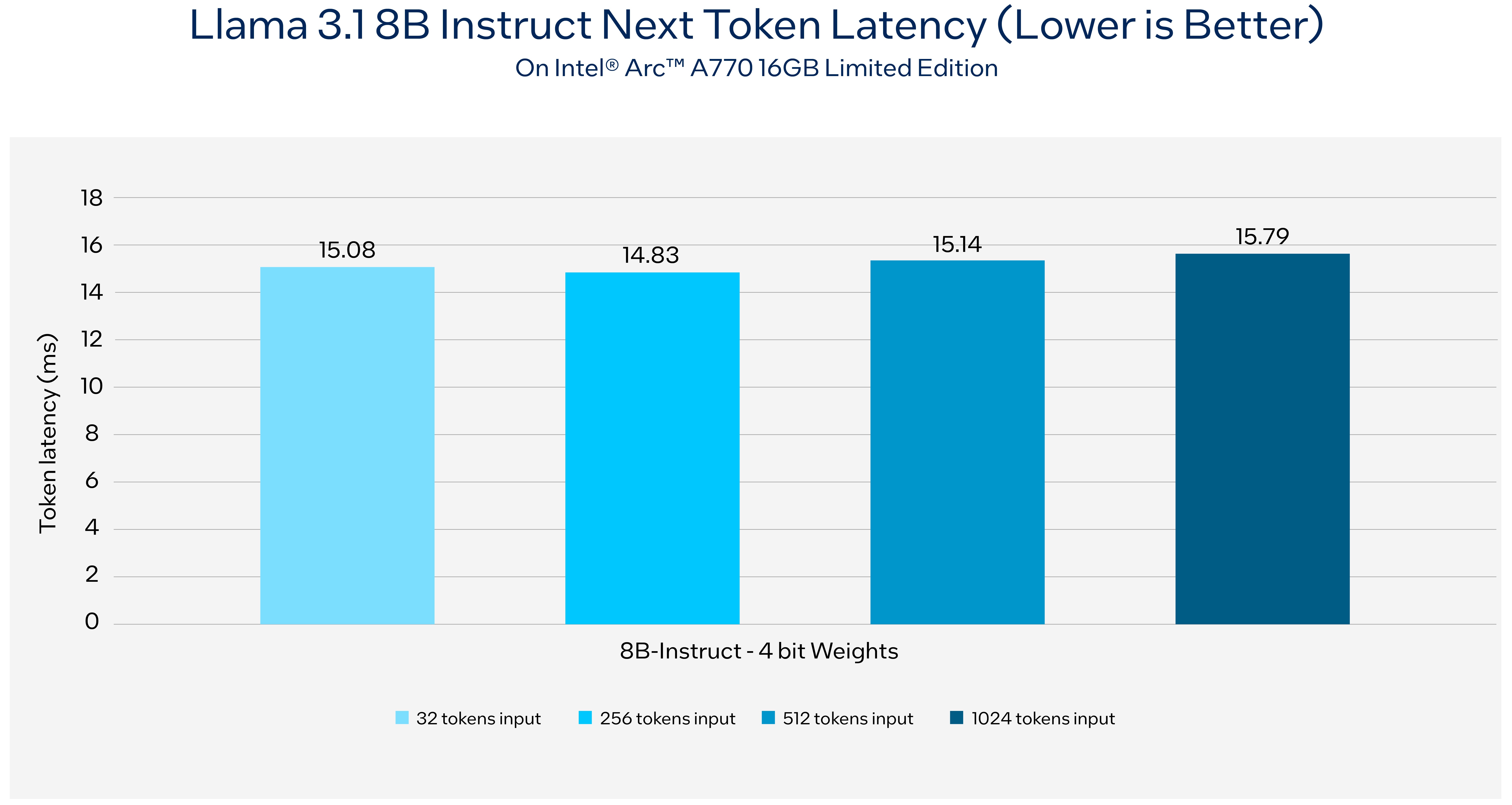
Intel® Xeon® processors are the ubiquitous backbone of general compute, offering easy access to powerful computing resources across the globe. Available today across all major cloud service providers, Intel Xeon processors have Intel® Advanced Matrix Extensions (AMX), an AI engine in every core that unlocks new levels of performance for AI performance. Per benchmarking, running Llama3.1 8B with 1K tokens input and 128 tokens output can reach 176 tokens/second throughput on 5th Gen Intel® Xeon® platform while keeping the next token latency less than 50ms. Figure 1 shows the next token latency can be less than 100ms with the longest supported 128K context length with Llama 3.1 8B.
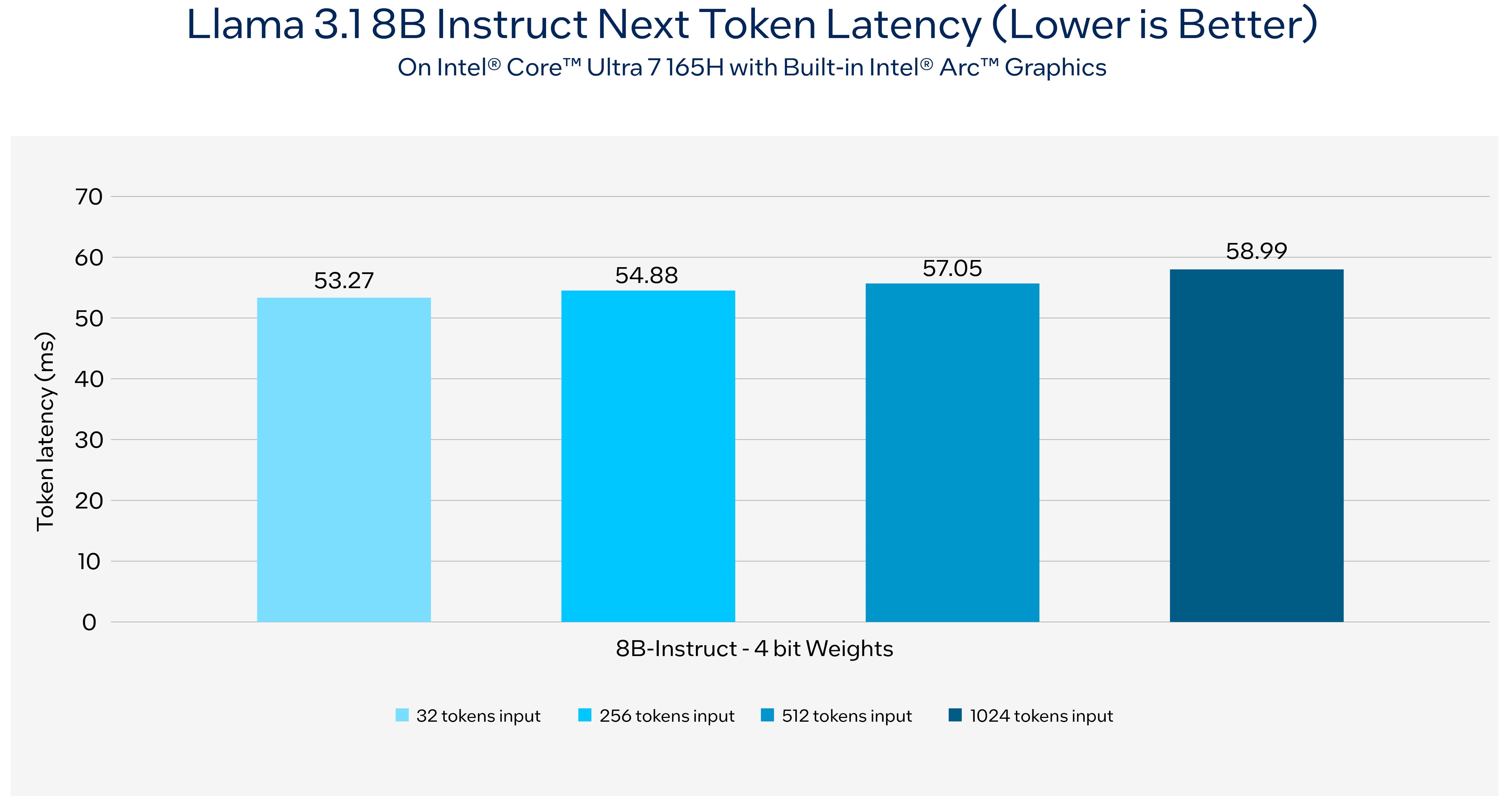
AI PCs powered by Intel® Core™ Ultra processors and Intel® Arc™ graphics deliver exceptional on-device AI inference to the client and edge. With specialized AI hardware such as NPU on the Intel® Core platforms and Intel® Xe Matrix Extensions acceleration on Arc GPUs, lightweight fine-tuning and application customization is easier than ever on AI PCs. For local research and development, open ecosystem frameworks like PyTorch and Intel Extension for PyTorch are enabled and accelerated. For production, users can leverage the OpenVINO™ Toolkit from Intel for efficient model deployment and inference on AI PCs. AI workloads can be seamlessly deployed across CPUs, GPUs, and NPUs for optimized performance.
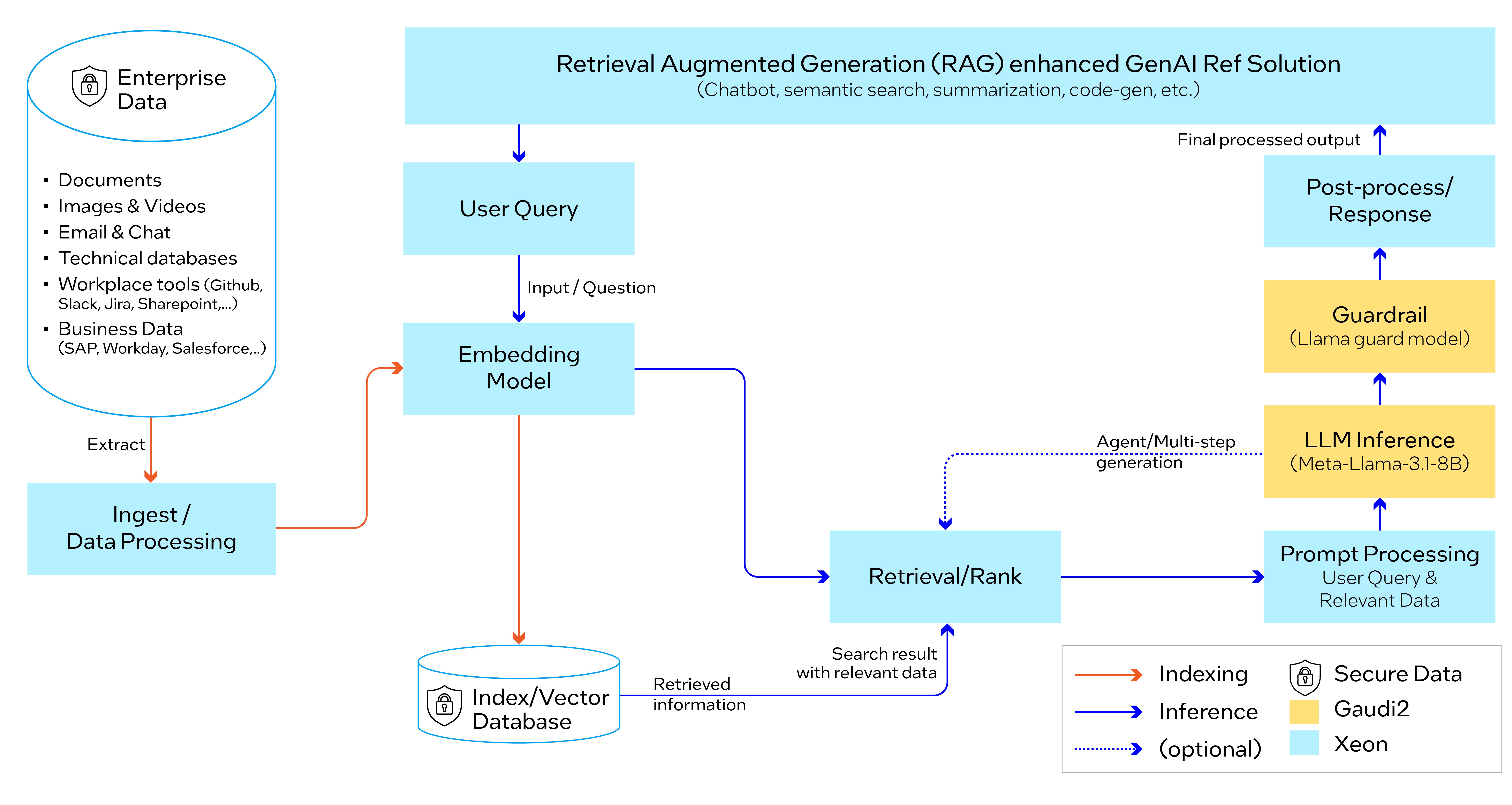
Deploy Enterprise RAG solution with Llama 3.1 and OPEA
Intel’s AI platform and solutions accelerate enterprise AI RAG deployments. As a founding member of Open Platform for Enterprise AI (OPEA), Intel is helping spearhead the creation of an open ecosystem for Enterprise AI. This blog showcases that OPEA is enabled with Llama 3.1 models and optimized for performance.
OPEA offers open source, standardized, modular, and heterogeneous RAG pipelines for enterprises. It is built on composable and configurable multi-partner components. For this evaluation, microservices are deployed in the OPEA blueprint (Guardrail, Embedding, LLM, Data Ingestion, and Retrieval). E2E RAG pipeline uses Llama 3.1 for LLMs inference and Guardrail, BAAI/bge-base-en-v1.5 for embedding, Redis for Vector DB, and Kubernetes (K8s) for orchestration.
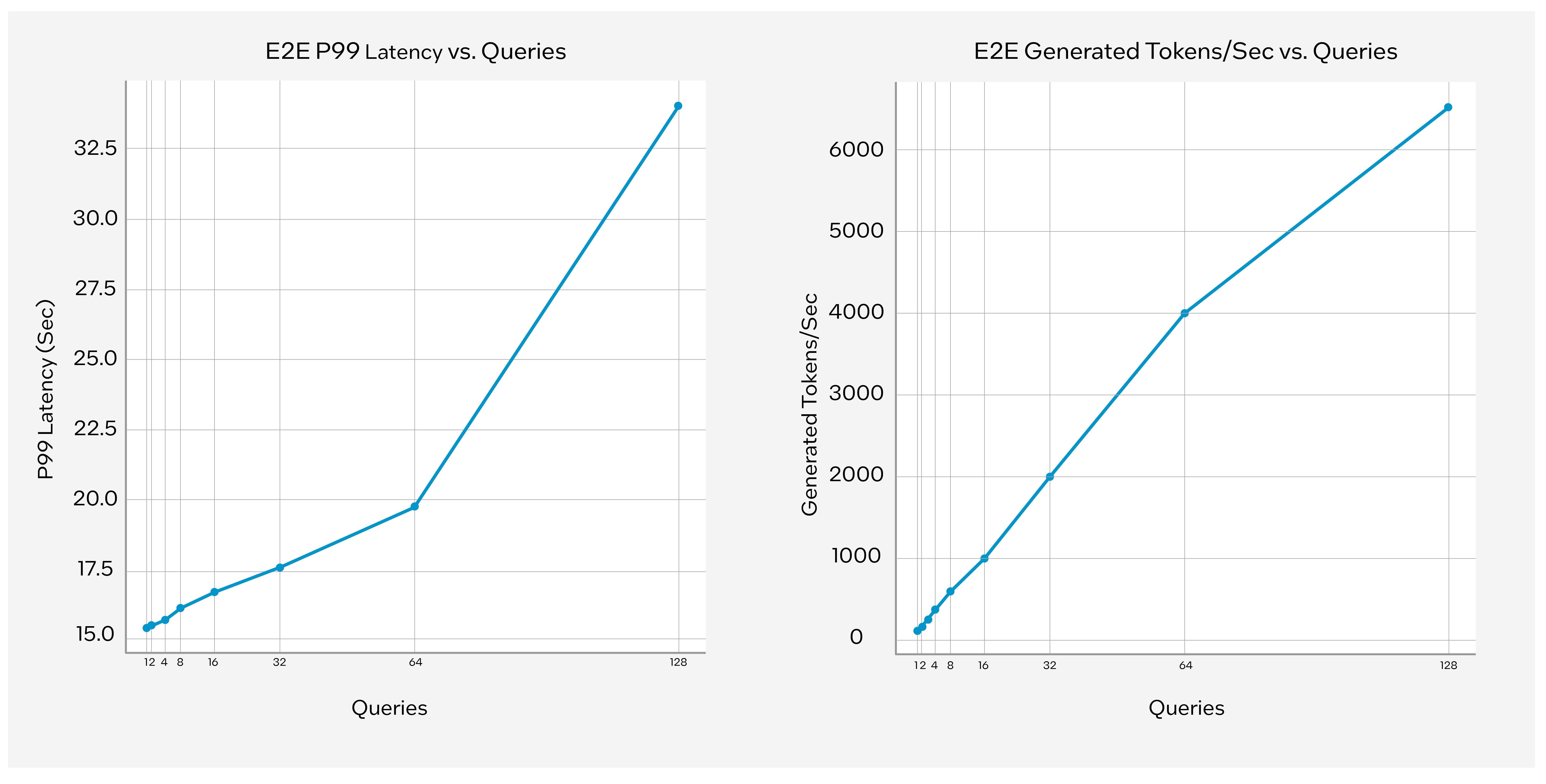
See below for detailed performance data including P99 end-to-end latency and Generated tokens/sec on 128 query tokens for embedding, and 1024 input tokens and 1024 output tokens for LLMs by running an OPEA-based Enterprise RAG reference solution on a Xeon system with 8 Gaudi 2 cards given the number of concurrent queries.
List of resources for trying out Meta Llama 3.1 today with Intel AI solutions.
- Intel Gaudi Examples
- PyTorch: Get Started on Intel Xeon and AI PCs
- OpenVINO Jupyter notebook for chatbot on AI PC or Xeon
- OPEA RAG Example
In conclusion, the Intel AI PC and data center AI product portfolio and solutions can run Llama 3.1 today, and OPEA is fully enabled on the Intel Gaudi 2 and Xeon product lines with Llama 3.1. Intel continues to make software optimizations to enable new models and use cases.
Product and Performance Information
Intel Gaudi 2: HLS-Gaudi2 with eight Habana Gaudi2 HL-225H Mezzanine cards. 2 socket Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz. 1TB System Memory. OS: Ubuntu 22.04. PyTorch v2.2.2. Docker images: vault.habana.ai/gaudi-docker/1.16.2/ubuntu22.04/habanalabs/pytorch-installer-2.2.2. SynapseAI version 1.16.2. Optimum Habana: v1.12.1. Repository here.
Intel Xeon Processor: Measurement on 5th Gen Intel® Xeon® Scalable processor using: 2x Intel® Xeon® Platinum 8593Q, 64cores, HT On, Turbo On, NUMA 4, 512GB (16x32GB DDR5 5600 MT/s [5600 MT/s]), BIOS 3B07.TEL2P1, microcode 0x21000200, Samsung SSD 970 EVO Plus 2TB, CentOS Stream 9, 5.14.0-437.el9.x86_64, Models run with PyTorch and IPEX 2.4. Test by Intel on July 22, 2024. Repository here.
Intel® Core™ Ultra: Measurement on a Microsoft Surface Laptop 6 with Intel Core Ultra 7 165H platform using 32GB LPDDR5 7467Mhz total memory, Intel graphics driver 101.5762, IPEX-LLM 2.1.0b20240718, Windows* 11 Pro version 22631.3593, Performance power policy, and core isolation enabled. Intel® Arc™ graphics only available on select H-series Intel® Core™ Ultra processor-powered systems with at least 16GB of system memory in a dual-channel configuration. OEM enablement required, check with OEM or retailer for system configuration details. Test by Intel on July 18th, 2024. Repository here.
Intel® Arc™ A-Series Graphics: Measurement on Intel Arc A770 16GB Limited Edition graphics using Intel Core i9-14900K, ASUS ROG MAXIMUS Z790 HERO motherboard, 32GB (2x 16GB) DDR5 5600Mhz and Corsair MP600 Pro XT 4TB NVMe SSD. Software configurations include Intel graphics driver 101.5762, IPEX-LLM 2.1.0b20240718, Windows 11 Pro version 22631.3593, Performance power policy, and core isolation disabled. Test by Intel on July 18th, 2024. Repository here.
OPEA is measured with Gaudi 2: 1-node, HLS-Gaudi2 with 8x Gaudi® 2 HL-225H and Intel® Xeon® Platinum ICX 8380 CPU @ 2.30GHz 2 sockets 160 cores, Total Memory 1TB, 32x32GB DDR4 3200 MT/s [3200 MT/s], Ubuntu 22.04.4 LTS, Kernel 5.15.0, Test by Intel as of 07/16/24. Software: Meta-Llama-3.1-8B is deployed to 7 cards, Meta-Llama-Guard-3-8B is deployed to 1 card. BF16 for Gaudi2. Embedding model is BAAI/bge-base v1.5. Tested with: TGI-gaudi 2.0.1, TEI version: 1.2.0, Gaudi driver version: 1.16.1, Docker version 27.0.3, Kubernetes version v1.29.5, RAG queries max input length 1024, max output length 128. Test dataset: Langchain doc Q&A. Number of concurrent clients 128; TGI parameters for Gaudi2 (8B): batch_bucket_size=22, prefill_batch_bucket_size=4 , max_batch_prefill_tokens=5102, max_batch_total_tokens=32256, max_waiting_tokens=5, streaming=true; The accuracy of the queries was not validated. Query parameters: Temperature=0.01, Top-K=10, Top_p=0.95.a. Repository here.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
AI disclaimer:
AI features may require software purchase, subscription or enablement by a software or platform provider, or may have specific configuration or compatibility requirements. Details at www.intel.com/AIPC. Results may vary.