Get Performance Gains without Code Changes
Dr. Amarpal Singh Kapoor, technical consulting engineer, Intel Corporation
Marat Shamshetdinov, software development engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Procuring an HPC cluster demands careful performance and economic considerations. But it doesn’t stop there. Operating an HPC cluster efficiently is equally important for environmental and economic reasons—and it’s a continuous process that lasts throughout the service life of a cluster.
There are many ways to improve cluster operating efficiency, but this article limits the scope to reducing costs using the tuning utilities available in Intel® MPI Library. These utilities can help you tune your configurations to bring down the time to solution for MPI jobs on a cluster. They allow you to do cluster-wide and application-specific tuning. Plus, these utilities don’t require source code changes. They're completely driven by the Intel MPI Library.
Four tuning utilities are described:
- MPItune
- Fast Tuner
- Autotuner
- mpitune_fast
However, the focus is on Autotuner and its benefits, including:
- Recommended procedures for automatic tuning
- A methodology to select candidate applications using Application Performance Snapshot (APS), a part of Intel® VTune™ Profiler
- Resulting performance improvements for the Intel® MPI Benchmarks
Version Details
This article focuses on two Intel® software tools:
- Intel MPI Library
- Intel VTune Profiler
Both of these tools are available as part of Intel® Parallel Studio XE and Intel® oneAPI Toolkits (Table 1).
Table 1. Packaging details for the tools covered in this article
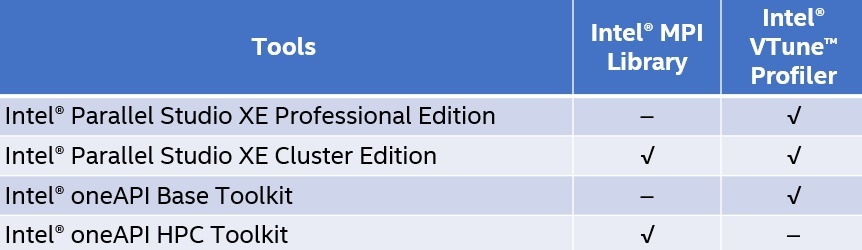
For this article, we used the Intel® oneAPI Base Toolkit and Intel® oneAPI HPC Toolkit. The tuning utilities of interest here are equally valid for Intel Parallel Studio XE users. We performed all tests in the Intel® DevCloud for oneAPI, an Ethernet-based cluster running Intel® Xeon® Gold processor 6128 (dual socket, 12 cores per socket, enabled with Intel® Hyper-Threading Technology).
Tuning Utilities
The Intel MPI Library development team spends considerable effort on tuning to maintain best-in-class latencies and bandwidths while transferring messages within and across nodes. As a result, the out-of-box tuning in Intel MPI Library is generally good, but there might be corner cases that can benefit from further tuning. For example:
- Untested numbers of ranks (-n) and ranks per node (-ppn) combinations
- Message sizes that are not powers of 2
- New network topologies
- Untested interconnects
In these cases, we can perform additional tuning to get better performance. Achieving even small performance gains without code changes for the most time-consuming applications on a cluster, over its entire service life, represents significant cost savings, load reductions, and increased job throughput.
MPItune and Fast Tuner have been part of the Intel MPI Library since 2018 and earlier. MPItune has a large parameter space. It searches for optimal values of many variables, such as:
- I_MPI_ADJUST_<opname> family
- I_MPI_WAIT_MODE
- I_MPI_DYNAMIC_CONNECTION
- I_MPI_*_RADIX variables
- And others for different values of legal options, fabrics, total ranks, and ranks per node
The tuning methodology is O(n), where n is the total number of possible test configurations. As a result, this approach can get expensive. MPItune can be used both for cluster-wide tuning (by cluster administrators) and application-specific tuning (by unprivileged users).
Fast Tuner is a way to overcome the high overhead of MPItune. Based on MPItune, Fast Tuner starts off by generating an initial profile of an application to assemble a list of target MPI functions. After this, Fast Tuner never invokes the real application again. Instead, it uses IMB as a surrogate for generating a tuned configuration—bringing down the tuning overhead.
Two more tuning utilities were introduced in the 2019 versions of Intel MPI Library:
Autotuner reduces the tuning scope to the I_MPI_ADJUST_<opname> family of environment variables and limits tuning to the current configuration only (fabric, number of ranks, number of ranks per node, and more). Autotuner runs the application of interest and doesn’t have to rely on surrogate benchmarks, as in Fast Tuner. Autotuner is also capable of generating independent tuning data for different communicators of the same size in an application. A key differentiator for Autotuner is its smart selection logic, which has zero overhead. Separate tuning runs aren’t required, unlike other utilities, but may be optionally performed for even better performance in certain cases.
The last utility, mpitune_fast, lets us automatically set up the Intel MPI Library, launch it with Autotuning enabled, and configure it for cluster tuning. The tool iteratively launches IMB with the proper autotuner environment and generates a file with the tuning parameters for your cluster configuration. After generating the tuning file, you can set it as default using the I_MPI_TUNING_BIN environment variable for all applications on the cluster that use Intel MPI Library. mpitune_fast supports Slurm and IBM* Spectrum LSF workload managers. It automatically defines job-allocated hosts and performs launches. Here’s the simplest way to invoke mpitune_fast:

We can customize our tuning run using additional options, such as:

Use the -h option to see the full list of options. For example:

The rest of this article focuses on Autotuner.
Select Applications to Tune with Autotuner
This step is optional. If you already know the performance characteristics of your application, you can skip it. If not, you can use Application Performance Snapshot (APS), a low-overhead tool designed to capture high-level application metrics.
To generate an APS profile, run these commands:

Note the use of aps before the application name in the MPI run command. To collect deeper MPI metrics, set another environment variable:
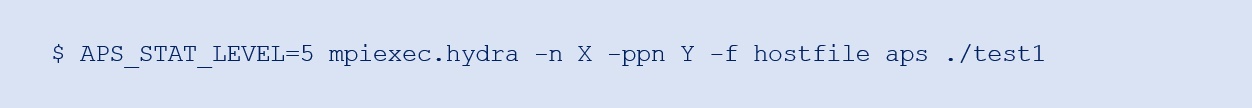
Running this command generates a result folder named aps_result_<postfix>.
The following command generates a report (in HTML format) in addition to on-screen text output:

APS reports that the application is MPI-bound, and that Allreduce is the most time-consuming MPI function (Figure 1). Since a collective communication function consumes the most time, this application is a good candidate to tune through Autotuner. Equally favorable are situations where wait operations arising from nonblocking collectives consume significant time. Autotuner doesn’t currently tune point-to-point communication.
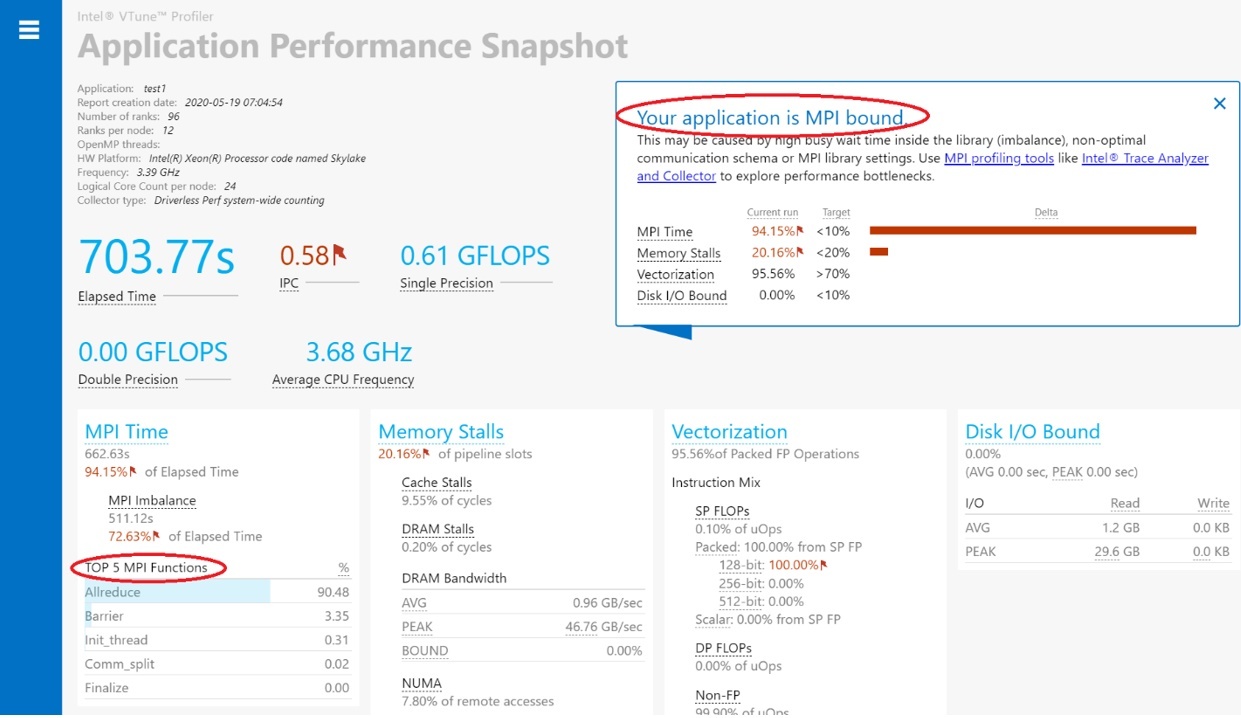
Figure 1. Report from APS
Autotuner can also perform communicator-specific tuning. Two communicators with the same size, but different rank compositions, receive separate tuning data from Autotuner. Sometimes, you might want to restrict tuning to only the most time-consuming communicators. This requires collecting communicator ID data using additional environment variables (APS_STAT_LEVEL=3 and APS_COLLECT_COMM_IDS=1) as you collect the APS profile. You can then view the communicator IDs using this command:

The number of MPI calls and message sizes are other important parameters to consider. For a given MPI operation, message size, and communicator, Autotuner needs at least as many MPI calls as the number of available implementations (for that MPI operation) to choose the best implementation. As the number of calls grows, so do the overall gains that accumulate as a function of the number of calls. You can replace the -lFE flag with -fF to print an unfiltered function summary and -mDPF to print an unfiltered message size summary. Several other flags are available for MPI parameters of interest. (For details, see the “Analysis Charts” section in the APS User Guide.)
Autotuner Steps
As we previously mentioned, no code changes are required to tune applications using Autotuner. In addition, existing binaries without special recompilation can be used, since this methodology doesn’t depend on the debug information from the compiler. Tuning an application using Autotuner involves two steps, at most.
Step 1: Generate and Use Tuning Data
This mandatory step involves both generating and using tuning data:

You can also choose to save the generated tuning data to a file (to be used for subsequent runs) by setting I_MPI_TUNING_BIN_DUMP to a user-defined filename:

Note the use of environment variables without traditional export statements. This works well in the context of an autotuning workflow, especially when you also perform the validation step.
Doing this step alone can potentially result in performance gains.
Note Apart from generating the tuning data, tuning data is also consumed in this step.
Step 2: Validate Tuning Data
You can perform this optional step to increase the performance gains from Step 1 by using the tuning file generated in Step 1: I_MPI_TUNING_BIN.

Having I_MPI_TUNING_MODE=auto:cluster enabled in Step 2 results in additional overhead. This can accidentally happen if you're using export statements, which is why this article earlier recommended not using export statements. To further control the Autotuner control logic, you can use additional knobs through the I_MPI_TUNING_AUTO_* family of environment variables.
Demonstrating Performance Gains
This section extends the methodology in the previous section to IMB and show the speedups we achieved.
Baseline

Here the number of repetitions for all message sizes has been set to 1,000 using the -iter 1000 and -iter_policy off flags. The latter disables the default iteration policy, which restricts the number of repetitions for larger message sizes. The -npmin 96 flag restricts the number of MPI ranks to 96. (By default, IMB-MPI1 reaches the specified number of ranks in power-of-two increments, which wasn’t desirable in this context.) Setting -time 100000 tells IMB-MPI1 to wait for 100,000 seconds per sample before timing out.
Step 1

Step 2

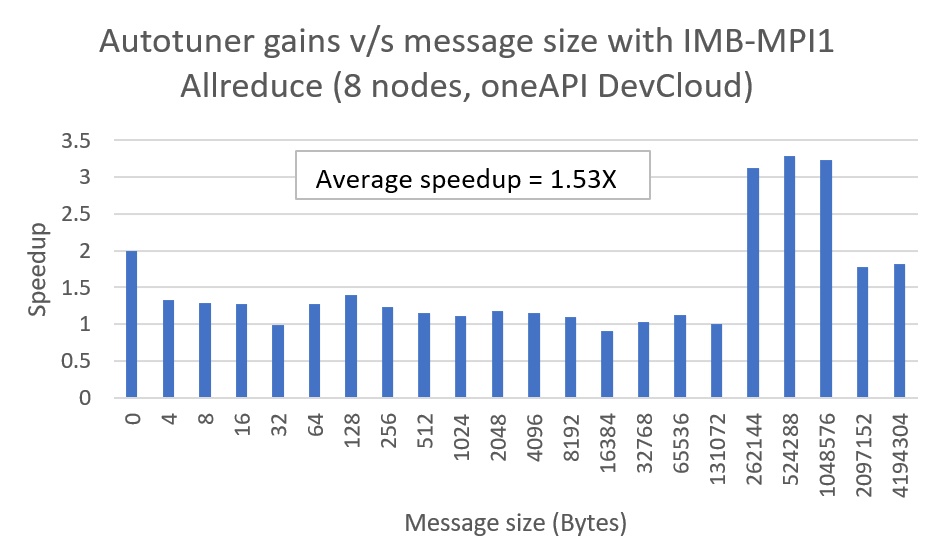
Figure 2. Autotuner gains for Allreduce
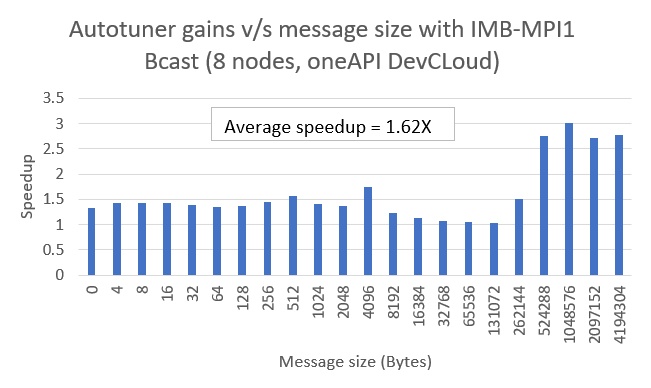
Figure 3. Autotuner gains for Bcast
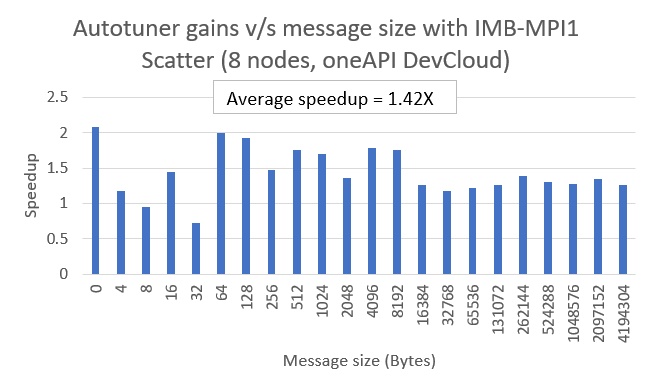
Figure 4. Autotuner gains for Scatter
As shown in Figures 2 through 4, there are significant performance speedups for most message sizes. The average speedup in the 0 MB to 4 MB message size range for Allreduce, Bcast, and Scatter are 1.53x, 1.62x, and 1.42x, respectively. The speedup calculations were based on IMB’s average time (t_avg) metrics for baseline and Step 2.
Figure 5 demonstrates Autotuner gains for Allreduce at different node counts (1 to 16). The gains are sustainable, with an average speedup of 1.34x for the 0 MB to 4 MB message size range. In general, we expect the Autotuner gains to increase at larger node counts.

Figure 5. Autotuner gains as a function of number of nodes
Conclusion
This article introduced the four tuning utilities available in the Intel MPI Library. Table 2 presents a qualitative summary of these utilities for five factors. The green, mustard, and red colors indicate positive, neutral, and negative sentiments, respectively.
Table 2. Tuning utilities in Intel MPI Library and their capabilities
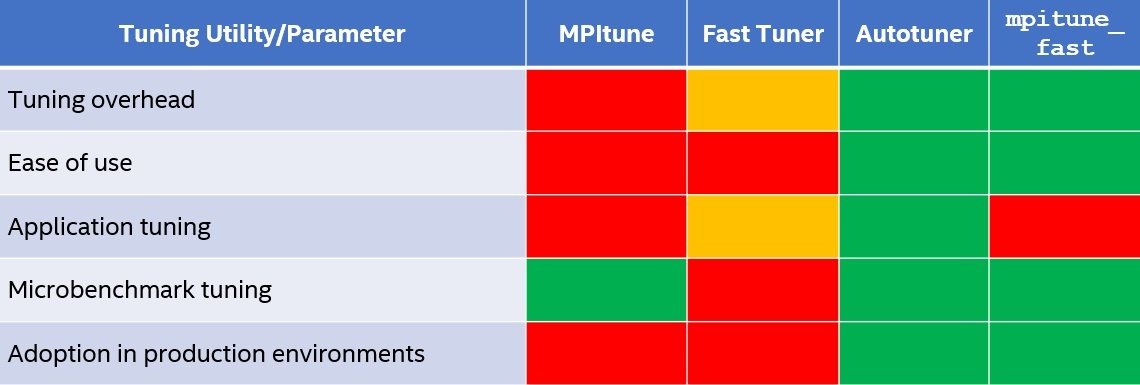
While mpitune_fast serves as a good first step for cluster-wide tuning, we can then use Autotuner for application-level tuning. It’s important to characterize applications of interest to understand if an application benefits from Autotuner. APS serves this function. We expect applications spending a significant portion of their time in collective operations (both blocking and non-blocking) to benefit the most.
______
You May Also Like
| Intel® oneAPI Base Toolkit Get started with this core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures. Get It Now See All Tools |