About Ginkgo
Ginkgo is a high-performance C++ framework for sparse linear algebra on manycore systems. It is implemented using modern C++ (the Intel® C++ Compiler used must be at least C++14 compliant), with GPU kernels implemented in CUDA*, heterogeneous interface for portability (HIP), and oneAPI-compliant Data Parallel C++ with SYCL*. Ginkgo was developed by the Karlsruhe Institute of Technology (KIT), the University of Tennessee, and Universitat Jaume I. It is an open source and community-driven project under the modified BSD (Berkeley Software Distribution) license.

Figure 1. Architecture-optimized kernels
Using a universal linear operator abstraction, Ginkgo provides basic building blocks like the sparse matrix-vector product for various matrix formats, iterative solvers, preconditioners, and batched routines. Ginkgo targets multi- and many-core systems and currently features back ends for AMD* GPUs, Intel GPUs, NVIDIA* GPUs, and OpenMP* supporting architectures. The core functionality is separated from hardware-specific kernels for smooth extension to other architectures, with runtime polymorphism selecting the specific kernels. See figure 2 for details on what is available within the Ginkgo framework.
Scientists in many different research domains are eager to run their workloads on the new Intel® architectures, particularly Intel® Iris® Xe graphics and Intel® Data Center GPU Max Series. However, they lack the math libraries they can rely on to run on these devices. Porting Ginkgo's linear algebra functionality to the SYCL ecosystem allows them to rely on Ginkgo when running their scientific simulations on Intel Iris Xe graphics devices.
In this article, we detail:
- How we ported Ginkgo to the Intel and SYCL ecosystems and why it is important
- How we bring the best performance possible to these scientific applications on Intel hardware
- How we can accelerate the OPENFOAM* simulation framework by relying on Ginkgo as a linear solver

Figure 2. Ginkgo feature list
Port Ginkgo to the oneAPI and SYCL Ecosystems
Ginkgo is the first platform-portable open source math library supporting Intel GPUs via oneAPI's open SYCL back end. Domain scientists from different areas rely on Ginkgo and its sparse linear algebra functionality, which forms the base building blocks for many scientific simulations. Existing implementations supported CUDA, HIP, and openMP. Extending Ginkgo platform portability to Intel GPUs using oneAPI enables applications based on Ginkgo to be vendor agnostic, demonstrating cross-platform performance on various hardware and programming models. Watch the video implementing a heat equation simulation in the Intel® Developer Cloud.
"Adding the Intel SYCL back end to the Ginkgo library gives domain scientists a high-performance math library for running workloads on the Intel GPUs."
Why Does It Matter?
Ginkgo is a high-performance linear algebra library for manycore systems, focusing on solving sparse linear systems. It uses modern C++ for a sustainable, flexible, composable, and portable software package. Ginkgo aims to provide domain scientists with high-performance math functionality to enable fast and better science. This is achieved by developing novel algorithms suitable for modern hardware technology and optimizing kernels for specific applications and architectures. With Intel® Max Series products entering the market, we must provide production-ready, high-performance math functionality in Ginkgo to enable domain scientists to run their workloads on architectures based on the Intel Max Series products.
By porting Ginkgo to oneAPI and supporting the Intel Data Center GPU Max Series dedicated to high-performance computing (HPC), we can provide high-performance building blocks to simulation frameworks that support Ginkgo, such as deal.II, MFEM, OPENFOAM, HYTEG, SUNDIALS, Extended Code Guardrails (XCG), HiOp, and openCARP scientific applications, ranging from finite element libraries to computational fluid dynamics, power grid optimization, and heart simulations.
Increase Platform Portability of Ginkgo
Ginkgo supports running on CUDA, HIP, SYCL accelerators, and OpenMP-enabled CPU devices, so it is mostly GPU-centric. Platform and performance portability are Ginkgo's critical features. This means that Ginkgo is expected to provide optimal results on various architectures from different vendors.
KIT collaborated with Intel to migrate core functionality from CUDA to SYCL and deliver optimized kernels using the Intel® DPC++ Compatibility Tool and the Intel® oneAPI DPC++/C++ Compiler.
Intel Developer Cloud initially enabled the Ginkgo team with Intel hardware. It contains a unified preconfigured development environment that helps developers concentrate their efforts on the development tasks. With restricted access permissions, even early access to the latest hardware can be granted. Later, Ginkgo ran continuous integration tests on a laptop with Intel Iris Xe graphics before upgrading to the Intel® Arc™ A770 graphics.
A Closer Look into Migration
We started porting Ginkgo to SYCL in 2020 during the emergence of the oneAPI specification and initiative. Beginning with these early stages and the use of early access to beta versions of oneAPI, we have seen many significant improvements using the Intel® DPC++ Compatibility Tool and the Intel® oneAPI DPC++/C++ Compiler.
Ginkgo was originally designed as a GPU-centric sparse linear algebra library using the CUDA programming language and CUDA design patterns for implementing GPU kernels. The Ginkgo HIP back end for targeting AMD GPUs was introduced in early 2020. Migration from CUDA to SYCL started in 2020 as well. The 1.4.0 minor release (August 2021) brought most of the Ginkgo functionality to the oneAPI ecosystem, enabling Intel GPU and CPU running, excluding preconditioners. Full Data Parallel C++ and SYCL support is available starting with Release 1.5.0.
KIT developed a detailed migration pipeline to mitigate the complexity of migrating highly templated code, cooperative groups, and atomics. It was a semi-manual process, so kernels were automatically migrated, and after some improvements to unified shared memory (USM) data handling and kernel submissions, The bulk of work focused on performance tuning and adding advanced features.
Learn more about the challenges KIT faced porting Ginkgo from CUDA to SYCL in the video from the oneAPI DevSummit at IWOCL 2022.
Optimize Ginkgo Functionality on Intel GPUs to Accelerate Numerical Simulations
Numerical simulations relying on sparse linear algebra are always constructed from the same building blocks, which are highly composable and configurable to adapt to a specific problem. This article highlights two essential building blocks of sparse iterative linear solvers. The first building block is the Sparse-Matrix Vector (SpMV) product, the most common and critical operation within sparse iterative solvers and several preconditioners. The second building block is problem-specific, advanced preconditioners, which accelerate the convergence rate of the sparse iterative solvers.
No Transistor Left Behind: Performance Boost Using Intel GPUs for Fast SpMV Products
As the base building block of numerical linear algebra, having fast SpMV products is essential to accelerating a complete numerical simulation. One optimization is applied by combining multiple kernels, which are automatically selected depending on the properties of the sparse matrix at hand. A consideration for combining multiple kernels is, for instance, how imbalanced or balanced the matrices are.
Ginkgo's design allows the implementation of different SpMV kernels depending on the back end. This allows for a highly flexible and adaptable approach to achieving each hardware's best possible performance. Ginkgo also carefully tunes the key thresholds at which the SpMV strategy should be changed on a per–back end and hardware basis. Thanks to these optimizations, Ginkgo's SpMV performance is consistently high on Intel Data Center GPU Max Series 1550 on one tile.
On average, Ginkgo's SpMV outperforms the Intel® oneAPI Math Kernel Library (oneMKL) compressed sparse row format (CSR) matrix-vector implementation by a factor of 2.
For problems from the SuiteSparse Matrix Collection, this advantage can even reach 100x, as seen in the following graphics.

Figure 3. Speedup of Ginkgo's CSR against oneMKL CSR SpMV for problems from the SuiteSparse matrix collection
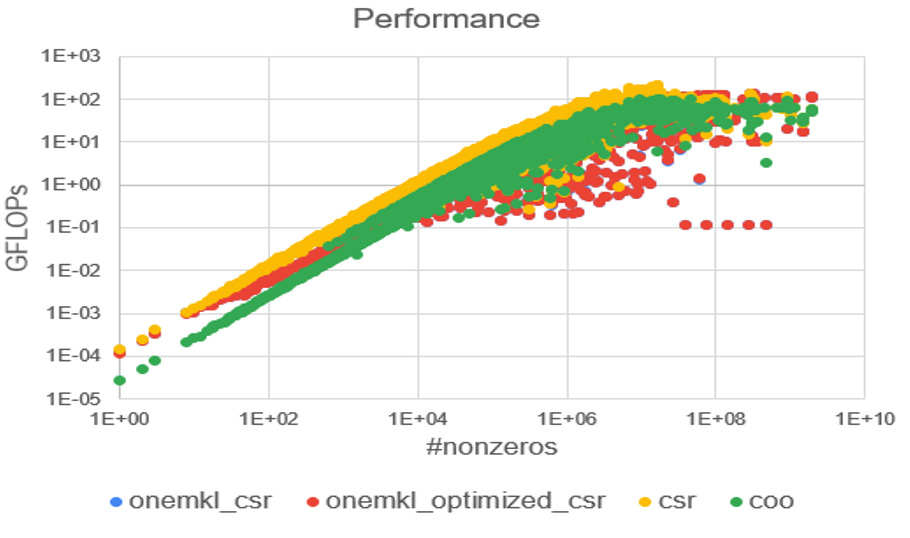
Figure 4. Ginkgo's COO and CSR against oneMKL CSR SpMV performance for problems from the SuiteSparse matrix collection

Figure 5. Ginkgo's batched kernel performance on Intel Data Center GPU Max Series 1550 against NVIDIA A100 and H100 for PeleLM thermal combustion matrix cases
Batched Iterative Solvers for Selected Applications
Ginkgo development and GPU porting did not stop at version 1.5.0. Batched iterative solvers have recently received a lot of attention because of their efficiency in solving batches of small and medium-sized sparse problems. In particular, it has been shown that batched iterative methods can outperform state-of-the-art batched direct counterparts for GPUs.
Batched iterative methods' functionality is critical in applications such as combustion and fusion plasma simulations. These applications commonly need to solve hundreds of thousands of small to medium linear systems, each sharing a sparsity pattern. For the linear solution of these types of systems with nested nonlinear loops, it is advantageous to use an iterative solver, as that allows the incorporation of an initial guess, which can accelerate the linear system solution within the outer loop. Additionally, we may not need to solve the system to precision accuracy but can control the solution accuracy based on the parameters of the outer nonlinear loop.
By porting Ginkgo's batched iterative solvers to SYCL and Intel GPUs, we enable these applications to take advantage of the high performance of the Intel Data Center GPU Max Series 1550. See the data in figures 6 and 7, which show speedups with Intel Data Center GPU Max Series 1550 1s on use cases from the PeleLM combustion simulation framework. Except for the gri12 case, all other input cases show a notable performance increase of the solvers on the latest Intel GPUs compared to NVIDIA GPUs. On average, the workload runs 1.7x and 1.3x faster on Intel Data Center GPU Max Series 1550 1s compared to NVIDIA A100 and H100, respectively, across all input cases. Similarly, the Intel Data Center GPU Max Series 2s outperforms the A100 and H100 by an average factor of 3.1 and 2.4, respectively.
For more information, see the following paper on arXiv*: Porting Batched Iterative Solvers onto Intel GPUs with SYCL.
Use Mixed-Precision Algorithms for Extra Performance Increases
To further optimize the preconditioners available in Ginkgo, we use mixed-precision strategies when appropriate, which consist of doing parts of the computation in float or half precision while keeping critical computations in double precision to sustain a high accuracy. The Algebraic Multigrid (AMG) algorithm is a natural approach for such a use case by performing the coarser computations within the multigrid (MG method) cycle at a lower precision. Thanks to this strategy, an extra 12% performance can be obtained when using multigrid with the W-cycle at no cost in accuracy.
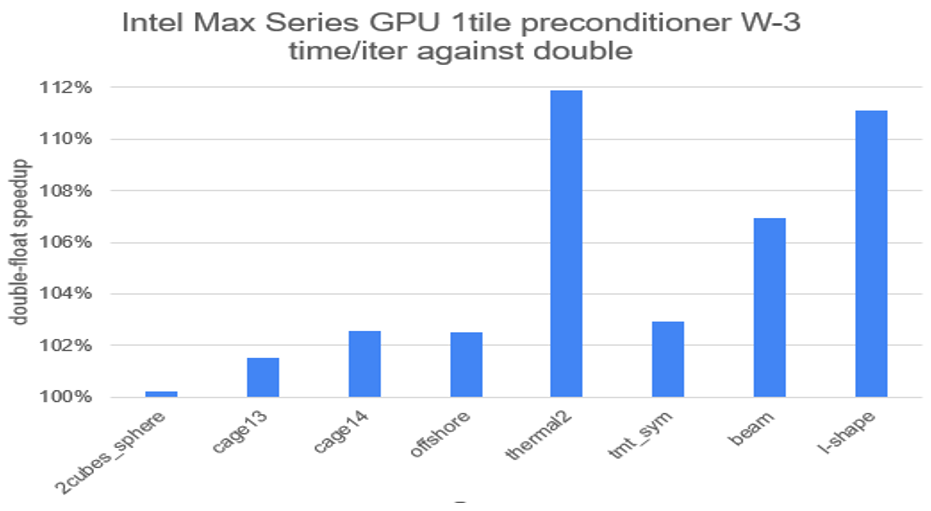
Figure 6. Ginkgo speedup when solving selected problems from the SuiteSparse matrix collection using a mixed-precision algebraic multigrid against non-mixed-precision with a W-3 cycle
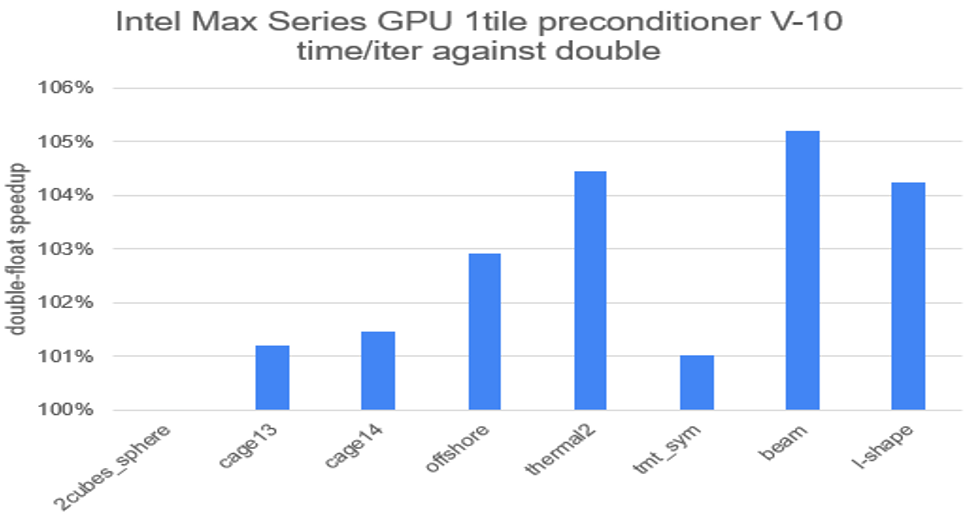
Figure 7. Ginkgo speedup when solving selected problems from the SuiteSparse matrix collection using a mixed-precision algebraic multigrid against non-mixed-precision with a V-10 cycle
Scalability on HPC clusters
The ability to use a full HPC cluster efficiently is critical for most scientific simulations. Ginkgo has developed a distributed back end by relying on MPI. The current MPI implementation is merely an extension of Ginkgo and requires very little change for users compared to running their workload on a single GPU. Using Ginkgo's distributed back end is done by wrapping the matrices and vectors into new distributed::Matrix and distributed::Vector types that allow the user to specify the data distribution onto the nodes. In figure 8, we show Ginkgo SpMV's weak scalability performance on the Sunspot early access platform on up to 1000 tiles (500 GPUs), where we can reach up to approximately 70 TFlop/s.
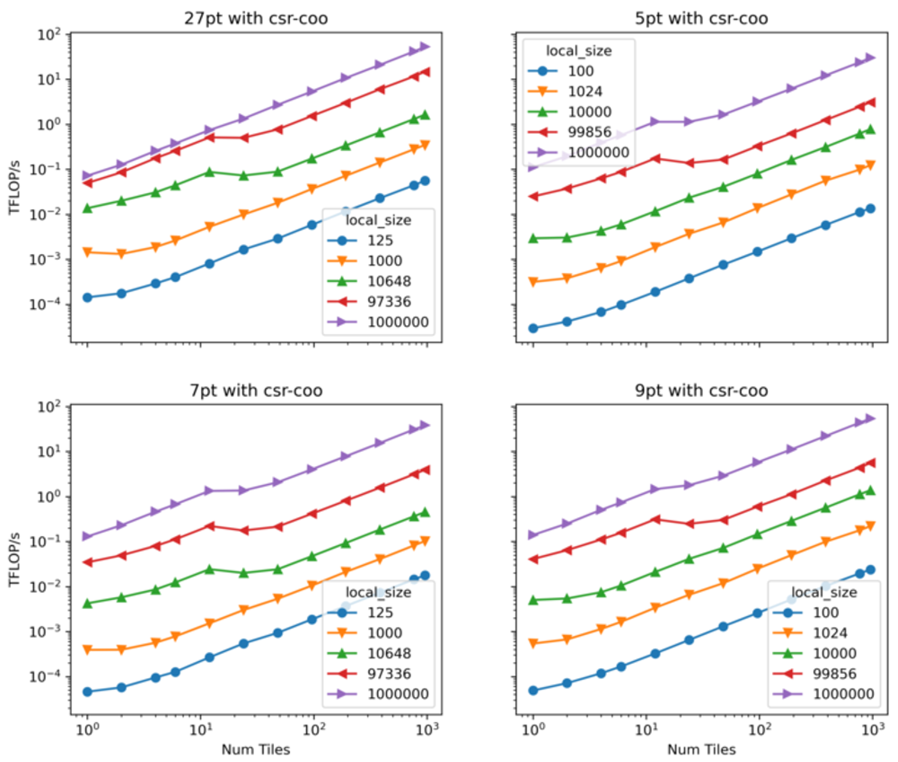
Figure 8. Scalability of the Ginkgo distributed SpMV on up to 1000 tiles (500 Intel Data Center GPU Max Series 1550)
Use Case Example: Accelerate OPENFOAM* Simulations on Intel GPUs
High-fidelity (scale-resolving) flow simulations have become an important part of academic research and an indispensable tool for development processes in the wind energy industry, the automotive sector, aerospace engineering, and political decision-makers in environmental and disaster protection. However, many state-of-the-art software libraries are insufficiently prepared for modern, more energy-efficient high-performance computers employing general-purpose GPU accelerators. In the EXASIM project, we close this technical gap by developing an interface between the popular simulation software OPENFOAM and the GPU-optimized linear algebra library Ginkgo.

Figure 9. Windsor body microbenchmark scaling test. Image: Upstream CFD GmbH, 2023
While the project is still in its infancy and more performance gains can be expected in the future, by using several of the building blocks previously highlighted, the existing OPENFOAM-Ginkgo integration already allows OPENFOAM to run on Intel GPUs with performance speedup when comparing the Intel Data Center GPU Max Series 1550 with Intel CPUs.
We report in the following figures the complete timing for an OPENFOAM simulation on the test case LidDrivenCavity3D of size 300^3. The code can run on Intel GPUs thanks to using Ginkgo's solvers, distributed back end, and benefiting from the optimizations previously highlighted.
One Intel Data Center GPU Max Series on this test case performed roughly at the same level as a full CPU (4th generation Intel® Xeon® Scalable processor with 54 cores). The CPU's high bandwidth memory provides significant time savings on data transfers between the CPU and GPU. Thus, Ginkgo can efficiently use all six GPUs available on one node (12 tiles). This allows for a total performance speedup of 5x compared to using the 4th generation Intel Xeon Scalable processor by itself.

Figure 10. OPENFOAM speedup on a formerly code named Sapphire Rapids CPU when increasing the core count, on the LidDrivenCavity test case
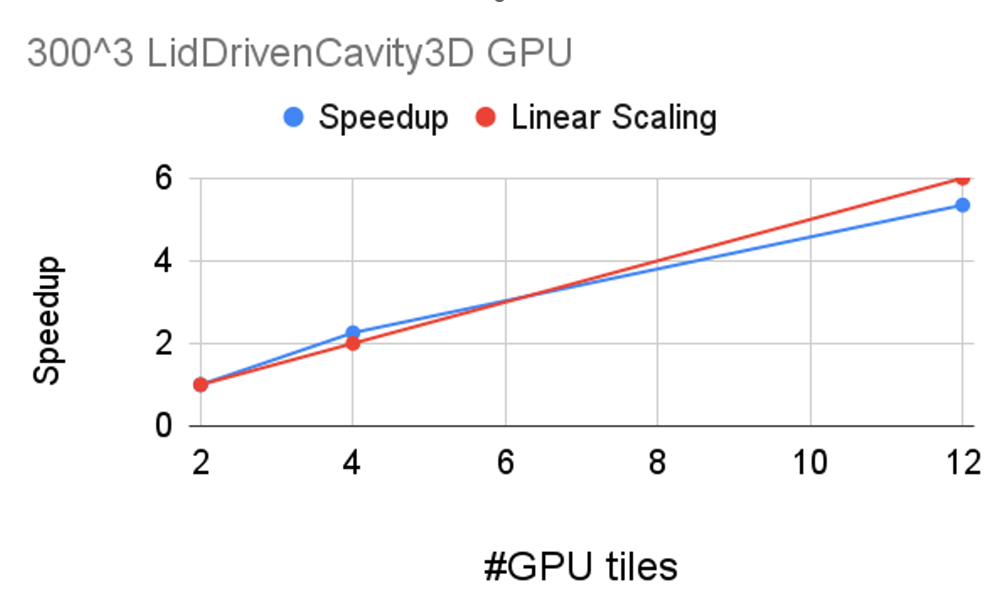
Figure 11. OPENFOAM speedup with a Ginkgo back end on multiple Intel Max Series GPU 1550 (up to six) compared to one GPU
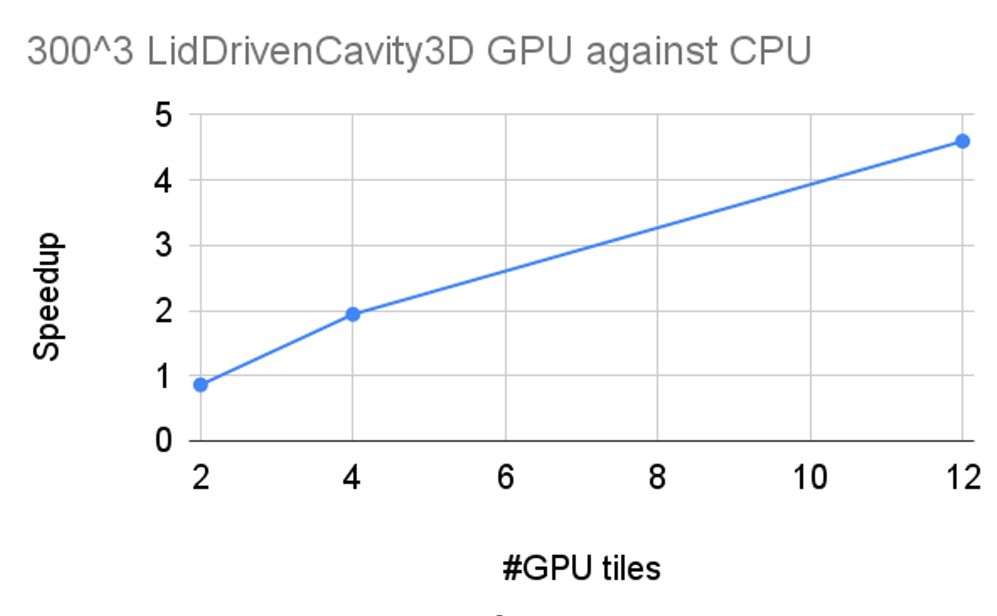
Figure 12. OPENFOAM speedup when using multiple Intel Max Series GPU 1550 against Intel® Xeon® CPU Max Series (formerly code named Sapphire Rapids) on the LidDrivenCavity
Conclusion
The functional port of Ginkgo from CUDA to SYCL-enabled devices is a first step towards high-performance simulations on Intel Iris Xe graphics and Intel Data Center GPU Max Series. We have shown multiple performance improvements on key building blocks of scientific numerical simulations. In particular, we show how, by using the Intel Data Center GPU Max Series 1550 for batched sparse iterative solvers, we can outperform the NVIDIA A100 and H100 GPUs by an average factor of 3.1 and 2.4, respectively. We have also shown how using Ginkgo's optimizations by using Ginkgo as a back end to OPENFOAM runs with good performance and scalability on a node of six Intel Data Center GPU Max Series 1550 devices.
We will continue the kernel optimization and continue supporting integrating Ginkgo's SYCL-enabled functionality into complex algorithms and application code. Ginkgo demonstrates that platform portability can be achieved without loss of performance, which opens opportunities for running scientific simulations at exascale on the latest supercomputer installations.
Performance Benchmarks
10% to up to 25% rendering efficiency and thousands of hours saved in rendering production time, and 15 hours per frame per shot to 12-13 hours.
Cinesite Configuration: 18-core Intel Xeon Scalable processors (W-2295) used in a render farm, 2nd generation Intel® Xeon® processor-based workstations (W-2135 and -2195) used. Rendering tools: Gaffer, Autodesk* Arnold, along with optimizations by Intel® Open Image Denoise.