This article was originally published on VentureBeat.
Generative AI is the ability of AI to generate novel outputs including text, images, and computer programs when provided with a text prompt. It unlocks new forms of creativity and expression by using deep learning techniques such as diffusion models and Generative Pretrained Transformers (GPT). Examples of generative AI applications are OpenAI’s ChatGPT* and DALL-E, Google* Bard, Stable Diffusion*, GPT-J, BLOOM language model, and many others.
Unlocking the availability of and access to generative AI technologies has great societal value. While discussions abound on whether generative AI models will replace or complement human ingenuity for professionals ranging from programmers to artists, we definitely want to not have such critical technologies being the domain of the few. This is particularly relevant as AI models continue to explode in size, and voracity for data and compute necessity.
Ubiquitous hardware and open software are the keys to democratizing AI. Large AI models have typically required specialized hardware acceleration through GPUs and purpose-built AI processors. However, the types of matrix multiplication acceleration engines that drive higher AI performance in these processors have now also been integrated into CPUs—the processors ubiquitous across almost every computing medium—to help them achieve GPU-level AI performance. Complementing the hardware is open software that can deliver a unified experience across architectures. Using industry-standard, open source libraries and frameworks provide several advantages for software development, particularly in the case of AI due to the rapid pace of technological advancement and the greater inherent concerns with privacy and ethics. AI systems can be thought of as an "AI brain" with the hardware and software being the biological neurons and the mind respectively.
This article delves deeper into this concept of the "AI brain" and how its potential can be maximized. It also demonstrates the value of open software and ubiquitous hardware by showcasing open-access versions of diffusion (Stable Diffusion) and GPT (GPT-J, BLOOM) models running on Intel® AI software and hardware. The 4th generation Intel® Xeon® Scalable processors with native AI hardware acceleration coupled with the AI software acceleration that Intel has contributed to industry-standard frameworks such as TensorFlow* and PyTorch* provide an excellent platform for inference and fine-tuning of large generative AI models. While the specific examples in this article are from generative AI, the ideas of open tools, universal platforms, and the role of AI software and hardware optimizations can be more generally applied.
Open Generative AI: GPT-J and Stable Diffusion* (with a Demo)
Generative AI models attempt to capture the distribution or characteristics of a particular dataset, and can be used to generate new data samples, for example, a sentence or an image. Open-access generative AI models such as GPT-J-6B and Stable Diffusion are deep learning models based on neural networks. A common building block in both of these models is the transformer, which has been shown to be very effective for applications from machine translation to document generation. Transformer models, first developed by Google researchers, are now the dominant model type for language and sequence tasks and are also rapidly expanding to recommendation systems and vision tasks. A transformer model tracks relationships across data inputs to extract context using an algorithm known as attention. A GPT allows unsupervised training from a large corpus of unlabeled data, overcoming the lack of labeled data for machine learning training.
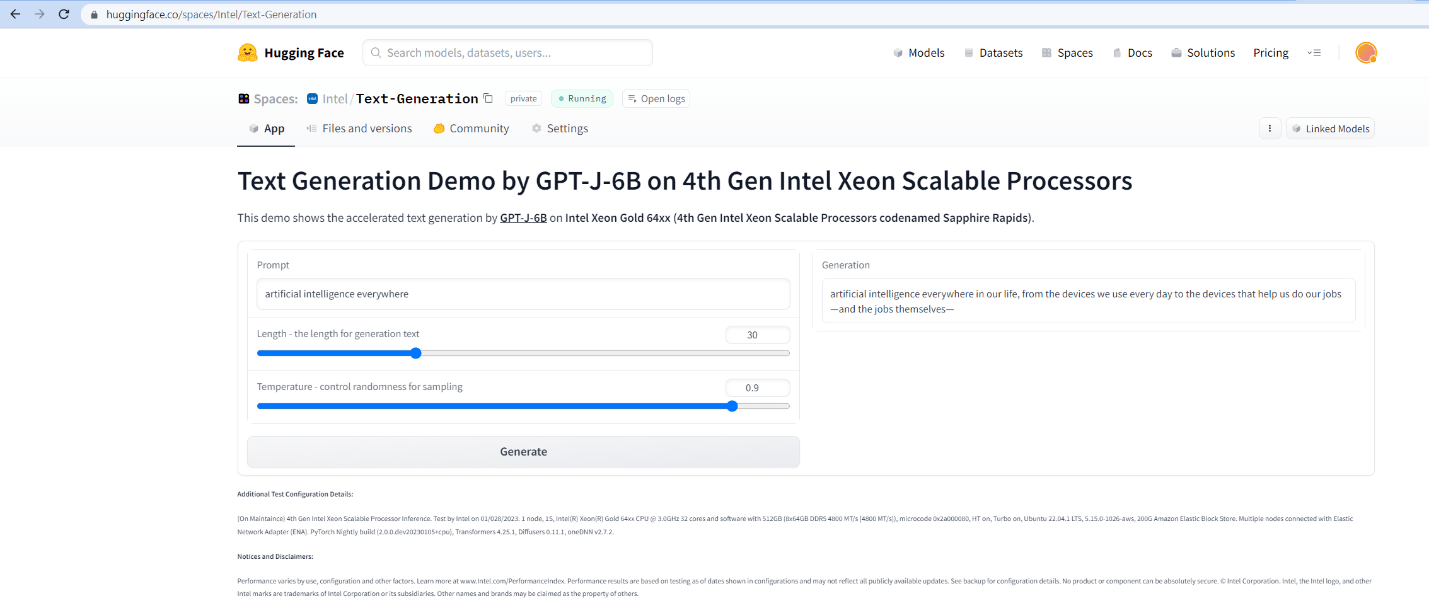
GPT-J-6B is an autoregressive deep learning language model and an open alternative to GPT-3 (ChatGPT is a variant of the GPT-3 model specifically designed for chatbot applications). It takes a text prompt and generates text automatically. When we input a prompt artificial intelligence everywhere to GPT-J-6B, it generates interesting output such as the following:
"Artificial intelligence everywhere in our life, from the devices we use every day to the devices that help us do our jobs — and the jobs themselves."
Stable Diffusion, on the other hand, is a state-of-the-art text-to-image deep learning diffusion model and an open-access alternative to DALL-E. It takes a text prompt and generates photorealistic images automatically. When we input a prompt artificial intelligence everywhere, Stable Diffusion generated the following image:
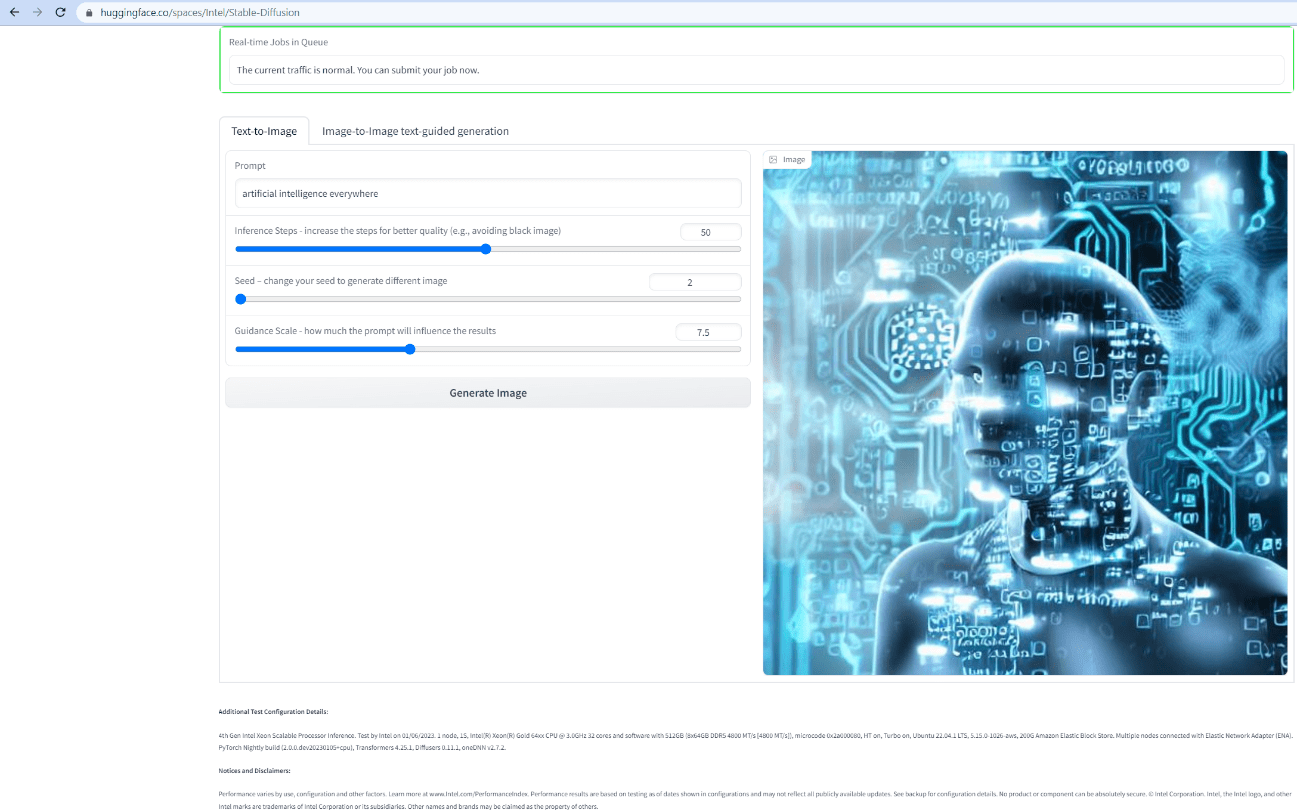
This experimental Stable Diffusion demo that runs on an Intel CPU (4th generation Intel Xeon Scalable processor) for you to try out your own prompts.
In addition to generating images from text prompts, it is also possible to personalize the model by adding your own data. For example, you can fine-tune the model by using additional image and text pairs. You can also try creating your own personalized Stable Diffusion with few-shot tuning using code available in Intel® Neural Compressor and Hugging Face* Diffusers.
The "AI Brain"
To better understand AI and how we can unlock it everywhere and for everyone, it would be good to think of AI systems as being analogous to a brain. While relatively little is known beyond the basic structure and functions of neurons and the nervous system to help us interpret the brilliance of the Einsteins and Turings of this world, we actually do know significantly more about the hardware and software that composes the "AI brain."
While the human brain consists of 86 billion neurons, the "AI brain" is a computer that consists of transistors. A 4th generation Intel Xeon Scalable processor, for example, has more than 10 billion transistors. These transistors form execution units that perform arithmetic operations like addition, subtraction, and multiplication. Just like a human brain, the CPU is designed to perform general-purpose computation. It can run operating systems and any application from surfing the web to building spreadsheets. While there are other processors such as GPUs and ASICs that are highly optimized to run certain deep learning applications, CPUs because of their adaptability, flexibility, and general-purpose capabilities form the basic building block of almost every computing system. What if we could also make this basic block highly optimized to run AI, a workload that is becoming increasingly pervasive? Complementing the processors is software AI acceleration that can deliver orders of magnitude performance gains, for the same hardware setup, across end-to-end AI pipelines from deep learning and classical machine learning to graph analytics.
Inside the AI Brain: Unlocking AI with Ubiquitous Hardware
Deep learning models are computationally intensive with most of the computation being matrix multiplication. GPUs and specialized AI processors consist of matrix multiplication units (for example: Tensor Cores in NVIDIA* GPUs and MXU matrix units in Google Tensor Processing Units* integrated circuit [TPU]) that speed up matrix multiplication and accelerate deep learning. The latest generation of CPUs now have the same type of deep learning acceleration built in.
4th generation Intel Xeon Scalable processors deliver excellent performance across all workloads with the built-in performance of an AI accelerator for end-to-end (E2E) AI pipelines. The ingestion and classical machine learning stages of the pipeline, which are critical for many AI applications, have historically performed better on the CPU because of its architectural advantages with general compute functions and irregular/sparse data. To address deep learning, Intel has integrated the Intel® Advanced Matrix Extensions (Intel® AMX) bfloat16 and int8 matrix multiplication engine into every core. The Intel AMX built-in acceleration for matrix multiplication operations is similar in functionality to GPU tensor cores and TPU MXUs and makes the latest Intel Xeon CPUs comparable to GPUs and other specialized AI accelerators for deep learning workloads. This combined with their other included features, functionalities, and effortless integration with GPUs and ASICs where available make Intel Xeon processors the ideal foundation to any universal AI platform.
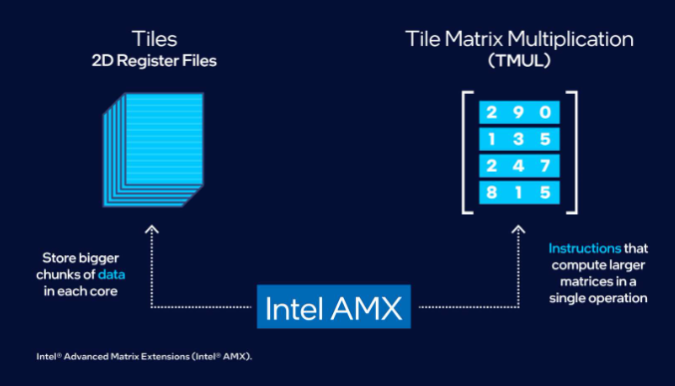
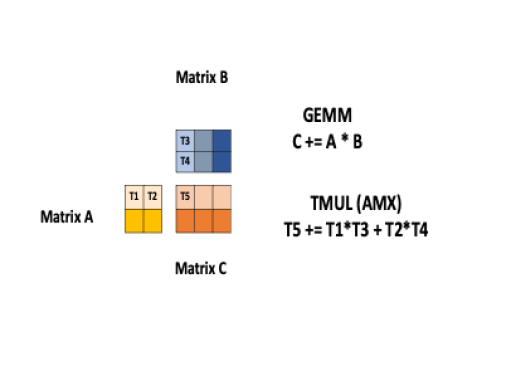
Intel AMX aims to store bigger chunks of data in each core and compute on larger matrices in a single operation, thereby accelerating compute speed. It has two primary components: tiles and tiled matrix multiplication (TMUL). The tiles store the data in eight two-dimensional registers, each one kilobyte in size. TMUL is an accelerator engine attached to the tiles that contains single operation matrix multiplication instructions. The following example shows how to implement GEMM (General Matrix Multiplication) C = C + A * B using Intel AMX. It involves breaking the matrices into tiles and performing multiplication of tiles using TMUL and tiled registers. For example, T5 is the accumulative result of T1*T3 + T2*T4.
Inside the AI Brain: Unlocking AI with Open (Accelerated) Software
The rate of AI advancement and having requirements beyond just the accuracy of AI models to also consider our ability to explain, audit, and generalize the results, lend themselves well to open-software development. Open, industry-standard frameworks also have a vast reach with millions of developers using them. Adding Intel software optimizations along with hardware acceleration like Intel AMX into the default versions of frameworks such as PyTorch and TensorFlow seamlessly benefits all of the developers who use these frameworks. Software AI acceleration in particular is critical to infusing and scaling AI into applications across entertainment, telecommunication, automotive, healthcare, and more by helping to drive 10-100X or more performance gains for the same hardware setup.

A data scientist will implement machine learning, typically in Python*, using frameworks such as PyTorch or TensorFlow. The oneAPI Deep Neural Network Library (oneDNN), one of the constituent libraries in the oneAPI unified programming model, is an open source, cross-platform, performance library of basic deep learning building blocks intended for developers of deep learning applications and frameworks. The optimizations enabled by oneDNN along with Intel AMX accelerate key performance-intensive operations such as convolution, matrix multiplication, and batch normalization. Collaborations between Intel and the framework developers allow these optimizations to be enabled by default into the stock versions of the frameworks, allowing their millions of developers to easily take advantage of Intel’s software and hardware acceleration. This includes users of GPT-J and Stable Diffusion, which are open-access models built on PyTorch, and several of the generative and other AI models that take advantage of dozens of other industry-standard open frameworks and libraries.
AI Performance on CPUs Compared to GPUs
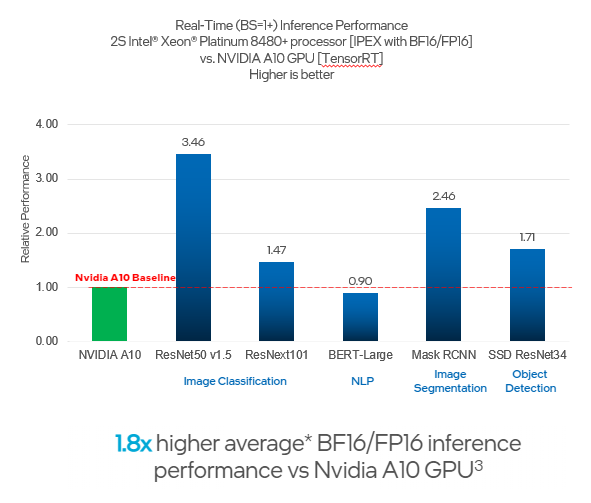
CPUs, and specifically those with built-in AI acceleration, deliver a similar level of performance to GPUs for a wide variety of AI workloads. PyTorch and TensorFlow code using the built-in Intel AMX acceleration in 4th generation Intel Xeon Scalable processors (formerly code named Sapphire Rapids) deliver up to 10x1 higher inference and training performance and up to 6.7x2 acceleration of E2E workloads when compared to the previous generation. When compared to NVIDIA A10 GPUs, Intel Xeon Scalable processors have a 1.8x3 higher average AI bfloat16/FP16 inference performance. When compared to NVIDIA A100 GPUs, training a Hugging Face BERT large language model using PyTorch on a single Intel Xeon Scalable processors node can be completed in 20 minutes versus seven minutes,4 which is longer but comparable. Additional performance and benchmark data for the 4th generation Intel Xeon Scalable processors can be found in the AI Platform Overview.
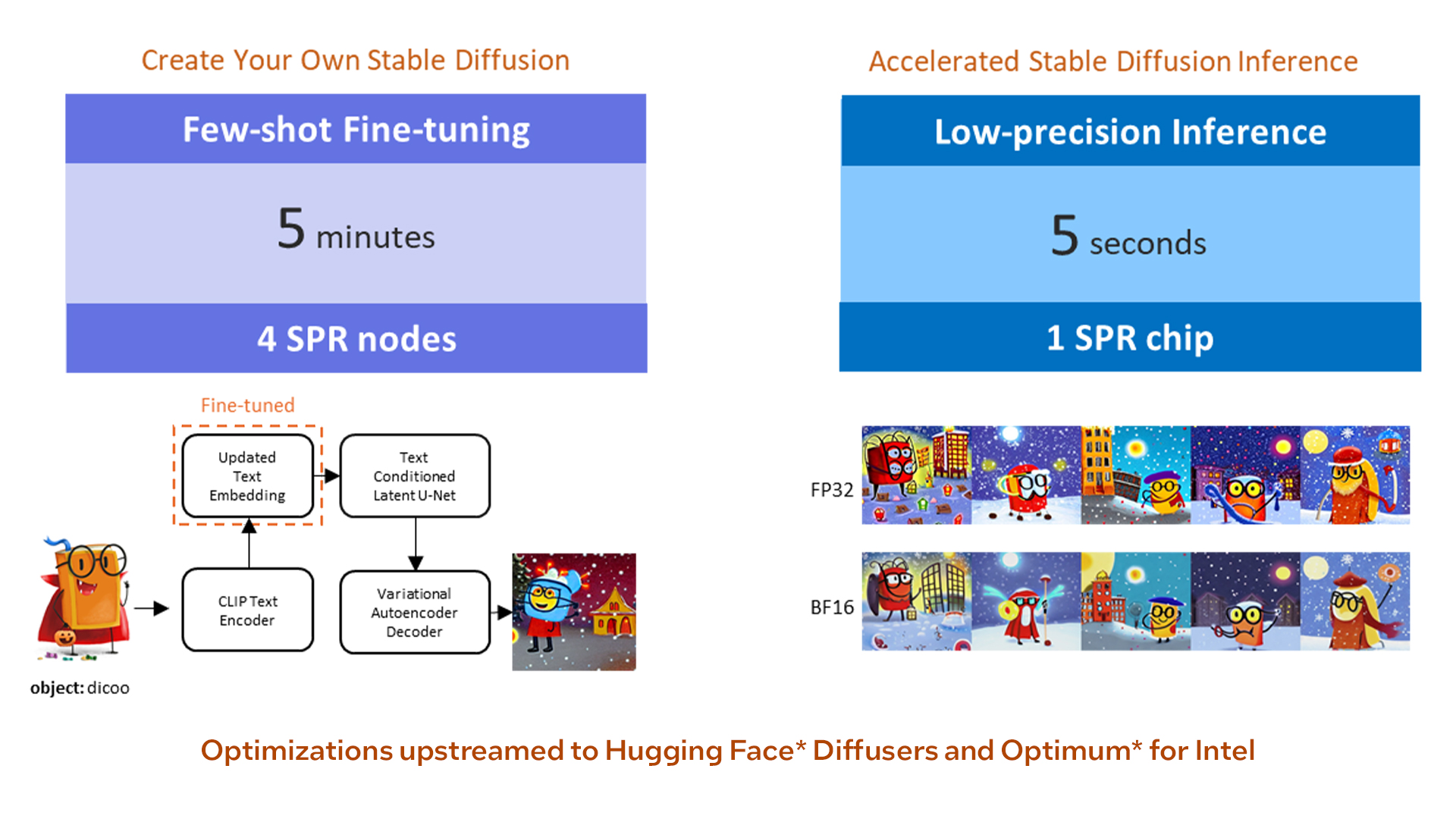
While training Stable Diffusion was expensive, taking 150,000 hours on 256 NVIDIA A100 GPU cards, fine-tuning the trained model and running inference can be done in a matter of minutes and seconds respectively on a 4th generation Intel® Xeon® Scalable processor. Stable Diffusion personalization, a technique to add new concepts to be recognized by the model while maintaining the capabilities of the pretrained model on text-to-image generation, can be created through few-shot fine-tuning with just one to a few images. Using the textual inversion technique, you can create a personalized Stable Diffusion using a cluster of four Intel Xeon Scalable processor nodes with Intel AMX and speed up the fine-tuning of your model from one-and-a-half hours (with a single-node 3rd generation processor) to less than five minutes.5 On inference, you can use Intel® Extension for PyTorch* to enable bfloat16 with auto-mixed precision for the entire inference pipeline and improve the inference performance significantly from 40 seconds to five seconds.5
AI Everywhere
Most businesses have a variety of workloads that already use a CPU server to run engineering development, databases, web services, and millions of other applications. Data engineering and classical machine learning stages of the E2E AI pipeline already run best on the CPU. With Intel AMX in 4th generation Intel Xeon Scalable processors, the deep learning performance of CPUs is now also comparable at the level of GPUs. The ubiquity, flexibility, and unmatched general and AI performance of the latest Intel Xeon processors combined with open accelerated software now allows businesses and individuals to take advantage of the power of AI (including generative AI) in all of their applications with just a CPU or in combination with other processors when they too become more ubiquitous.
Additional Resources
Get hands on with transformer-based machine learning models such as those for generative AI, check out Intel® Extension for Transformers*. To learn more about Intel’s performant and productive portfolio of E2E AI software tools and access developer resources, visit AI & Machine Learning.
Product and performance information: 1, 2, 3, 4, 5: PyTorch model performance configurations: 8480+: 1-node, preproduction platform with 2x Intel Xeon Platinum 8480+ on Archer City with 1024 GB (16 slots/ 64GB/ DDR5-4800) total memory, ucode 0x2b0000a1, HT on, Turbo on, CentOS Stream 8, 5.15.0, 1x INTEL SSDSC2KW256G8 (PT)/Samsung SSD 860 EVO 1TB (TF); 8380: 1-node, 2x Intel Xeon Platinum 8380 on M50CYP2SBSTD with 1024 GB (16 slots/64 GB/ DDR4-3200) total memory, ucode 0xd000375, hyperthreading on, turbo on, Ubuntu* 22.04 LTS, 5.15.0-27-generic, 1x INTEL SSDSC2KG960G8; Framework: https://github.com/intelinnersource/ frameworks. ai.pytorch.privatecpu/tree/d7607bdd983093396a70713344828a989b766a66; Intel® AI Reference Models: https://github.com/IntelAI/models/tree/spr-launch-public, PT:1.13, Intel Extension for PyTorch: 1.13, oneDNN: v2.7; test by Intel on 10/24/2022. PT: NLP BERT-Large: Inf: SQuAD1.1 (seq len=384), bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,56, Intel AMX bf16=1,16, Intel AMX int8=1,56, Trg: Wikipedia 2020/01/01 (seq len =512), bs:fp32=28, Intel AMX bf16=56 [1 instance, 1socket] PT: DLRM: Inference: bs=n [1socket/instance], bs: fp32=128, Intel AMX bf16=128, Intel AMX int8=128, Training bs:fp32/Intel AMX bf16=32k [1 instance, 1 socket], Criteo Terabyte Dataset PT: ResNet* 34: SSD-ResNet 34, Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,112, Intel AMX bf16=1,112, Intel AMX int8=1,112, Training bs:fp32/Intel AMX bf16=224 [1 instance, 1socket], Coco 2017 PT: ResNet 50: ResNet 50 v1.5, Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,64, Intel AMX bf16=1,64, Intel AMX int8=1,116, Training bs: fp32, Intel AMX bf16=128 [1 instance, 1 socket], ImageNet (224 x224) PT: RNN-T ResNet 101 32x16d, Inference: bs=1 [4 cores/instance], bs=n [1socket/instance], bs: fp32=1,64, Intel AMX bf16=1,64, Intel AMX int8=1,116, ImageNet PT: ResNeXt 101: ResNeXt101 32x16d, bs=n [1socket/instance], Inference: bs: fp32=1,64, Intel AMX bf16=1,64, Intel AMX int8=1,116 PT: MaskRCNN: Inference: bs=1 [4cores/instance], bs=n [1socket/instance], bs: fp32=1,112, Intel AMX bf16=1,112, Training bs:fp32/Intel AMX bf16=112 [1 instance, 1socket], COCO 2017 Inference: ResNet 50 v1.5: ImageNet (224 x224), SSD ResNet 34: coco 2017 (1200 x1200), BERT Large: SQuAD1.1 (seq len=384), ResNeXt101: ImageNet, Mask RCNN: COCO 2017, DLRM: Criteo Terabyte Dataset, RNNT: LibriSpeech. Training: ResNet 50 v1.5: ImageNet (224 x224), SSD ResNet 34: COCO 2017, BERT Large: Wikipedia 2020/01/01 (seq len =512), DLRM: Criteo Terabyte Dataset, RNNT: LibriSpeech, Mask RCNN: COCO 2017.480: 1-node, preproduction platform with 2x Intel Xeon Platinum 8480+ processor on code name Archer City with 1024 GB 3 6.7X inference speed-up: 8480 (1-node, preproduction platform with 2x Intel Xeon Platinum 8480+ processor on code name Archer City with 1024 GB (16 slots/64 GB/DDR5-4800) total memory, ucode 0x2b000041), 8380 (1-node, 2x Intel Xeon Platinum 8380 processor on code name Whitley with 1024 GB (16 slots/64 GB/DDR4-3200) total memory, ucode 0xd000375) hyperthreading off, turbo on, Ubuntu 22.04.1 LTS, 5.15.0-48-generic, 1x INTEL SSDSC2KG01, BERT-large-uncased (1.3GB: 340 million param) https://huggingface.co/bert-large-uncased, IMDB (25K for fine-tuning and 25K for inference): 512 seq length – https://analyticsmarketplace.intel.com/find-data/metadata?id=DSI-1764; SST-2 (67K for fine-tuning and 872 for inference): 56 Seq Length – fp32, bf16, int8, 28/20 instances, https://pytorch.org/, PyTorch 1.12, Intel Extension for PyTorch 1.12, transformers 4.21.1, Intel® Math Kernel Library 2022.1.0, test by Intel on October 21, 2022. 5: NVIDIA configuration details: 1x NVIDIA A10: 1-node with 2x AMD* Epyc 7763 with 1024 GB (16 slots/64 GB/DDR4-3200) total memory, hyperthreading on, turbo on, Ubuntu 20.04, Linux* 5.4 kernel, 1x 1.4 TB NVMe SSD, 1x 1.5TB NVMe SSD; Framework: TensorRT 8.4.3; PyTorch 1.12, test by Intel on October 24, 2022. 6: 4th generation Intel Xeon Scalable processor fine-tuning, 1 to 4 nodes, 2S, Intel Xeon Platinum 8480+ processor 56 cores on Dennard Pass platform and software with 512 GB memory (16 x 32 GB DDR5 4800 MT/s [4800 MT/s]), microcode 0x90000c0, hyperthreading on, turbo on, Rocky Linux 8.7, 4.18.0-372.32.1.el8_6.crt2.x86_64, 931.5G SSD. Multiple nodes connected with 200 Gbps OmniPath*. PyTorch 1.13, Intel Extension for PyTorch 1.13, transformers 4.24.0, accelerate 0.14, diffusers 0.8.0, oneDNN 2.6.0, Intel® oneAPI Collective Communications Library (oneCCL) 2021.7.1; 4th generation Intel Xeon Scalable processor inference. 1 node, 2S, Intel Xeon Platinum 8480+ processor 56 cores on code name Archer City platform and software with 1024 GB (16 x 64 GB DDR5 4800 MT/s [4800 MT/s]), microcode 0x2b000111, hyperthreading on, turbo on, Ubuntu 22.04.1 LTS, 5.15.0-56-generic, 1.5 TB SSD. Multiple nodes connected with 100 Gbps Ethernet controller I225-LM. PyTorch (commit ID: 26d1dbc) + PR 81852, transformers 4.25.1, accelerate 0.14, diffusers 0.8.0, oneDNN 2.6.0; 3rd generation Intel Xeon Scalable processor inference. 1 node, 2S, Intel Xeon Platinum 8380 CPU at 2.30 GHz 40 cores on Whitley platform and software with 512 GB (16 x 32 GB DDR4 3200 MT/s [3200 MT/s]), microcode 0xd000375, hyperthreading on, turbo on, Ubuntu, 5.15.0-56-generic, 7.0 TB SSD. Multiple nodes connected with 10 Gbps Ethernet controller X710 for 10GBASE-T. PyTorch (commit ID: 26d1dbc), transformers 4.25.1, accelerate 0.14, diffusers 0.8.0, oneDNN 2.6.0: Test by Intel on December 9, 2022.