The Problem with Message Latency
While memory bandwidth and thus throughput has improved tremendously over the years, end-to-end latency for short messages hasn’t changed much over the last 25 years. These short messages are, however, vital for multicore communication and compute for data intensive workloads in distributed systems. Not taking their importance into account can lead to serious performance degradation.
In this article, we will discuss using a mofified ring buffer to optimize short message latency and throughput. By carefully refining the design of the classic ring buffer, we can boost througput to 450 million 64-byte messages per second from multiple senders to a single 4th generation Intel® Xeon® Scalable Processor core (8 requestors and a single server thread).
This outlines the beginnings of our multi-front efforts to accelerate multicore coherent communication and distributed data management.
Coherent Memory Fundamentals
Most programmers are aware of modern multicore processors’ basic coherent memory design: If one core writes a memory location and then another core reads it, the second core will get the new value. Of course, there are many additional subtleties to this, and different architectures have different models for “memory ordering,” but the general idea remains the same.
The workflow timing of sending individual messages is straightforward, with the general outline being.
|
Core 1 |
Core 2 |
|---|---|
|
Write Message Buffer |
|
|
Atomic Write Flag with “release” semantics |
|
|
|
Atomic Read Flag with “acquire” semantics |
|
|
Read Message Buffer |
The flag write with release semantics does whatever is necessary on the platform to ensure that the message buffer writes become visible to other threads no later than the write to the flag. The flag read with acquire semantics does whatever is necessary on the platform to ensure that the reads to the message buffer happen no earlier than the read of the flag.
This is all fine, but what happens when you want to send many messages?
The obvious thing to do is for the receiver to acknowledge the message by clearing the flag and for the sender to check the flag before writing a new message, but this turns out to be quite slow and thus inefficient.
Coherent Memory Multicore Complexity
So, let's examine the concept of coherency more closely to see if we can find a more compelling approach.
At the top of this post, we mentioned that modern multicore processors have coherent memory. In the early years of multiprocessors, this sort of thing was done by having each CPU read and write main memory on every access. There were no caches and no memory ordering issues. Cores are so fast these days, and main memory is so relatively slow that performance would be quite disappointing without caches. When one thread on one core is reading and writing memory, the caches intercept most accesses and quickly return results. However, it gets quite complicated when multiple cores want to use the same memory locations, either accidentally or on purpose.
Many designs use a coherence protocol called MESI (Modified, Exclusive, Shared, and Invalid), reflecting the accessibility and validity status of data. When multiple cores read a location, it can be in both caches in a “shared” state. When either core wishes to write, the other copy must first be invalidated. To address this, most designs use a cache directory type implementation where an on-chip “caching and home agent” keeps track of which cores have copies of each address and in which states.
When a core wishes to write, and the state is not exclusive, the core must ask the home agent for permission. If any other caches have copies, the home agent sends them “snoop invalidate” messages. Once those are acknowledged, the home agent sends the requesting cache permission to enter an exclusive state.
If a core wishes to read a location and it is invalid, the core must ask the home agent for permission. The home agent can either return the data (from memory or L3 cache) or if some other core has the location in exclusive (or modified) state, the home agent asks the owning agent to move to state shared and return any modified data to the agent so that the agent can deliver it to the requesting core.
Some designs use the MOESI (Modified Owned Exclusive Shared Invalid) protocol, which adds a fifth owner state. Owned data is tagged as both modified and shared. This designation allows modified data to be written back to the main memory before sharing it. While the data must still be written back eventually, the write-back may be deferred.
In short, it can get complicated, and the added complexity of all this messaging across the chip adds the potential for significant latency and performance degradation.
Core to Core Latency
So, how long does it take for one core to set a flag and another core to notice it? Let us write a test program and find out!
Suppose we look, for example, at a two-socket Intel® Xeon® CPU Max 9480 Processor-based system (code-named Sapphire Rapids) with 112 cores and 224 threads. Each core in this system has two hyperthreads, which share the core hardware.
The code example has two threads, which set themselves to run on specified cores and then bounce a flag back and forth, measuring the number of time stamp counter ticks it takes to complete a given number of handoffs.
Latency Test Code Example
In our example configuration, the read timestamp counter (RDTSC) ticks at 2 GHz, and the program shows the following data for half-round trip times.
|
Situation |
RDTSC Counts |
Nanoseconds |
|---|---|---|
|
Same core (other HT) |
33 |
16.5 |
|
Same socket |
123 |
61.5 |
|
Other socket |
300 |
150 |
Note:
For a more detailed discussion of the effects resulting in these observations, you can check out Jason Rahman’s Core-to-Cory Latency study on SubStack. [1]
Core-to-Core Bandwidth
We have established that core-to-core communication latencies can easily become undesirably high, but what about bandwidth?
We can measure this, too, by writing a buffer on one core, waiting for the flag, and then reading the buffer on another core and measuring the time. Using the same platform configuration as before and a similar methodology, we find that if one core writes 32K bytes, it takes about 9000 RDTSC counts, or 4.5 microseconds, for another core to read it. That translates to about 7.3 GB/sec.
Interestingly, a recent new instruction called CLDEMOTE lets the programmer hint to the hardware that a cache line should be pushed down in the cache hierarchy, perhaps all the way to L3. When done, the second core can read 32K bytes in around 2900 RDTSC counts, or about 22 GB/sec. This number agrees with the observations John McCalpin reported in his presentation “Bandwidth Limits in the Intel® Xeon® CPU Max Series” at the International Supercomputing 2023 IXPUG Workshop. [2]
We also know that a processor core can have quite a few outstanding memory operations. For example, in the first case here, reading data that is dirty in a different core’s cache, we can traverse 512 cache lines (32K bytes) in 4.5 microseconds, or about 8.8 nanoseconds each, even though the same socket round trip is 120 nanoseconds. The data flow here is delivered by combining out-of-order execution, multiple outstanding memory references, and aggressive hardware prefetching.
Core-to-Core Messaging Takeaway
With these measurements, we can establish a “roofline” for core-to-core messages. They inform us of hardware limits to latency and bandwidth and a software goal.
The key takeaway from our observations thus far is that a fast core-to-core protocol should avoid memory coherence activity as much as possible.
At this point, we let us dig into a popular message queuing mechanism, the ring buffer, to see what additional controls on the core-to-core messaging performance we may have.
The Ring Buffer
Ring buffer data structures have a long history of being used as bounded queues between producers and consumers. Many closed and open-source libraries, technical papers, and book expositions are available, as are ring buffer data structures.
For example, Herlihy’s “The Art of Multiprocessor Programming” [3] devotes a chapter to the subject. Figure 1 shows a classic ring buffer design using shared control variables.

Figure 1. Classic Ring Buffer Design
Configuration Details for Tests in this Article
Testing Date: Performance results are based on testing by Intel as of October 25, 2024 and may not reflect all publicly available security updates.
Configuration Details and Workload Setup: 1-node, 1x Intel® Xeon® CPU Max 9480 processor on Denali Pass platform with 512 GB (16 slots/ 32GB/ 3200) total DDR5 memory, ucode 0x2c0001d1, HT on, Turbo on, EIST on, SUSE Linux Enterprise Server 15 SP5, 5.14.21-150500.55.80-default, 1x NVMe 1.0TB OS Drive; Intel(R) oneAPI DPC++/C++ Compiler 2024.2.0 (2024.2.0.20240602).
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure.
Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex. Your costs and results may vary.
Code Example: Classic Ring Buffer
Let us look at a C++ class that implements the idea of a ring buffer:
We can take some measurements if we use a test program that starts a receive thread on one core and starts N sending threads on other cores.
Each sender of this program has a copy of the ring. The receiver polls all of them in turn until the expected number of messages has been received. In addition, each thread uses the Performance Counter API (PAPI) library to record the number of Data Cache Misses during a run. All runs use 100,000 messages per sending thread.
|
Number of senders |
RDTSC Cycles Per Message |
Receiver misses per message |
Sender misses per message |
|---|---|---|---|
|
1 |
181 |
2.3 |
1.98 |
|
2 |
107 |
2.4 |
2.4 |
|
4 |
144.8 |
2.9 |
2.9 |
|
8 |
117.6 |
2.92 |
2.92 |
|
16 |
134.7 |
2.87 |
2.92 |

The peak bandwidth here is achieved with two clients and one server thread. We measure about 1.2 gigabytes per second, with a message rate of 18.7 million messages per second. The miss rates (for four client threads or more, are just about 3 misses per message for both sender and receiver.
These results make sense because each end of the connection will take a miss on the read pointer, the write pointer, and the message itself.
The big problem here is that the shared_read_pointer and the shared_write_pointer, as their names suggest, are used by both sender and receiver, which leads to additional coherence activity that may not be logically necessary.
|
|
Sender Use |
Receiver Use |
|---|---|---|
|
Write Pointer |
Allocate Ring Space |
New Message Detection (notification) |
|
Read Pointer |
Flow Control (ring full detection) |
Flow Control |
Message Notification
Briefly put, the receiver needs to know when a new message is available. With the classic ring buffer, when the write pointer is not equal to the read pointer, at least one message is available. The receiver must touch three memory locations to receive a message: the write pointer, the read pointer, and the message itself.
But suppose the message-ready flag is in the message itself? Then, the receiver can both test for the presence of a new message and read it in one access! In a ring buffer, the receiver always knows where the next message will arrive but not when. As long as we can guarantee that at least one bit of a new message differs from the previous message to occupy the same ring buffer slot, the receiver can always tell when a new message is present.
We could dedicate a bit of a ring slot as a flag. The sender can set it, and the receiver can clear it. But we can do even better by having the sender toggle the flag bit between one use of the buffer and the subsequent use. That way, the receiver never has to write into the buffer, which simplifies the buffer's coherence.
Flow Control
The sender needs to know if there is space in the ring before it can send a new message. In the classic ring buffer, the ring is full when the read pointer is one location ahead of the write pointer. Otherwise, there is at least one open slot.
The sender must touch three memory locations to send a message: the write pointer, the read pointer, and the message itself. If we don’t insist, though, that, indeed, every slot in the ring be usable, flow control can be done in a lazier way, which requires much less interaction between sender and receiver.
In particular, the receiver can keep a second copy of its own read pointer, specifically for use by the sender for flow control, but update it only occasionally, every 10th or 100th message. This way, the coherence traffic needed for flow control can be greatly reduced.
If we combine these two ideas:
- putting the message notification in the message itself
- making flow control to be “lazy”
then the sender can send a message with just a fraction over one cache miss per message: the message itself and an occasional miss while checking the lazy flow control value.
Here is a reimplementation of the ring buffer object that incorporates these ideas.
Code Example: New Ring Buffer
Rerunning the test program gives dramatically better results.
|
Number of senders |
RDTSC Cycles Per Message |
Receiver misses per message |
Sender misses per message |
Messages per second (x10^6) |
GB/Sec |
|---|---|---|---|---|---|
|
1 |
48.2 |
1.23 |
.99 |
41.5 |
2.7 |
|
2 |
9.8 |
1.001 |
1.01 |
205.0 |
13.1 |
|
4 |
6.8 |
1.005 |
1.002 |
294.1 |
18.8 |
|
8 |
5.3 |
1.002 |
1.001 |
375.5 |
23.9 |
|
16 |
5.9 |
1.03 |
1.002 |
339.1 |
21.7 |
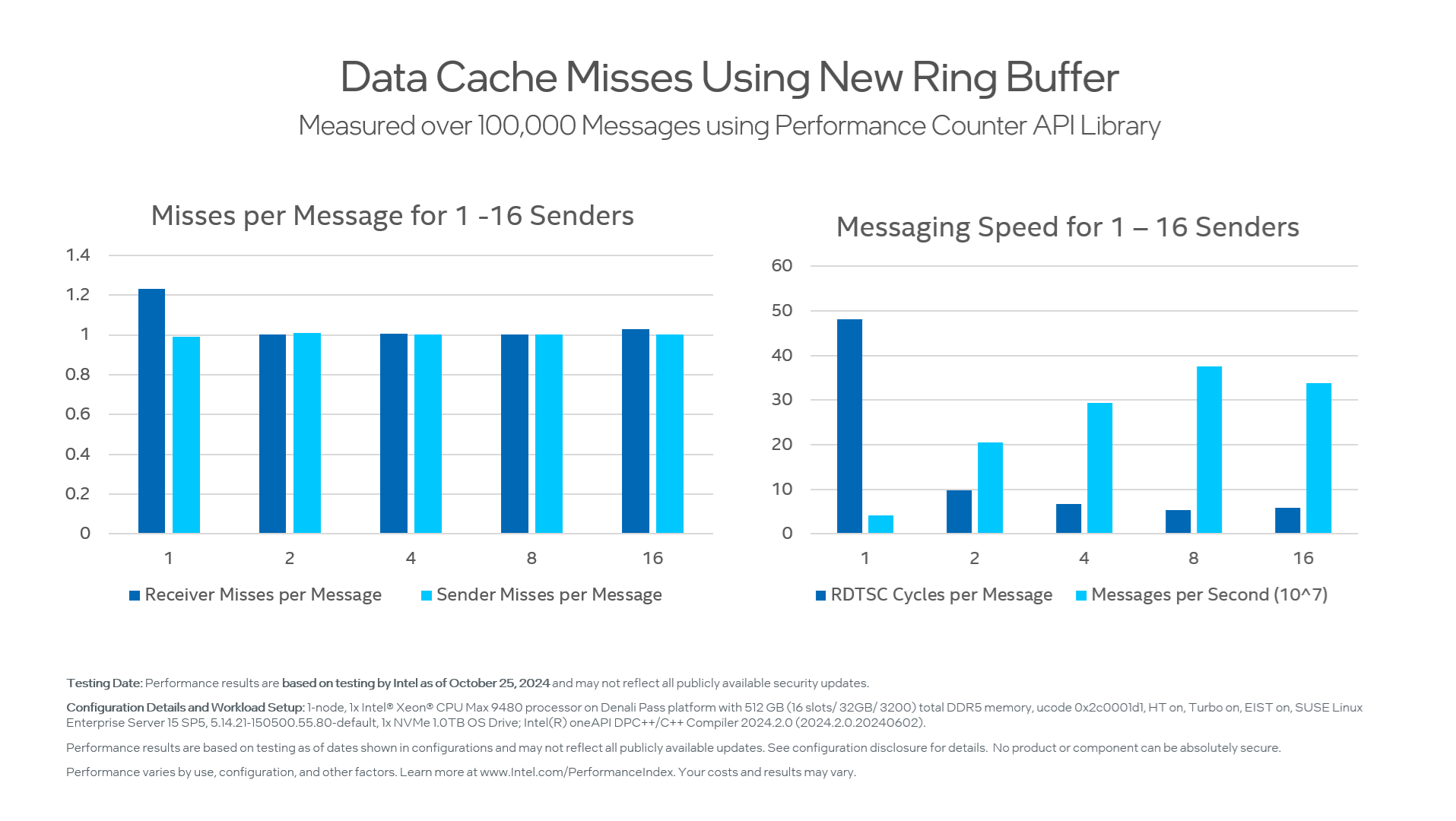
A single sender can now send 41 million messages per second or 2.7 GB/sec at 64 bytes per message.
The performance scales well, and with 8 clients, it reaches 375 million messages per second and about 24 gigabytes/second. In short, we’ve doubled the performance of a single ring buffer and made the design scalable up to nearly the bandwidth limits of the receiving core.
Cache Line Demote
But wait! Remember the new CLDEMOTE instruction? What if we use it to “push” newly written messages from the originator L1 towards lower cache levels? Let's try it!
Table using CLDEMOTE to nudge messages on their way.
|
Number of senders |
RDTSC Cycles Per Message |
Receiver misses per message |
Sender misses per message |
Messages per second x10^6 |
GB/sec |
|---|---|---|---|---|---|
|
1 |
63.6 |
1.33 |
0.0001 |
31.5 |
2.0 |
|
2 |
38.2 |
1.18 |
0.0003 |
52.3 |
3.3 |
|
4 |
22.2 |
1.085 |
0.0003 |
90.0 |
5.8 |
|
8 |
4.4 |
1.002 |
0.0001 |
452.5 |
29.0 |
|
16 |
4.4 |
1.02 |
0.0001 |
457.7 |
29.3 |
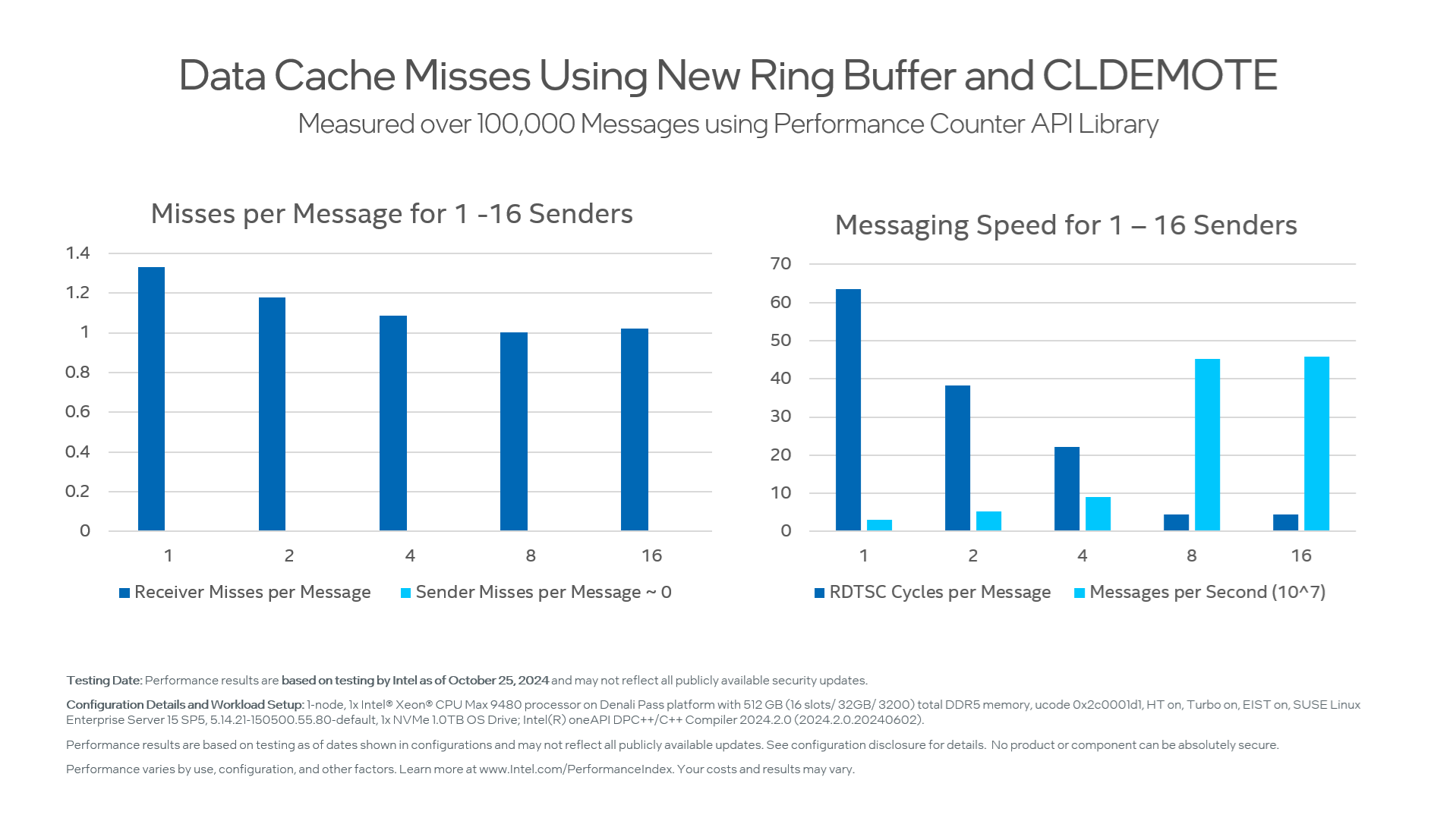
This is quite interesting! Using CLDEMOTE slows the program a bit for 1 thread, slows it down quite a lot for 2 or 4 threads, and speeds it up by 20% for 8 and 16 threads. With enough threads, the individual clients have enough time to complete their CLDEMOTEs before the server polls, and it is a win. With few threads, sometimes the wait time of the poll operation goes up due to the extra memory system activity. On balance, it seems that CLDEMOTE is a good idea if it is not on the critical performance path.
Conclusion
Queue designs that minimize memory coherence events can dramatically improve core-to-core message rate and latency. In particular, one can design a queue that, on average, for 64-byte messages, achieves just over 1 cache miss per message at each sender and receiver.
Actively managing the cache level and data hierarchy can additionally aid with significant performance improvements in heavily threaded applications. Stay tuned for more
Download the Toolkits
Check out the Intel® oneAPI HPC Toolkit to stay current with the latest developments in compute-intensive distributed and high-performance computing. You can also download individual components like the Intel® MPI Library standalone.
Watch this space for more articles and discussions of interesting software architecture and performance topics.
References
[1] Rahman, J (2023), Intel® Xeon® Scalable Processor Core-To-Core Latency, SubStack
[2] McCalpin, J (2023), Bandwidth Limits in the Intel® Xeon® CPU Max Series, International Supercomputing 2023 IXPUG Workshop
[3] Herlihy, M. et al. (2020), The Art of Multiprocessor Programming 2nd ed., Elsevier, ISBN: 9780124159501.