The COE at Durham University
oneAPI Centers of Excellence are led by top influencers in academia and industry. They contribute to oneAPI through the early adoption of oneAPI features, enabling open-source code bases to run with oneAPI, curriculum development, and extending the oneAPI ecosystem. They drive innovation for open, standards-based, cross-architecture, unified programming models.
The COE at Durham University, led by Professor Tobias Weinzierl, develops ExaHyPE, a generic collection of state-of-the-art numerical ingredients to write new solvers for hyperbolic equation systems. The group recently used it to design a solver for gravitational waves called ExaGRyPE (Figure 1). ExaHyPE's compute core is entirely written in C++ and has backends for Intel® oneAPI Threading Building Blocks (oneTBB), OpenMP*, native C++, and SYCL* to facilitate data and task parallelism and to offload tasks to accelerators. Recent work on efficient SYCL kernels, a co-authorship with colleagues from Intel, has for example been presented in a SIAM PP 24 paper. In this article, we discuss how their combined experience with ExaHype PDE and oneAPI components is being used to drive forward the oneTBB specification and implementation.

Figure 1: ExaGRyPE is a numerical relativity code built on top of ExaHyPE. This work, championed by Han Zhang, is collaboration between Durham’s Department of Computer Science and the Institute for Computational Cosmology and exploits advanced task parallelism through oneTBB.
oneTBB is a generic C++ library for host-side task-based parallelism that simplifies the work of adding parallelism to complex applications, even for non-experts. It is attractive as both a direct way to add parallelism for CPUs through its generic parallel algorithms, concurrent containers, and task-based scheduler. The components of oneTBB are shown in Figure 2. oneTBB is a backend for a wide range of libraries and frameworks, including OpenVINO™, oneDNN, oneMKL, the VFX Reference Platform, the Universal Scene Descriptor (USD) library, and, of relevance to this article, the ExHyPE PDE engine.
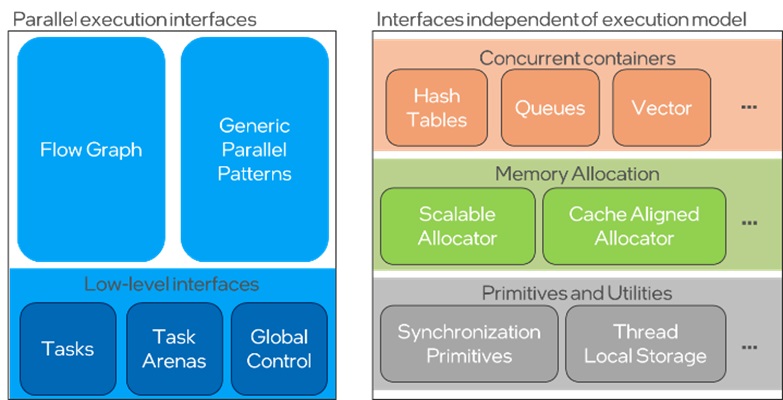
Figure 2: The components of the oneTBB library. The COE at Durham University is driving extensions in both Generic Parallel Algorithms and the Low-level Task interfaces.
While developing the oneTBB backend for ExaHyPE, the team at Durham found that they needed to implement extensions for oneTBB, including a generic ND range (an n-dimensional iteration space) and a framework for dynamic task graphs. As a oneAPI COE, they took the extra step to feed these improvements back into the oneTBB specification and implementation to benefit the broader oneTBB and oneAPI communities.
The COE at Durham was the first oneAPI Academic COE in the UK, and it should be noted that they are blazing the trail again as they become the first external group to contribute a large feature to oneTBB after it has moved its governance to the Unified Acceleration Foundation (UXL). So, not only are we benefiting from technical advances in oneTBB, but we are also shaking out the UXL process for the oneTBB library through this collaboration.
A Generic ND-Range
The first outcome of this collaboration, which clearly highlights the value of user-focused extensions driven by external partners, is the specification of a new oneTBB range type, blocked_nd_range.
The most widely used oneTBB generic parallel algorithms, such as parallel_for, take a Range as an argument. Prior to the collaboration with the COE at Durham University, the oneTBB specification and implementation provided only three concrete range types: blocked_range, blocked_range2d, and blocked_range3d.
The example in Figure 3 shows a parallel_for that receives a 1-dimensional blocked_range as its first parameter that represents the half-open interval [2,n). This range also has a minimum grainsize of 4 (the third parameter to its constructor).
tbb::parallel_for(
tbb::blocked_range<size_t>(2,n,4),
[=](const tbb::blocked_range<size_t>& r) {
for(size_t i=r.begin(); i!=r.end(); ++i)
Foo(a[i]);
}
);
Figure 3: A use of parallel_for with a blocked_range.
Given the code in in Figure 3, the oneTBB library recursively subdivides the range [2,n) into subranges, never subdividing a subrange that is of the grainsize (4) or less. The library schedules tasks that apply the user-provided functor to these subranges.
In ExaHype, the team at Durham University needs higher-dimensional ranges for its numerical schemes: Its Finite Volume scheme, for example, runs loops over a three-dimensional voxel field, looks per voxel into each dimension, and then updates all quantities of a PDE. The team, therefore, felt it necessary to implement a generic ND range type that could represent tensors of any dimensionality. The functionality was simply missing as a concrete type in the oneTBB library. To be fair, the oneTBB team had experimented with ND ranges in the past, even implementing a preview feature for the library. But without clear customer feedback, that preview feature was never formalized as part of the oneTBB specification. The COE at Durham University stepped in to provide that necessary feedback, to get this feature across the finish line and into the specification, and to add the last set of convenience constructors. More on that below.
The proposed blocked_nd_range represents a recursively divisible N-dimensional half-open interval. It can be interpreted as a Cartesian product of N instances of blocked_range, where all ranges are specified over the same Value type.
template<typename Value, unsigned int N> class blocked_nd_range;
It is important to note that a oneTBB Range is not equivalent to a standard C++ range; it requires functions that are used to efficiently split the Range into subranges that are appropriate as parallel tasks. These extra functions include special splitting constructors and an is_divisible function. The team from Durham clarified the semantics for all of these. In addition to these Named Requirements, an ND range type also needs to provide the appropriate set of constructors to satisfy the real use cases of customers.
In collaboration, we decided that two constructors could capture most use cases:
1) blocked_nd_range(const dim_range_type& dim0
/*, ... N parameters of the same type*/);
2) blocked_nd_range(const value_type (&size)[N],
size_type grainsize = 1);
The first constructor receives exactly N blocked_range objects; one per dimension. This first constructor provides maximum flexibility. Each dimension can have specific starting and ending points for the range and a different grainsize (that is the smallest size allowed for subdivision). The second constructor captures what we believe to be the most common case. It receives an array of exactly N Value elements and a single grainsize. The second constructor assumes that each range i is from 0 to size[i] and they all have the same minimum grainsize. The collaboration between the oneTBB development team and the Durham University COE was critical in providing a well designed interface that integrated well with existing oneTBB APIs and met the real needs of developers.
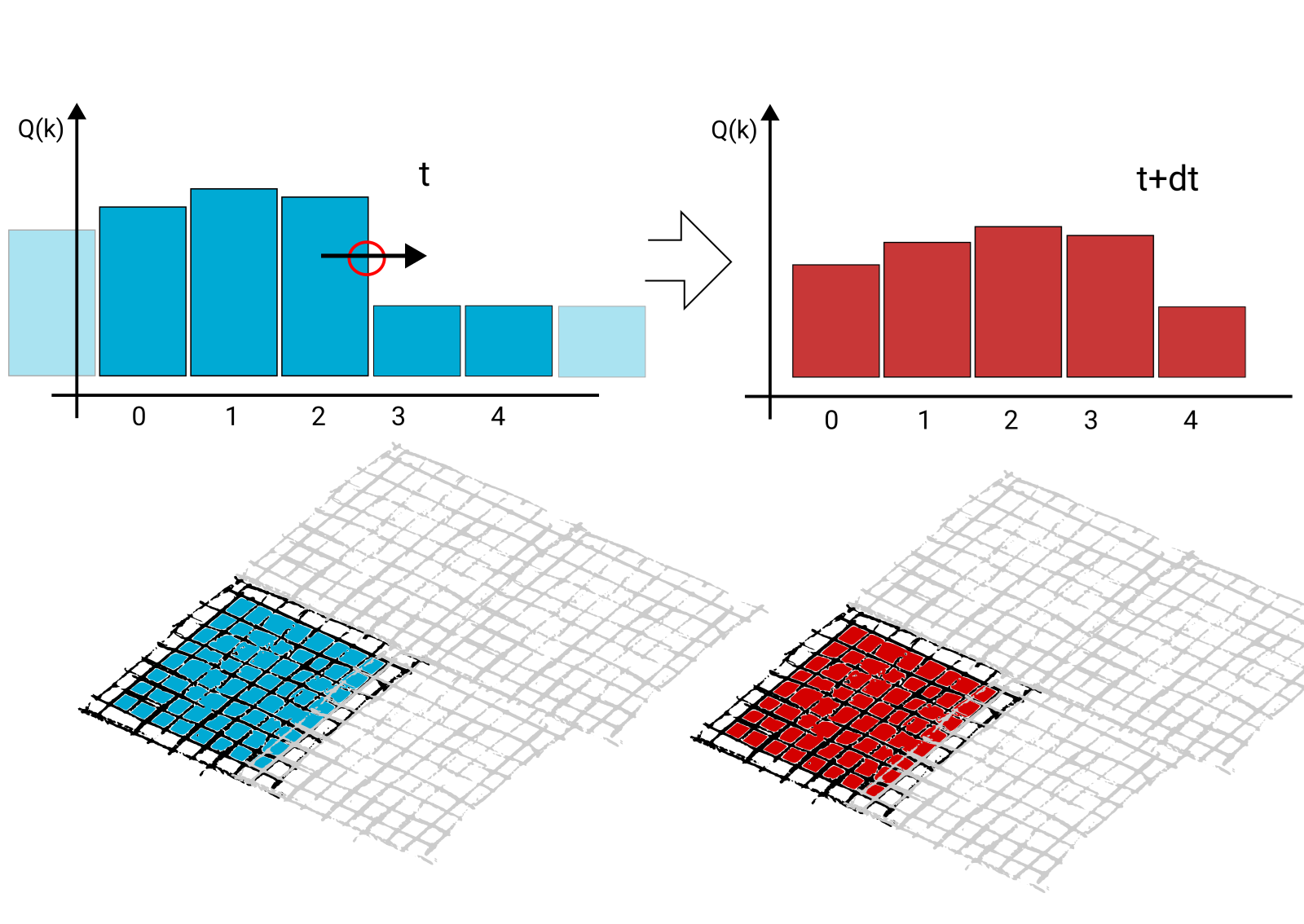
Figure 4: Finite Volume schemes – the simplest numerical scheme used within ExaGRyPE – update all voxels of a patch in parallel.
Per voxel, fluxes in x-, y- and z-direction have to be computed. Some steps within the algorithm iterate once more over all unknowns. Previously, the outer x-, y-, z-loop was mapped onto a blocked_range, while the embedded further loops had to be plain for-loops. With the new blocked_nd_range, we can expose the whole concurrency within one single construct.
This proposal is currently on track to be included in the oneTBB specification in November 2024. You can find more details about this extension in the Unified Acceleration Foundation (UXL) GitHub* oneAPI Specification.
Dynamic Task Graph
Where the collaboration between the COE at Durham University and the oneTBB development team on blocked_nd_range got an experimental feature across the finish line and into the oneTBB specification, the collaboration on dynamic task graphs is much broader.
When TBB was included in oneAPI as oneTBB, the oneTBB team took the opportunity to modernize the TBB library, dropping overspecified interfaces and taking advantage of modern C++ features that were enabled by oneAPI’s requirement for C++17 compilers. Part of this modernization included dropping of the lowest-level tasking API in favor of higher-level APIs such as task_group and flow graph. Most uses for the lowest-level API quickly found effective migration strategies to these higher-level APIs. But there were challenges for some customers.
Durham University, with a long tradition of work on task-based algorithms, is working with the oneTBB development team to enhance the task_group API to tackle the challenges. Notably, they propose to bring back dynamic task graphs, as we know them from OpenMP.
The first part of the proposal is to extend the objects returned by task_group (task_handle objects) to represent tasks for the purpose of adding dependencies. With the new handles, we can submit tasks straightaway, and make the predecessors to other tasks later on. This dramatically increases the theoretical concurrency, as we can, in many cases, avoid an expensive, sequential task graph assembly. The definition of task_group in the oneTBB 1.3 specification is shown below. The function defer creates a new task_handle and the functions run and run_and_wait have overloads that receive task_handle objects.
class task_group {
public:
task_group();
task_group(task_group_context& context);
~task_group();
template<typename Func>
void run(Func&& f);
template<typename Func>
task_handle defer(Func&& f);
void run(task_handle&& h);
template<typename Func>
task_group_status run_and_wait(const Func& f);
task_group_status run_and_wait(task_handle&& h);
task_group_status wait();
void cancel();
};
To support dynamic task graphs, the semantics of task_handle will be extended to represent tasks that have been created, submitted, are currently executing, or have been completed.
Next, in the current task_group, tasks can only be waited for as a group, and there is no direct way to add any before-after relationships between individual tasks. The proposal adds functions for specifying before-after relationships between tasks (represented by task_handle objects).
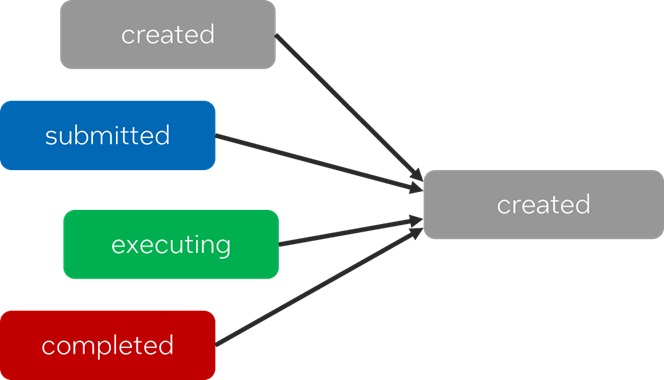
This functionality is necessary for recursively generated task graphs and to fully support low-level tasking scenarios that rely on continuations.
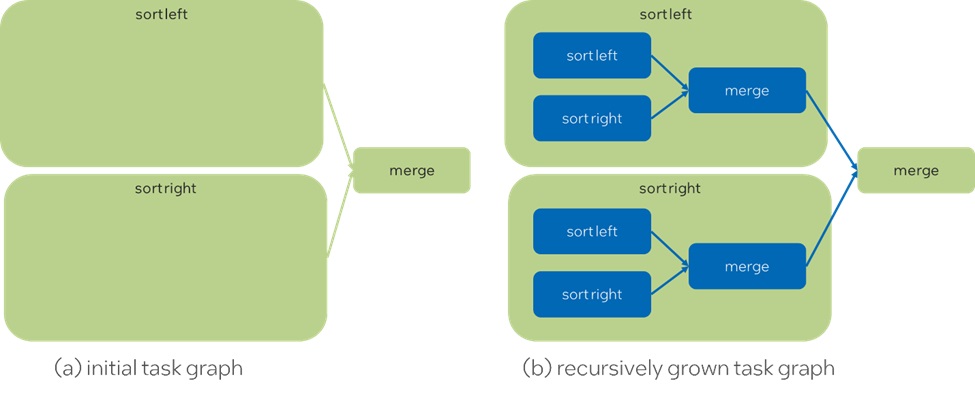
To learn more, and contribute your thoughts to this proposal, join us at the open source oneTBB GitHub repository to participate in the RFCs process.
Influence the Future of Parallel Compute
The UXL's Working Group and Special Interest Group processes allow everybody to influence the direction of feature development for important software building blocks such as oneTBB. The Intel-Durham collaboration is a prime example how this works in practice.The Unified Acceleration Foundation is a great pathway for COEs to have impact on industry standards. In addition to senior staff at Intel and academic researchers at the University of Durham, we had support from BSc/MSc students (Johannes Bockhorst), PGT students (Chung Ming Loi) and Durham’s Research Software Engineers to accomplish these goals. The projects are open to contributors in all career stages. Even fairly bespoke niche requirements can be taken into consideration and addressed this way. Developers are in charge of changing the landscape of software design!
Acknowledgments:
The proposals described in this paper are a group effort. We’d like to especially acknowledge the efforts of Johannes Bockhorst, Chung Ming Loi, Pavel Kumbrasev, Alexey Kukanov, Ruslan Arutyunyan, Jay Mahalingam, and Heinrich Bockhorst.
The collaboration between the oneAPI Academic Centre of Excellence (COE) in Durham University's Department of Computer Science and Intel’s oneTBB development team is a great example of the important role that oneAPI COEs can play. In this article, we provide an overview of this collaboration and two proposed features (ND ranges and dynamic task graphs) for oneTBB that demonstrate how COEs, like Durham University, are shaping the future of oneAPI.