This article was originally published on vectara.com.
Introduction
Reducing LLM hallucinations continues to be a critical capability for RAG applications, and new and improved models continue to demonstrate lower and lower hallucination rates.
The Hughes Hallucination Evaluation Model (HHEM) has exceeded 120,000 downloads since its launch in November 2023. Since then Vectara released a new version of the model that is integrated into Vectara’s RAG (retrieval augmented generation) pipeline – the Factual Consistency Score.
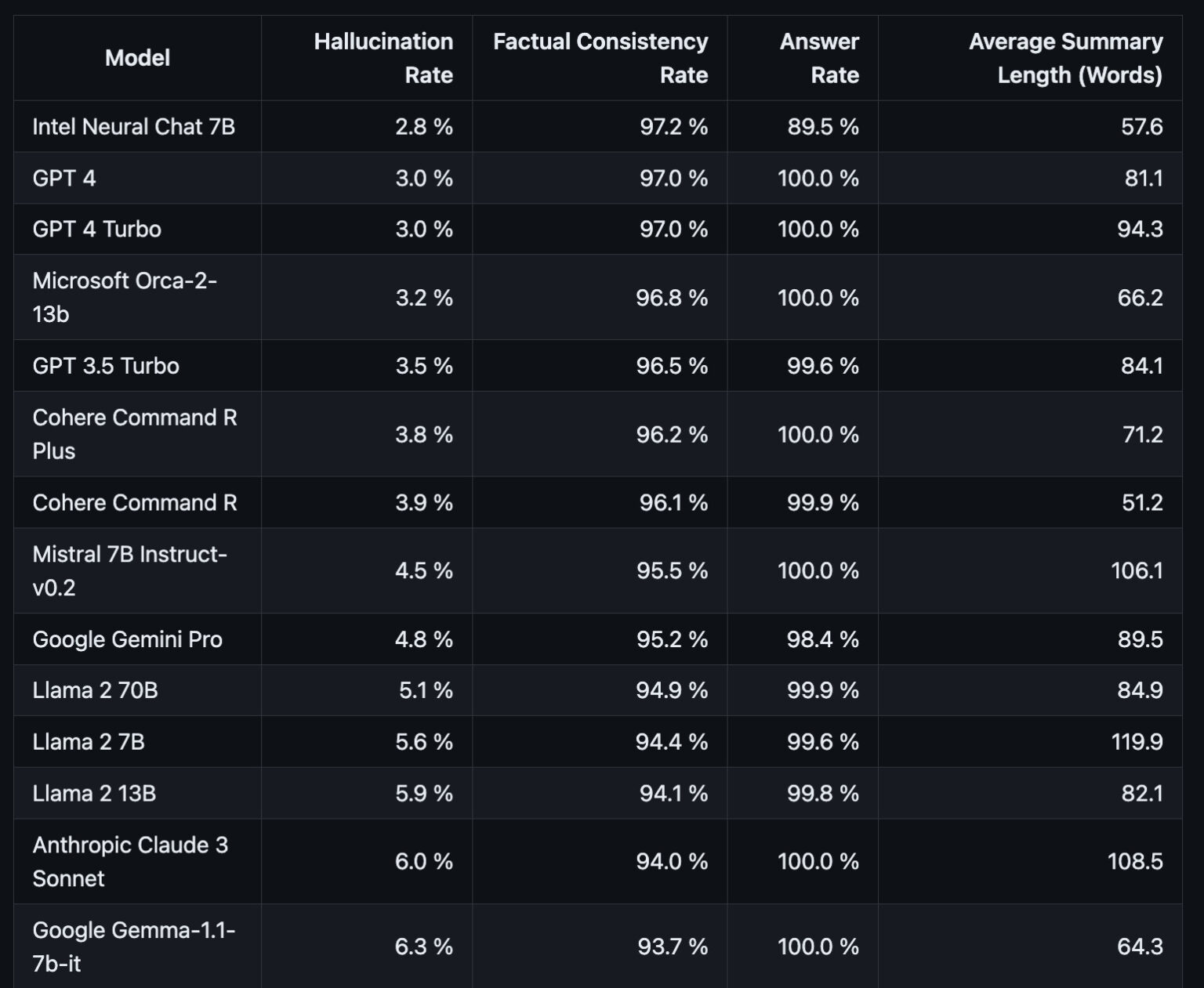
Intel’s neural chat 7B has achieved a low hallucination rate on Vectara’s HHEM leaderboard, demonstrating how small-size models can achieve hallucination rates comparable or even better (lower) than LLMs that are much larger in size. The collaboration between Vectara and Intel establishes a new standard in the industry for ensuring accuracy and reliability for RAG application developers, and we are excited to see improved capabilities of small language models that push the boundaries of natural language processing through technological advancements.
Hallucination Rate’s Impact On RAG Applications Performance
Hallucination rate refers to the frequency at which the LLM fails to summarize facts provided to it in the context of retrieval augmented generation (RAG).
This metric is crucial for determining the effectiveness and accuracy of any RAG system: A high hallucination rate can lead to incorrect responses and confusion for the user. By maintaining a low hallucination rate, users can trust the information presented by the RAG application and rely on its assistance in various tasks.
Small Models Can Have a Low Hallucination Rate
It’s true that so far, for the most part, larger models seem to perform better than smaller ones, and LLM vendors continue to increase the size of both training sets and model sizes to get better performance. However large models do have a significant downside – inference is difficult, expensive, and slow.
Guess what? smaller models are starting to catch up.
A smaller model may not perform best overall (although some do perform pretty well, a good example is Mixtral 8x7B) but it may perform very well on a specific task you care about, such as – in our case – the ability to reduce hallucinations.
And Intel’s new model does exactly that.
Intel’s Neural-chat 7B
Intel recently released their newest LLM – the Neural Chat 7B, a model based on Mistral-7B and optimized using an Intel® Gaudi® 2 processor and aligned using the Direct Preference Optimization (DPO) method based on Intel’s DPO dataset. For more details on the model, refer to the blog.
This model achieves an impressively low 2.8% hallucination rate and is ranked highest on the HHEM leaderboard at the time this blog post was published (A big thanks to Minseok Bae for running the evaluation).
This hallucination rate is even lower than GPT4 (3%), even though GPT-4 is estimated to include 1.8T parameters vs a mere 7B for Intel’s Neural Chat model.
Conclusion
Vectara’s HHEM continues to be adopted by the LLM community as the de-facto standard for hallucination detection, and we’ve seen some key improvements in the likelihood of LLMs to hallucinate, Google Gemini Pro at 4.8%, Cohere Command-R at 3.9%, and most recently Intel’s Neural-chat 7B at 2.8%.
The important thing to remember is that LLMs are capable of many things: reasoning, summarization, code generation, and a variety of other tasks. Correctly summarizing facts in a consistent manner is one of their superpowers and can be done well even with smaller models. We are excited to see a significant improvement in reducing hallucinations of LLMs, as it contributes broadly to the entire community by making RAG better.
Don’t miss out on this powerful partnership driving accuracy and innovation in AI development.
Vectara recently integrated an improved version of its hallucination detection model (factual consistency score or FCS), that is integrated into our RAG-as-a-service flow. You can sign up for an account and try it for yourself, and if you have any questions please reach out to Vectara forums or on our Discord server.