
Training AI models requires access to a great deal of data. Typically, the more data you use, the more accurate your model. In some cases, organizations may want to train models using data shared across multiple organizations but are unable to because the data is legally protected by regulations such as HIPAA or GDPR, too sensitive or valuable to share, or too large or costly to transmit. This is a common problem for organizations like banks or hospitals that work with sensitive data.
Open Federated Learning (OpenFL), a Linux Foundation incubation project, can help overcome data silos. It supports a complete federated learning system architecture, enabling organizations to collaborate on AI training without needing to share any private data. OpenFL uses an Intel-enabled trusted execution environment (TEE) to improve the security of data and models and is designed to be easy to use to help developers and data scientists accelerate deployment time.
In this demo, we’ll show you how OpenFL can help improve model accuracy while keeping models secure and preserving data privacy. Watch the full demo here.
OpenFL Overview
OpenFL supports all popular machine learning frameworks, including Keras, PyTorch, and TensorFlow. Designed to be easy to use, OpenFL prioritizes:
- Scalability: Grow and manage multiple large federations
- Security: Protect data and valuable model IP
- The developer experience: Get started with real-world federated learning as quickly as possible
How It Works
In an OpenFL workflow, each institution agrees to a federated learning plan before training begins, including who will take part in the experiment, what data will be accessed, and visibility into what code will run where.
At regular intervals during training, each collaborator updates its model weight and sends it to a central model aggregator, which combines the individual model weights to construct a global model. The aggregator sends the global model to each collaborator so they can continue training with the global model, enabling collaborators to train the same model without sharing data.
Intel-Based TEEs for Extra Security
An important component of the workflow is the governor, a centralized service that brings together datasets from each collaborator. The governor uses Intel® Software Guard Extensions (Intel® SGX) to provide a TEE for important services such as securing the ledger and remotely attesting the aggregator node and each collaborator node. OpenFL also provides an Intel SGX-enabled TEE for the aggregator and collaborator nodes, protecting each important service in a secure enclave. All communication between the governor, the aggregator, and collaborators uses mutual TLS (mTLS) for maximum privacy. Data is encrypted at rest, encrypted in motion, and with an Intel TEE it is now encrypted while in use.
For even more protection, OpenFL integrates Intel® Trust Authority, an attestation service that is the first step toward creating a multi-cloud, multi-trusted execution environment service. It attests to the legitimacy of Intel SGX enclaves and the software components running within. The governor uses Intel Trust Authority attestation to verify that the code and model, agreed to ahead of time, have not changed at runtime.
Demo: How to Train AI Models with OpenFL
Let’s demonstrate how to use OpenFL to train a model using sensitive patient data from multiple institutions without any data leaving the institutions. For this demo, we run OpenFL on the Red Hat OpenShift platform.
You can follow along with the full demo.
Finding Your Intel-Certified Plugins in Red Hat OpenShift
Intel certifies and distributes different device plugins that expose Intel accelerators and CPU features to Red Hat OpenShift. To see which Intel® plugins are running in your cluster, find the “Operators” menu, select the “Installed Operators” option, and select the “Intel Device Plugins Operator.” In this example, our cluster is running Intel SGX.

Find your cluster’s active Intel® plugins by navigating to the “Installed Operators” menu in Red Hat OpenShift.
Reviewing Plugin YAMLs
For additional details on the Intel SGX plugin, navigate to the "Nodes" section within the "Compute" section. To locate information related to Intel SGX, open the SGX YAML file and search for "epc," which refers to enclave page cache. The epc annotation was first added by node feature discovery (NFD). NFD labels nodes to identify their capabilities, letting the Intel SGX plugin know to run on that node.

In the Intel® SGX YAML, NFD has added an epc annotation, letting the Intel SGX know to run on that node.
Scrolling farther down the YAML, you can see our node’s epc memory capacity is more than 136 gigabytes.
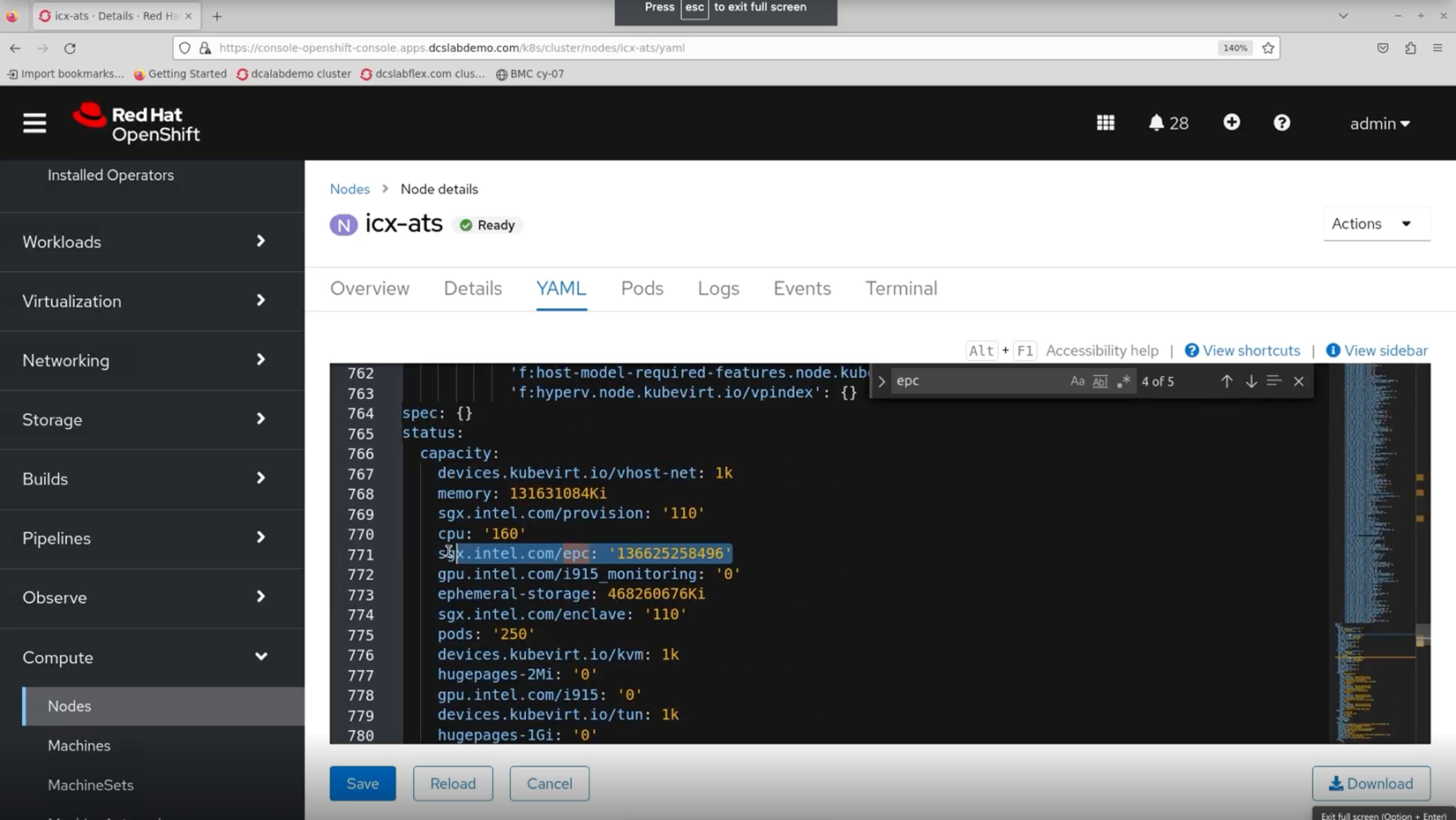
You can check the YAML for the node’s epc memory capacity.
Registering Datasets with the Governor
Switching over to the terminal screen. The experiment register function uses the OpenFL binary, called fx, to set the governor URL, another machine in this subnet. This machine could be anywhere on the internet. Once the aggregator and collaborators are activated, each dataset is registered with the governor. The datasets in this example include medical images of patients who have been diagnosed with different brain diseases.

Each institution’s dataset is registered with the governor, shown in the window on the left. In this example, we’re processing medical images of various brain diseases.
Approving the Training Plan
After the datasets are registered with the governor, each collaborator receives a plan ID and votes on the plan. Once each collaborator has voted, the first round of training can begin.
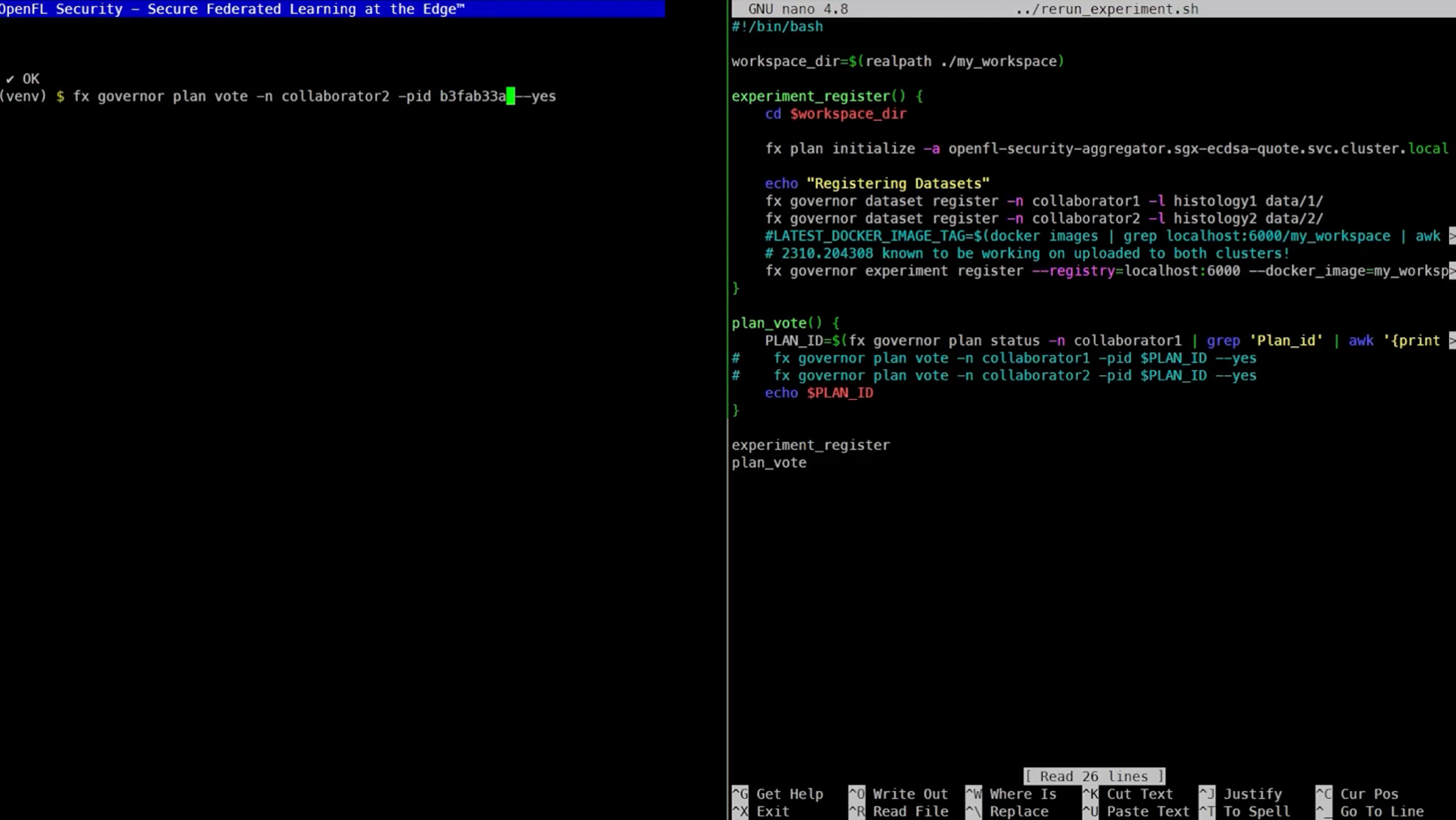
Before training can begin, each collaborator is assigned a plan ID, or “pid,” and votes to approve the plan.
Training Your Model
During training, the top window displays the aggregator log, gathering data from the collaborators. The center and bottom windows display the logs of each collaborator. We built the container images with Gramine Shielded Containers (GSC), which allow applications like OpenFL to run unmodified within an Intel SGX enclave.
Each collaborator node loads its private data into an Intel SGX enclave. The enclave ensures that the local data matches the parameters specified in the plan via a hashing function. After a few minutes, the plan IDs are registered and each collaborator gets a token from the Intel Trust Authority, attesting their encrypted memory enclave and the software manifest within. Now training begins.
When the first round of training is complete, the aggregator creates an updated model that factors in the weighted average of both collaborator datasets and then shares the updated model with both collaborators.

Now that round one training is completed, the aggregator will share the global model back to each collaborator for round two.
The second round of training on the updated model then begins. OpenFL repeats this process until the training criteria is met while continuing to fine-tune the model for improved accuracy. This sequence is done with local data only—no private data is ever shared with any other node in the federation.
Accessing the Final Model
Once training is complete, you can log into your node and go to the temp directory to find the final model in the files exchange. For this demo, we set up a temp directory. However, when running OpenFL in a production environment, you’ll want to make sure you consider how you’d like to secure the model at rest.
Get Started
Visit the OpenFL GitHub repo to try federated learning using our easy-to-use software. As part of the repo, Intel is open sourcing the Intel SGX integration for both aggregators and collaborators to give your models an extra layer of protection as they train.
You can also find all of the Intel-certified plugins for Red Hat OpenShift on the Intel® Technology Enabling for OpenShift GitHub, including the Intel SGX plugin and Intel® GPU plugin, or get Intel® Device Plugins for Kubernetes on the Intel® Device Plugins for Kubernetes GitHub.
About the Author
Eric Adams, Cloud Data Software Engineer, Intel
Eric Adams is a cloud software engineer focused on Kubernetes. Over the course of his 22-year career at Intel, he’s worked in software development, software validation, and program management. He has a broad understanding of the gamut of computers and related technologies, including how high-speed differential signals propagate, how firmware interacts with hardware, how BIOS and the chipsets interact, different programming languages, and all things cloud native. Eric also has an MBA and takes particular interest in how companies strategically respond to competition.