Even More Detailed Optimization Reports in oneAPI 2025.0
Both the Intel® oneAPI DPC++/C++ Compiler and Intel® Fortran Compiler provide reports describing important optimizations performed (or not performed) by the compilers on your source code.
This enables the developer to get immediate feedback on their code and how compiler optimizations interact with it while writing, compiling, and testing it. In short, it helps to accelerate the software development cycle, and assists in achieving application performance goals faster.
For this latest set of compiler releases in version 2025.0, Intel focused on further improving the quality and level of detail provided in the optimization reports. This closes any perceived gaps with the reports provided by the Intel® C++ Compiler and Intel® Fortran Compiler Classic. We also looked closely at customer feedback and feature requests, implementing many new feature additions. Thank you for all the suggestions and proposals. This article outlines the most important changes.
Let us begin by revisiting the basic usage model of compiler optimization reports.
Optimization Report Basics
An optimization report can provide three kinds of remarks that offer guidance on optimizations and why they may have been applied or not applied:
- Optimizations that were successfully performed
- Optimizations that were missed for some reason
- Detailed information about both successful and unsuccessful optimizations
In the example below,
- the remark in green (#25436) indicates a successful optimization.
- the remark in red (#15344) indicates that a desirable optimization was not performed.
- the remarks in blue (#15346) give further detail about why it wasn’t possible.
This information may help you change your source code to improve performance. (Colors were added for clarity and do not appear in the optimization reports.)

There are several reasons you might want to generate an optimization report. As just noted, you might feel your code is running slower than expected, and you’d like to understand why. Performance analysis can be difficult, and looking at an optimization report can give you some immediate insights without resorting to performance tools such as Intel® VTune™ Profiler.
Types of Information
For example, you might see that the compiler did not vectorize a particular loop, and the remarks can help you understand how you might rewrite your code to allow the compiler to perform that optimization. By writing your code in several ways and comparing the optimization reports, you can learn how to “think like the compiler” and improve your results. You might also determine that the compiler may not perform optimally, and you can open a bug report against the compiler.
Optimization reports can be used to compare how different compilers handle your code. Intel’s classic compilers also provide optimization reports, so if you are porting your code from the classic compilers to the oneAPI compilers and you observe a change in performance (positive or negative), you can generate the optimization reports from both compilers to see if there is an obvious explanation for their different behavior.
Optimization reports are organized around your program's building blocks. That is, remarks are grouped by functions, loops, and OpenMP work regions, as shown in Figure 1.
Source location information (file, line, column) is appended to help identify where the loops and work regions appear in your code. To the extent possible, these building blocks appear within each section of the optimization report in source order; however, the optimizations themselves sometimes complicate this.
Aggressive loop optimizations can remove loops, introduce new loops, change the order of loops, fuse or split loops, and so on. The optimization reports reflect the new loop structure following these transformations. Still, source location information is present to identify where the original loop originated, and remarks are inserted to explain when loops are removed, introduced, or otherwise transformed.
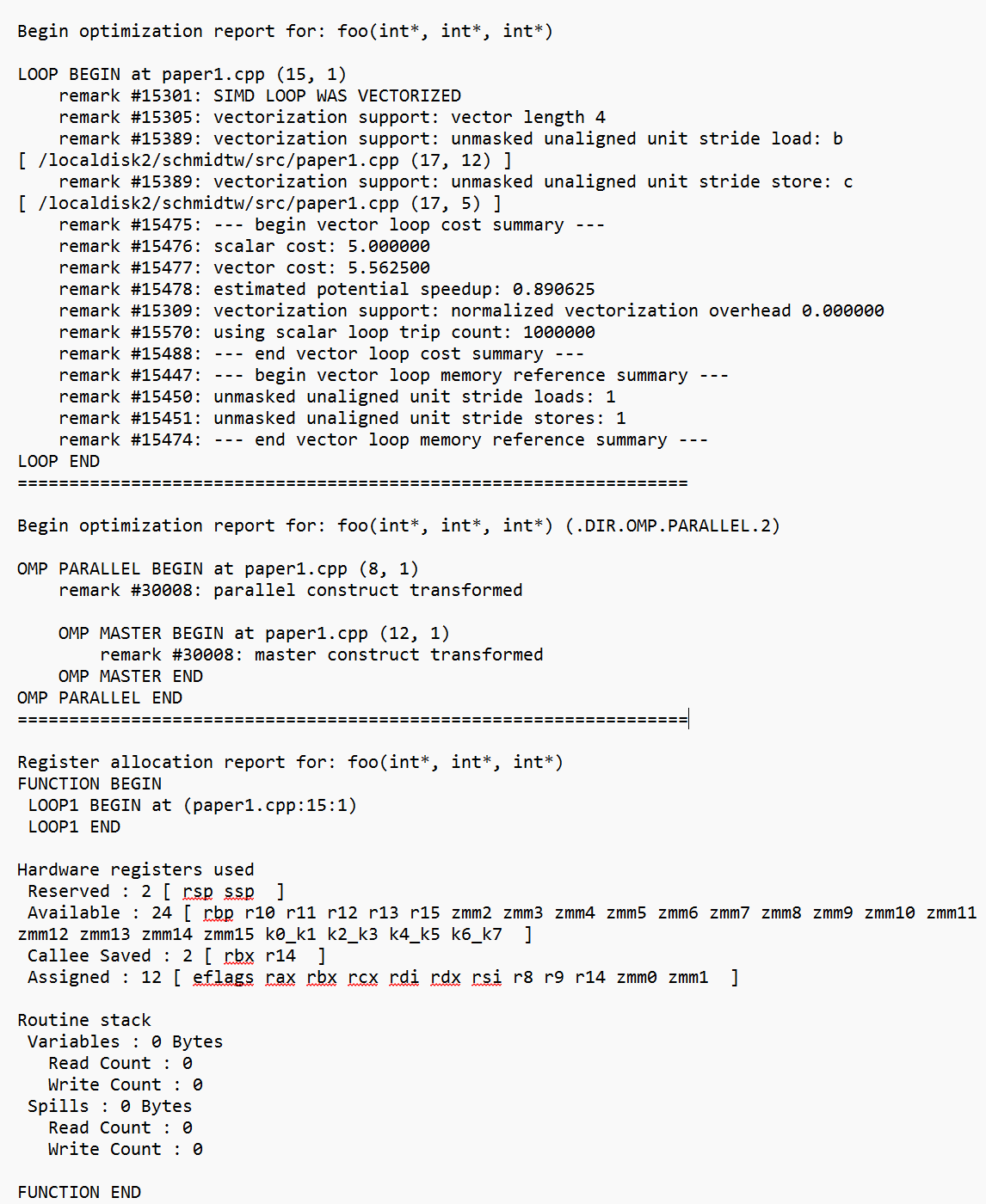
Figure 1: Typical Optimization Report Layout
At the module level (and whole-program level in the presence of link-time optimization), there is an inlining report to help you follow how the function structure of the code has been changed by inlining and other interprocedural optimizations, such as function cloning. There is also a report for profile-guided optimizations, which can be driven by instrumented or sampled profiling (“hardware PGO”). When you use specialized hardware such as GPUs and FPGAs for accelerated computation, separate optimization reports are generated for the offloaded computation.
Adding Report Generation
Requesting an optimization report is as simple as adding -qopt-report (Linux) or /Qopt-report (Windows) to the compilation command line. You can optionally specify a “verbosity level” for the report by appending “=N” where N is a value between 0 and 3. Each higher level provides more remarks. The general rule of thumb is:
- N = 0: No optimization report (not very useful)
- N = 1: Include remarks for successful optimizations
- N = 2: Also include remarks for optimization that were missed (default)
- N = 3: Also include explanatory remarks to provide more detail
Here are some examples of Linux command lines:
icpx -c -O3 -qopt-report=2 myfile.cpp ifx -c -O3 -qopt-report=3 myfile.f90
And here are the equivalent commands for Windows:
icpx -c -O3 /Qopt-report=2 myfile.cpp ifx -c -O3 /Qopt-report=3 myfile.f90
These commands will produce a file named myfile.optrpt by default. If you wish, you can override the name (or redirect output to a stream) using the -qopt-report-file or /Qopt-report-file option. See the documentation for details.
Updates for Release 2025.0
With this background, let us look closer at some of the changes introduced with release 2025.0.
New Options
The oneAPI compilers now support the -qopt-report-phase=xxx (or /Qopt-report-phase=xxx) option, similarly to the option available for the Intel® Compilers Classic. This can be used to provide a smaller report focused on the area that interests you. The choices you can select are shown below.
|
Phase |
Action |
|
cg |
Only show the code generation report |
|
ipo |
Only show the interprocedural optimizations report |
|
loop |
Only show the loop optimizations report |
|
openmp |
Only show the OpenMP work regions report |
|
pgo |
Only show the profile-guided optimizations report |
|
vec |
Only show the vectorization report |
|
all |
Show all reports (default) |
You can also specify a comma-separated list of phases from the above list. As an example:
ifx -c -O3 -qopt-report=3 -qopt-report-phase=loop,vec myfile.f90
Another option available on the Intel Compilers Classic, and now available on the oneAPI compilers, is ‑qopt-report-names (or /Qopt-report-names). This allows you to choose whether to show “mangled” or “unmangled” function/method names in the optimization report. Since C++ has function overloading, a full specification of a function name must include a representation of its signature. Name mangling encodes the signature in a character string. Mangled names are found in assembly listings, so if you want to match the assembly listing, you can use -qopt-report-names=mangled. This will produce output like this:
Begin optimization report for : _ZN6matrix4readEii
If, instead, you want names to match the source code, use -qopt-report-names=unmangled, which is the default. The same function will instead be shown like this:
Begin optimization report for : matrix::read(int, int)
Fortran function names are also changed by this option, but not significantly.
Infrastructure Improvements
In previous releases, specifying -qopt-report caused generation of multiple optimization report files. In addition to the Intel optimization report, the underlying LLVM optimization report was also generated. You might have seen this as a large file ending with the .yaml extension. The LLVM optimization report is produced in binary format, requiring the separate opt-viewer.py tool to view in human-readable form. It’s also extremely verbose, requiring significant compile time to create, and is intended for consumption by compiler developers. We don’t recommend using the LLVM optimization report to our customers. Therefore, specifying -qopt-report will no longer cause the LLVM optimization report to be generated. If you are still interested in obtaining it, use the ‑fsave-optimization-record option.
Optimization reports are now available with the -O0 option, which is useful for debugging. Finally, the optimization report infrastructure is in the process of being reworked to better support the ordering of program sections (functions, loops, work regions) in the presence of complex optimizations. Limitations of the infrastructure have been responsible for reports that presented sections in a confusing order. Although these changes to the infrastructure are not directly visible to end users, we expect fewer cases of seemingly inconsistent section ordering. This work is ongoing and we expect to complete it in release 2025.1.
Improvements to Inlining and PGO Reports
The profile-guided optimization report has been greatly improved, with the data produced now being on par with the reports for the classic compilers. When data produced by instrumented PGO is available, the optimization report includes data for each function about whether (a) data was applied, (b) data was not applied due to the data not being found, or (c) data was not applied due to the function having changed since the data was collected. When data produced by hardware PGO is available, the optimization report describes which functions had the data applied. Additionally, there is information about which functions are considered “hot” and “cold” based on their profile usage and about indirect function calls that were specialized for specific call targets.
The inline report now works properly for Thin LTO mode (which allows for parallel compilation while performing whole-program optimization), ensuring data from one compilation is not overwritten by data from another compilation. We have also addressed some reported bugs related to the ordering of the output.
Improvements to Loop Optimization Reports
The loop optimizer now produces a remark for each loop, even those that have been completely optimized away. A placeholder “loop” appears in the report for purposes of holding this remark, and the location of the placeholder loop relative to other loops has been improved.
The loop optimizer now detects situations where it believes the user could make changes to improve performance and adds remarks in the optimization report explaining this. For example, the loop optimizer can see that a loop interchange optimization may be beneficial. However, the compiler may not do it automatically since the source loop nest is not “perfect.” (i.e., there are source statements between the different loops). The optimization report can flag this scenario and indicate that the user may get better performance by rewriting the source and interchanging the order of induction variables in the nest.
Figure 2: Nested Loop Impacting Optimization
As an example, consider the Fortran code in Figure 2. The programmer has placed two unrelated computations inside the same loop nest, perhaps thinking this will be more efficient than having two sets of loops. Suppose we compile the code with:
ifx -c -xAVX2 -qopt-report=3 paper2.f90 -qopt-report-phase=loop
The optimization report will contain an advice remark:
LOOP BEGIN at paper2.f90 (6, 7) remark #25445: Loop interchange not done due to: non-perfect loopnest remark #25451: Advice: Loop interchange, if possible, might help loopnest. Suggested Permutation: ( 1 2 3 ) --> ( 3 2 1 )
This explains that the outermost and innermost induction variables could be interchanged to produce better locality. However, the control flow inside the loop due to the IF statement prevents the compiler from doing this. After a little thought, the programmer can rewrite this code, as shown in Figure 3.
Figure 3: Nested Loop Resolved, Making Optimization Easier
Compiling this version of the code in the same manner shows that the compiler can now perform the loop interchange optimization on the second loop.
LOOP BEGIN at paper2a.f90 (12, 10) remark #25444: Loop nest interchanged: ( 1 2 3 ) --> ( 3 2 1 )
The optimizer can also point out when a group of memory references has poor spatial locality; that is, each subsequent reference is far away from the previous one. It can tell you when memory references aren’t known to be distinct or may involve phantom data dependencies that you can fix with annotations in your source code. When a loop nest is optimized to operate on blocks of memory to improve locality, remarks in the optimization report will indicate how to best tune the blocking factors. Finally, when the optimizer chooses to perform the unroll-and-jam optimization, it emits remarks into the report explaining how you can either suppress the optimization or tune it for better performance.
Writing optimal loop nests can be quite difficult, so look out for these advisory remarks and consider whether you can make suggested changes to improve your code’s performance. The optimizer may not have enough information to make these changes safely, so providing these remarks is the next best thing.
Improvements to Vectorization Reports
The OpenMP standard allows the creation of vectorized functions by specifying #pragma omp declare simd ahead of the function implementation. The oneAPI compiler optimization report now includes a section describing the function vectorization. This looks very much like the report you will see for loop vectorization but wrapped in a FUNCTION block instead of a LOOP block. It is possible to create more than one vectorized version of a function (for instance, using 256-bit vectors versus 512-bit vectors), and there is a separate report section for each such version.
The vectorizer now provides more information about memory references in vectorized code. At the highest verbosity level, the optimization report will include a remark for each vectorized reference, describing whether the reference is aligned on a vector boundary and/or masked and providing source location information (line:column) for the reference. When the -g option is selected, the vectorizer will also include limited name information for the memory reference in question.
For example:
LOOP BEGIN at test.c (2, 3) remark #15389: vectorization support: unmasked unaligned unit stride load: A (4:12) remark #15389: vectorization support: unmasked unaligned unit stride load: A (3:19) remark #15388: vectorization support: unmasked aligned unit stride store: B (3:10)
Here, the array names A and B appear only when -g is selected on the command line; otherwise, the available debug information is insufficient to produce array name information. Be sure to compile for debug if you want to see this information!
The vectorizer can also optimize groups of nearby memory references to use wide loads and shuffles instead of a gather load (and similarly for stores). The optimization report now includes remarks for this VLS (vector load/store) optimization. An example of this:
LOOP BEGIN at test1.c (6, 3) remark #15300: LOOP WAS VECTORIZED remark #15305: vectorization support: vector length 4 remark #15597: -- VLS-optimized vector load replaces 3 independent loads of stride 3 remark #15598: load #1 from: arr1 [ test1.c (9, 11) ] remark #15598: load #2 from: arr1 [ test1.c (7, 10) ] remark #15598: load #3 from: arr1 [ test1.c (8, 11) ] remark #15600: -- end VLS-optimized group LOOP END
A few other minor remarks have been added, and previously noted problems with ordering vectorized loops in the report have been corrected. Finally, the remark numbers for the vectorization report have been corrected to always match those from the Intel Compilers Classic where a match exists to ease porting of tools that relied on the existing remark numbers.
Improvements to OpenMP Reports
The compiler now produces two separate optimization reports for OpenMP when an offload target is specified. The host optimization report is named myfile.optrpt, as usual. The device optimization report has a name derived from the selected target. For example, if -fopenmp-targets=spir64 is specified, the name of the target report is myfile-openmp-spir64.optrpt. Furthermore, the contents of the target report include a banner emphasizing that the report is for offloaded device code.
The NAMED clause from OpenMP directives is now used wherever possible within the optimization report, providing source name information for clarity. This includes usage for map names and shared privatization. Map clauses implicitly generated by the compiler, rather than explicitly specified on an OpenMP directive, are identified as such.
Several new remarks have been added for both host-side and device-side optimization reports. These include remarks about transformations performed on loop constructs, remarks about loops running on the device, remarks identifying kernel local variables assigned to stack memory, and remarks about loop collapsing. The report has been divided into sections for clarity, similar to how the Intel Compilers Classic generated the reports.
Improvements to Code Generation Reports
The code generation section of the optimization report was empty before release 2025.0. Now, it includes a register allocation report that identifies registers used by the function, callee-save registers saved on the stack, and other information about function stack usage.
Looking Forward
The optimization reports produced by the Intel oneAPI compilers are intended to help our users understand how their code has been optimized and to stimulate ideas for rewriting code for better performance. With the release of 2025.0, we brought these reports up to the Intel Compilers Classic standards and improved them beyond those expectations. This is an ongoing project. We have many more improvements planned for future releases.
We would like to hear from those of you using the optimization reports. Ideas for additional improvements are most welcome! Let us know any extra compiler optimization guidance that could benefit your software development, by submitting your feedback in our community forums for the Intel® oneAPI DPC++/C++ Compiler and Intel® Fortran Compiler.
Download the Compilers Now
You can download the Intel oneAPI DPC++/C++ Compiler and the Intel® Fortran Compiler on Intel’s oneAPI Developer Tools product page.
This version is also in the Intel® Toolkits, which include an advanced set of foundational tools, libraries, analysis, debug and code migration tools.
You may also want to check out our contributions to the LLVM compiler project on GitHub.
Additional Resources
- oneAPI 2025.0 Release - Boost Developer Productity for AI and Open Accelerated Computing
- DPC++/C++ Developer Guide and Reference
- Fortran Developer Guide and Reference
- Hardware Profile-Guided Optimization
- oneAPI GPU Optimization Guide
- Find Bugs Quickly Using Sanitizers with the Intel® oneAPI DPC++/C++ Compiler
- LLVM-based Projects from Intel
Get Help
Your success is our success. Access this support resource when you need assistance.
- Intel Fortran Compiler Forum
- Intel oneAPI DPC++/C++ Compiler Forum
- For additional help, see our general oneAPI Support.