The performance of Intel Optane PMem and Intel Optane SSD is between DRAM and NAND SSD, as shown in Figure 1. We can take advantage of this feature to use the Intel Optane product as the client cache in the C/S architecture. This is conducive to improving client performance, reducing latency and tail latency, and ensuring persistence and reliability. This article introduces how to use Intel Optane PMem and Intel Optane SSD as client cache and takes the Ceph client cache as a specific case by introducing the design, architecture, performance, and advantages in detail.

Hardware
To implement a client cache, we need at least one client and one server. The C/S architecture is shown in Figure 2. There are storage devices on the server, and the cluster of storage is installed (like Ceph). The client should be equipped with Intel Optane PMem or Intel Optane SSD. In this article, the Optane PMem model is Intel® Optane™ Persistent Memory 100 Series 256GB Module NMA1XXD256GPSU4.

Software setup
The Intel Optane PMem device needs to be installed in the memory slot at the specified location. At the same time, CPU support is required. CPUs that are too old may not support Intel Optane PMem devices.
A clean Linux system in the client is needed. Tools, including ndctl and ipmctl, are used for installing and controlling the Intel Optane PMem device. Configure the Intel Optane PMem device in AppDirect mode and display it in the /dev/* directory.
ipmctl create -goal PersistentMemoryType=AppDirect
ipmctl show -goal
reboot
After rebooting the system, use the command ipmctl show -memoryresources to check whether it is successful. If it is successful, the capacity of the Intel Optane PMem is displayed in the AppDirect line. The device is displayed in a format like /dev/pmem0.1. Then we can use ndctl to create the region and namespace.
Client cache in Ceph
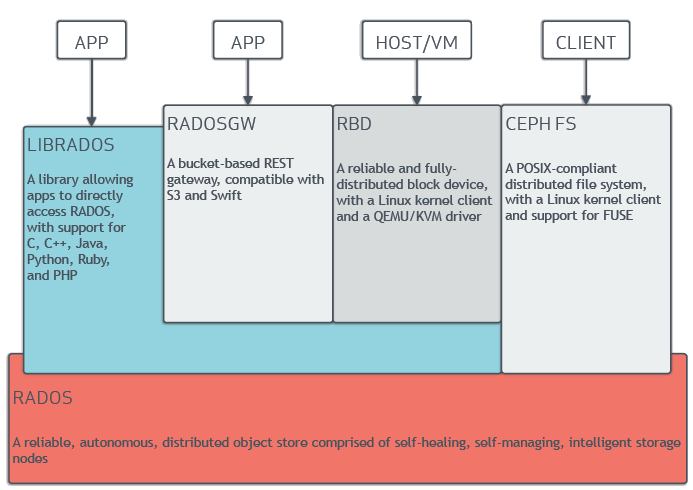
Ceph is a very popular open-source distributed storage system. It has the advantages of high scalability, high performance, and high reliability. It also provides RADOS Block Device (RBD), RADOS Gateway (RGW) and Ceph File System (CephFS). The architecture of Ceph is shown in Figure 3. RBD interfaces are a mature and common way to store data on media including HDDs, SSDs, CDs, floppy disks, and even tape.
librbd is a library that Ceph provides for block storage. It implements the RBD interface. The images of RBD integrate many features, such as exclusive lock, object map, journal, and so on. These features are often implemented at different levels when IOs are dispatched. librbd has two types of layers: ImageDispatchLayer and ObjectDispatchLayer as shown in Figure 4.
| ImageDispatchLayer | ObjectDispatchLayer |
|---|---|
| IMAGE_DISPATCH_LAYER_NONE = 0, | OBJECT_DISPATCH_LAYER_NONE = 0, |
| IMAGE_DISPATCH_LAYER_API_START, | OBJECT_DISPATCH_LAYER_CACHE, |
| IMAGE_DISPATCH_LAYER_QUEUE, | OBJECT_DISPATCH_LAYER_CRYPTO, |
| IMAGE_DISPATCH_LAYER_QOS, | OBJECT_DISPATCH_LAYER_JOURNAL, |
| IMAGE_DISPATCH_LAYER_EXCLUSIVE_LOCK, | OBJECT_DISPATCH_LAYER_PARENT_CACHE, |
| IMAGE_DISPATCH_LAYER_REFRESH, | OBJECT_DISPATCH_LAYER_SCHEDULER, |
| IMAGE_DISPATCH_LAYER_INTERNAL_START, | OBJECT_DISPATCH_LAYER_CORE, |
| IMAGE_DISPATCH_LAYER_MIGRATION, | OBJECT_DISPATCH_LAYER_LAST |
| IMAGE_DISPATCH_LAYER_JOURNAL, | |
| IMAGE_DISPATCH_LAYER_WRITE_BLOCK, | |
| IMAGE_DISPATCH_LAYER_WRITEBACK_CACHE, | |
| IMAGE_DISPATCH_LAYER_CRYPTO, | |
| IMAGE_DISPATCH_LAYER_CORE, | |
| IMAGE_DISPATCH_LAYER_LAST |
IO requests are dispatched layer by layer in the image layers, and functions are implemented at each layer. IO requests with raw addresses are processed at different layers. After IOs in one image layer are completely handled, they are not dispatched to the next image layer. They are encapsulated into an object layer and then distributed layer by layer until the IOs in the object layer are processed. Then, the requests are encapsulated into messages and sent to OSDs, which are the Ceph object storage daemons. The OSD’s main function is to store data. The latency of requests is the sum of several different parts, including:
- The latency of IO requests being dispatched and sent on the client;
- The network latency of the message being sent and received;
- The latency of OSDs parsing messages and storing data.
Step 1 takes about 50~200us, while steps 2 and 3 are greatly affected by the hardware. With the 40GB/s network transmission and high-speed NVME SSD as OSDs back-end in storage cluster, it still takes about 800~1000us.
If the Intel Optane PMem cache (or Intel Optane SSD cache) is added on to the client, the reliability, consistency, and persistence of the data can be guaranteed. In this scenario, the client-side cache can play a beneficial role, eliminating the latency by removing steps 2 and 3. Data is written back in the background by a reliable cache design and a persistent storage device. Intel Optane PMem can maximize the advantages of performance and latency. Although the performance of an Intel Optane SSD is slightly lower than that of an Intel Optane PMem, it is more economical.
In addition, rbd_cache has been implemented in RBD, but it uses DRAM as cache, which does not guarantee the security and reliability of data. Therefore, it does not conflict with the Intel Optane PMem and Intel Optane SSD as cache in this article, and the applicable scenarios are different.
Persistent write log cache
In RBD, we implement a client cache on Intel Optane PMem and Intel Optane SSD media and call it persistent write log (PWL) cache, as shown in Figure 5. The PWL cache provides a persistent, fault-tolerant write-back cache for librbd-based RBD clients.
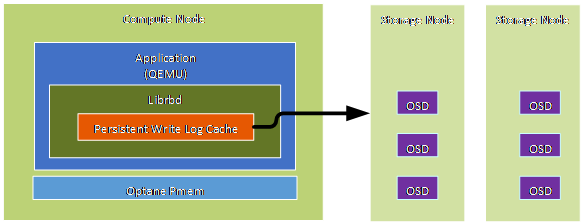
The PWL cache uses a log-ordered write-back design that maintains checkpoints internally so that writes that are flushed back to the cluster are always crash consistent. Even if the client cache is lost entirely, the disk image is still consistent, but the data will appear to be stale.
This cache can be used with PMEM or SSD as a cache device. For PMEM, the cache mode is called replica write log (RWL). At present, only a local cache is supported.
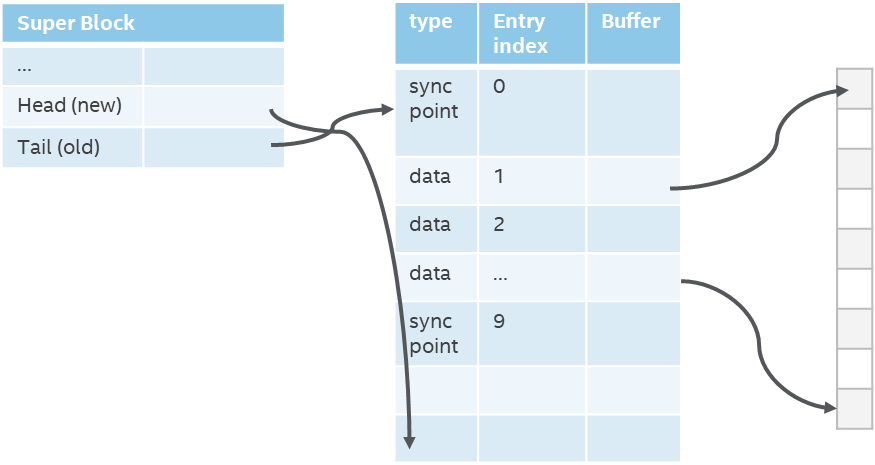
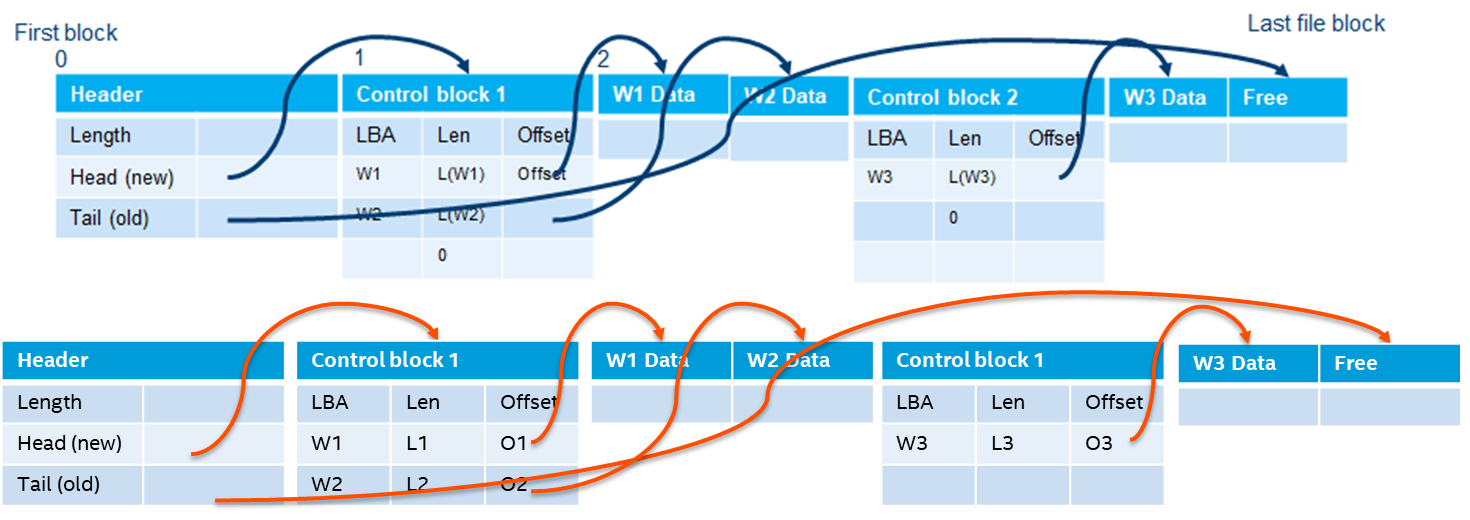
PWL cache is embedded in RBD through plug-ins. The plug-ins are initialized when the image is opened. This does not affect any original logic. We added a cache layer to the image layers of librbd to process IO requests. When IOs are sent to the PWL cache layer and captured, the PWL cache layer uses the function of this layer to process IOs and store data to the local Intel Optane PMem or Intel Optane SSD. Because pmem can be accessed like memory, it is very fast. The data index on pmem is shown in Figure 6. Then background thread writes the data back to OSDs. If we use Intel Optane SSDs as cache, we need to consider the large overhead of the storage and reading more. It’s better to batch store and read. So, we store control block and data continuously in SSD mode. The data storage method in an SSD is shown in Figure 7.
Test
Configuration of Ceph and enable PWL cache
1. Install Ceph clusters on 3 servers. Each server has 4 OSDs, and each OSD corresponds to 1 NVME SSD.
2. Install pmem on the client in appdirect mode so that pmem can be displayed in the /dev/* directory and can be used by applications
3. Enable PWL cache. The Ceph configuration file should be set as shown below:
rbd_persistent_cache_mode = rwl
rbd_plugins = pwl_cache
rbd_persistent_cache_size = 1073741824
rbd_persistent_cache_path = /mnt/pmem/cache/
Test methods and results
RBD bench
Use rbd bench to test cache from empty state to cache full state. Here is an example command:
rbd bench --io-type write --io-pattern rand --io-total 1024M testimage
The test results show that when the cache is not full, the IO bandwidth and IOPS are very high.
FIO
Use fio to test the performance of the cache in a stable state (when the cache is full). The test has the following dimensions:
- Test the latency under fixed IOPS and the performance under unfixed IOPS.
- Test the latency and performance under io_depths of 1, 8, 16, and 32.
- Test the performance of Intel Optane PMem and Intel Optane SSD as cache devices.
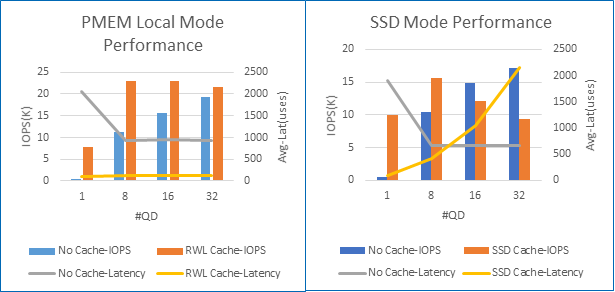
Combining the tests from the dimensions and performance shown in Figure 8, it can be found:
- When the IOPS is fixed, the cache can greatly reduce the latency and take advantage of the Intel Optane memory device.
- For pmem cache, when the io_depth is 32 and lower, the cache can greatly improve the performance. At higher depths, such 64 (not shown in figure), the pmem performance with cache or without cache is similar. This is because when the cache is full, the performance of the client cache cannot be improved due to factors such as write-back speed and network bandwidth.
- For SSD cache, at the depth of 16, the performance with and without cache has reached a turning point. This is because SSD cache consumes more when the cache is full. The better the performance of the Ceph cluster, the smaller the io_depths where the inflection point is. The Ceph cluster in this paper has very good performance, so the inflection point is closer to the low depth.
- The performance and latency of Intel Optane SSD are slightly lower than Intel Optane PMem. Even compared to the performance of the client without cache in low depth, the performance is still dazzling.
Conclusion
The persistent write log cache’s advantages are as follows:
- PWL cache can provide very high performance when the cache is not full. So, the larger the cache, the longer the duration of high performance.
- PWL cache provides a persistence feature, which is slightly lower than rbd_cache (DRAM cache). RBD cache is faster but volatile. It can’t guarantee data order and persistence.
- In a steady state when the cache is full, the performance is affected by the number of IOs in flight. For example, PWL can provide higher performance at low io_depth, but at high io_depth, such as when the number of IO is greater than 32, the performance is often worse than that in situations without cache.
References
- https://www.intel.com/content/www/us/en/developer/articles/technical/Optane-dc-persistent-memory-a-major-advance-in-memory-and-storage-architecture.html
- https://www.intel.com/content/www/us/en/developer/articles/guide/qsg-intro-to-provisioning-pmem.html
- https://docs.Ceph.com/en/latest/rbd/rbd-persistent-write-log-cache/
- https://docs.Ceph.com/en/latest/architecture/