Overview
Intel® Neural Compressor is an open source Python* library that performs model compression techniques such as quantization, pruning, and knowledge distillation across multiple deep learning frameworks including TensorFlow*, PyTorch*, and ONNX* (Open Neural Network Exchange) Runtime. The model compression techniques reduce the model size and increase the speed of deep learning inference for more efficient deployment on CPUs or GPUs.
Take a closer look at the features and benefits of the Intel Neural Compressor tool and how you can use it to supercharge your AI workflows.
Accelerating AI Inference Using Intel Neural Compressor
Intel Neural Compressor is a model-compression tool that helps speed up AI inference without sacrificing accuracy.
The Structure
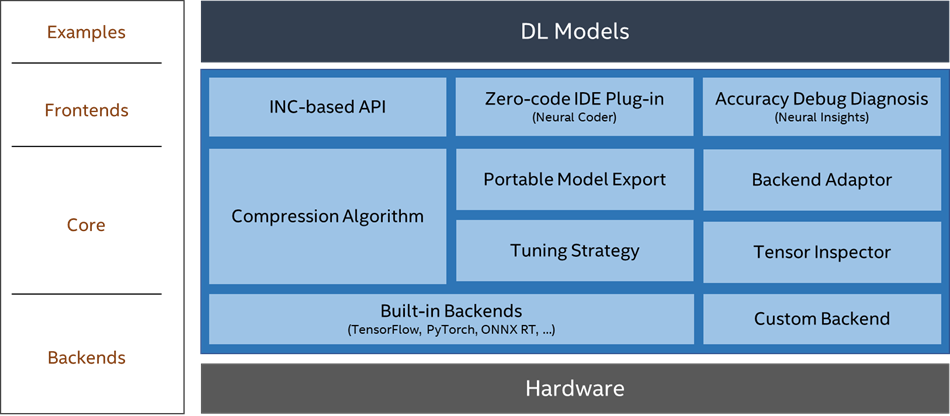
The architecture of Intel Neural Compressor helps to increase performance and speed up deployments across a variety of hardware infrastructures. The following are some of the Python-based APIs included in the tool.
Quantization
Quantization is a deep learning model optimization technique that is used to improve the speed of inference. It reduces the number of bits required by converting a set of real-valued numbers into a lower bit data representation such as int8 and int4. This helps in reducing the memory requirement, cache miss rate, and computational cost of using neural networks, and also in achieving the goal of higher inference performance. For additional information, see Quantization.
Pruning
Neural network pruning is a model compression technique that removes the least important parameters or neurons in the network. This helps in achieving minimal accuracy drop and maximal inference acceleration. Pruning has become increasingly important in reducing the computational and memory footprint that huge neural networks require as state-of-the-art model sizes have grown at an unprecedented speed. The Intel Neural Compressor Pruning API is defined under neural_compressor.training, which takes a user-defined configure object as input. For more detailed information, see Pruning (Sparsity).
Mixed Precision
The recent growth of deep learning has driven the development of more complex models that require significantly more compute and memory capabilities. Mixed precision training and inference using low-precision formats have been developed to reduce compute and bandwidth requirements. For additional information, see Mixed Precision.
Distillation
Distillation is a network compression, which transfers knowledge from a large model to a smaller one without loss of validity. As smaller models are less expensive to evaluate, they can be deployed on less powerful hardware (such as a mobile device). Knowledge distillation uses the logits (the input of softmax in the classification tasks) of a teacher and student model to minimize the difference between their predicted class distributions. For more detailed information, see Distillation.
Benefits
- Converge quickly on quantized models using automatic accuracy-driven tuning strategies.
- Prune less important parameters for large models.
- Distill knowledge from a larger model to improve the accuracy of a smaller model for deployment.
- Get started with model compression techniques with one-click analysis and code insertion.
Features
Intel Neural Compressor offers various features to supercharge your AI performance.
Model Compression Techniques
- Quantize activations and weights to int8, bfloat16, or a mixture of FP32, bfloat16, and int8 to reduce model size and to speed up inference while minimizing precision loss.
- Prune parameters that have minimal effect on accuracy to reduce the size of a model.
- Automatically tune quantization and pruning to meet accuracy goals,
- Distill knowledge from a larger model to a smaller model to improve the accuracy of the compressed model.
Automation
- Quantize with one click using the Neural Coder plug-in for JupyterLab and Microsoft Visual Studio* code, which automatically benchmarks to optimize performance.
- Achieve objectives with expected accuracy criteria using built-in strategies to automatically apply quantization techniques to operations.
- Combine multiple model compression techniques with one-shot optimization.
Interoperability
- Compress models created with PyTorch, TensorFlow, or ONNX Runtime.
- Configure model objectives and evaluation metrics without writing framework-specific code.
- Export compressed models in PyTorch, TensorFlow, or ONNX for interoperability with other frameworks.
- Validate quantized ONNX models for deployment to third-party hardware architectures via ONNX Runtime.
Get Started
Installation
Choose from one of the following methods.
- Install from Python Package Index* (PyPI)
pip install neural-compressor
- Download Intel Neural Compressor as part of the Intel® AI Analytics Toolkit (AI Kit).
Find additional installation methods and system requirements.
Code Example
The code sample demonstrates how to quantize a Keras* model with customized metric and data loader using Intel Neural Compressor. The following steps are implemented in the code sample:
- Prepare the environment. Install the following packages and make sure you are using Intel® Xeon® Scalable processor family. Intel® Developer Cloud allows to test and run workloads on latest Intel software and hardware that includes Intel Xeon processors.
pip install neural-compressor pip install tensorflow pip install intel-extension-for-tensorflow[cpu] pip install numpy
- Prepare a custom FP32 Keras model using the prepared train.py script from the repository: python train.py
- Define a dataset for MNIST. Load the Keras library MNIST dataset and divide the dataset into training set and test set, separating images and labels. For this purpose, we will create the dataset class a.
class Dataset(object): def __init__(self): (train_images, train_labels), (test_images, test_labels) = keras.datasets.fashion_mnist.load_data() self.test_images = test_images.astype(np.float32) / 255.0 self.labels = test_labels def __getitem__(self, index): return self.test_images[index], self.labels[index] def __len__(self): return len(self.test_images)
- Define a customized metric. This metric will allow us to calculate the accuracy of the model. It is needed as an evaluation metric during the quantization of our model. We will use it later.
class MyMetric(object): def __init__(self, *args): self.pred_list = [] self.label_list = [] self.samples = 0 def update(self, predict, label): self.pred_list.extend(np.argmax(predict, axis=1)) self.label_list.extend(label) self.samples += len(label) def reset(self): self.pred_list = [] self.label_list = [] self.samples = 0 def result(self): correct_num = np.sum( np.array(self.pred_list) == np.array(self.label_list)) return correct_num / self.samples
- Use the customized data loader
dataloader = DataLoader(framework='tensorflow', dataset=Dataset())
- Create configuration for quantization. We can also specify what back end should be used during quantization. For our example, we use Intel® Extension for TensorFlow*.
config = PostTrainingQuantConfig(backend='itex')
- Fit the model with data, prepared configuration, and custom metric.
q_model = fit( model='../models/saved_model', conf=config, calib_dataloader=dataloader, eval_dataloader=dataloader, eval_metric=MyMetric())
- Run inference on the quantized model.
keras_model = q_model.model predictions = keras_model.predict_on_batch(dataset.test_images)
Try out the code sample on the Intel Developer Cloud.
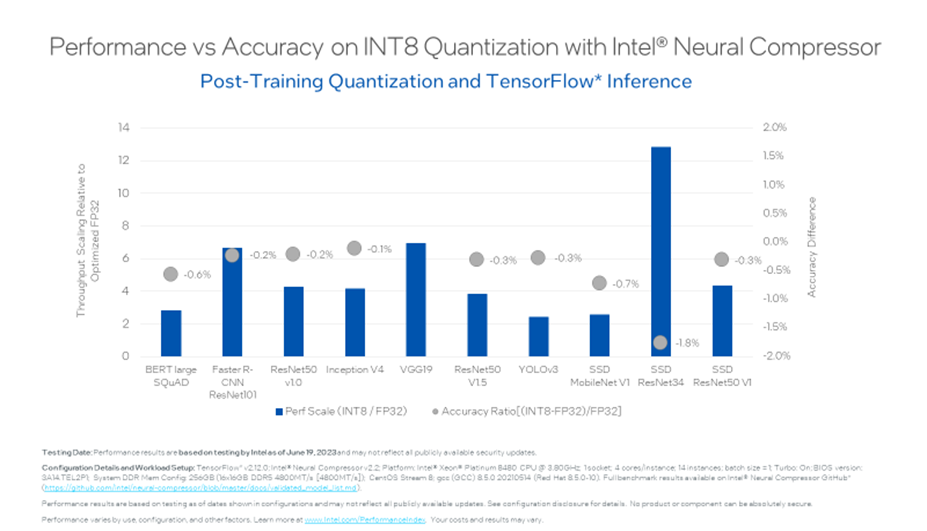
Performance Benefits
We validated and calculated performance, accuracy results for TensorFlow models using Intel Neural Compressor. Figure 1 demonstrates that throughput shows up to 12.85x improvement with Intel Neural Compressor.
What’s Next?
Get started with Intel Neural Compressor today and use it to increase the speed of deep learning inference. Learn about feature information and release downloads for the latest and previous releases of Intel Neural Compressor on GitHub* and contribute to the project.
We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow. Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
For more details about 4th generation Intel Xeon Scalable processors, see the AI Platform Overview where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.