The 12th Gen Intel® Core™ processor is a new performance hybrid architecture that combines two core types: Performance-cores or P-cores (previously code named Golden Cove) and Efficient-cores or E-cores (previously code named Gracemont). This guide for game developers provides the architecture brief and best practices for game optimization using the 12th Gen Intel Core processor performance hybrid architecture.
Sample application and source code can be found on GitHub*.
Introduction
Modern CPU architectures have decades of evolution, experience, and knowledge inside and continue to improve. CPUs have evolved from simple, single-core silicon with tens of thousands of transistors to multicore, multipurpose systems with billions of transistors. Now comes Intel’s latest CPU architecture, the 12th Gen Intel Core processor. For the first time, personal computer CPUs will include hybrid cores—a combination of Performance-cores and Efficient-cores. That mix will allow developers to take advantage of high-performance and power-efficient multicore CPUs for modern workloads, including computer games.
Developers might already be familiar with hybrid architectures, including high-performance Performance-cores (P-cores), and power-efficient Efficient-cores (E-cores) in the mobile phone industry, where such products have been available for a number of years. Now those benefits will become available for desktop computers and notebooks, but with an important difference: the E-cores also supplement the P-cores to provide significantly higher multithreaded throughput working in tandem to provide the best overall performance in a given power envelope.
This significant architecture change means developers will need to understand the specifics, incorporate new design goals, and make key decisions around best practices to create efficient software that utilizes all available capabilities and features. Properly detecting CPU topology is critical for obtaining optimal performance and compatibility for applications running on hybrid processors. Prior assumptions about hyperthreading between physical and logical processors may no longer hold true, and, if not resolved, could cause serious system issues. Developers should fully enumerate the available logical processors on a system to optimize for power and performance.
This document provides information on architecture, programming paradigm, detection, optimization strategies, and examples.
Architecture Overview
This section includes information about the performance hybrid architecture used in select 12th Gen Intel Core processors.
Topology
The 12th Gen Intel Core processor’s performance hybrid architecture combines high-performance P-cores with highly efficient E-cores in one silicon chip. Topologically, each P-core with L2$ is connected to L3$ (LLC). Each E-core module has 4 E-cores that share L2$. The E-core clusters connect to a shared L3$ with the P-cores. All cores are exposed to the operating system as individual Logical Processors.

Figure 1. Performance-cores and Efficient-cores feature separate L1 and L2 caches so they can run largely independently of each other. The L3 (LLC) cache is shared.
Instruction Sets
To simplify the programming model and provide flexibility, the following design decisions were made on the instruction set level:
● All core types have the same instruction set.
● AVX512 is disabled on P-cores and not available on E-cores.
Table 1. Specific P-core features were added as extensions to both cores.
| P-core Feature | 12th Gen Intel Core processors |
|---|---|
| AVX512 | Disabled in P-cores and N/A in E-cores |
| TSX | Disabled in P-cores and E-cores |
| AVX-VNNI(Vector Neural Network Instructions) | Added through symmetric ISA |
| vAES (Advanced Encryption Standard) | Present through symmetric ISA (Also present in Ice Lake and Tiger Lake) |
| vCLMUL(Carry-less Multiplication) | Added through symmetric ISA |
| UMWAIT/TPAUSE | Added through symmetric ISA |
Intel® Thread Director and Operating System Vendor (OSV) Optimizations for the Performance Hybrid Architecture
Intel® Thread Director is built on top of Lakefield Hardware Guided Scheduling (HGS) support. It provides Instruction Set Architecture (ISA) awareness to the operating system to indicate performance differences (and power-efficient changes) between the Performance-cores and Efficient-cores. This awareness allows Intel Thread Director to schedule threads on the core which best fit the task.

Figure 2. Scheduler interactions between hardware, the Operating System (OS) scheduler, and the Task Scheduler (TS) counter
Notes
● Per Class ID and Perf Capabilities provide relative performance levels of LP Performance-cores vs. Efficient-cores. Higher values here indicate higher performance.
● Per Class ID, EE Capability provides the relative energy efficiency level of an LP. Higher values here indicate higher EE to be used for threads with energy efficiency needs.
● The OS can choose between EE and performance, depending on parameters such as power policy, battery slider, etc.
Various classes here indicate performance differences between the cores. For example, Class 1 indicates ISA such as AVX2-FP32 where P-cores offer higher performance than E-cores, while Class 2 indicates higher VNNI performance difference. Intel also introduced a class to track waits, such as UMWAIT/TPAUSE/PAUSE, etc., to prevent Performance-cores from sitting idle while real work goes to the Efficient-cores.
Architecture Implications
From a programming perspective, all cores appear functionally identical, differing only in performance and efficiency. The OS coupled with hardware guidance can do an intelligent job of distributing threads, but there are still a few areas you should be aware of when writing code for a hybrid architecture:
- CPUID, by design, returns different values depending on the core it is executed on. On hybrid cores more of the CPUID leaves will have data that varies, meaning that if cores are used to generate a hash for encryption, or to generate a unique seed for random number generation, you should be careful to only use leaves that contain data that doesn’t change between core types.
- Bitwise operations (AND, OR, XOR, NOT, rotate) do not have a notion of signed overflow, so the defined value varies on different processor architectures; some clear the bit unconditionally, others leave it unchanged, and still others set it to an undefined value. Shifts and multiplies do permit a well-defined value, but it is not consistently implemented. For example, the x86 instruction set only defines the overflow flag for multiplies and 1-bit shifts. Other than that, the single-bit shift behavior is undefined and can vary between Performance-cores and Efficient-cores.
Stock-Keeping Units (SKUs)
Multiple desktop and mobile SKUs will be available with various combinations of cores and execution units (EUs).

Figure 3. Laptop and Desktop SKUs for 12th Gen Intel Core processors release
Mobile SKUs will feature up to 6 P-cores and 8 E-cores. All mobile SKUs will include E-cores. Desktop SKUs will feature up to 8 P-cores and up to 8 E-cores. Specific desktop SKUs will feature only P-cores.
CPU Topology Detection
Properly detecting CPU topology is critical for obtaining optimal performance and compatibility for applications running on hybrid processors such as 12th Gen Intel Core processors. Previously a developer could count the total number of physical processors on a system, and it was easy to assume parity for performance and power utilization. Some assumptions could be made for hyperthreaded CPUs, for example, doubling the number of physical processors to get the number of logical processors. In a hybrid CPU, the old assumptions no longer hold true, and developers must fully enumerate the available logical processors on a system to determine the power and performance characteristics of each logical processor.
There are several methods you can use to determine your target CPU’s topology. There is significant overlap between the different methodologies; the general guidance is to use the least complex solution that obtains the information you require and to use a consistent method across the codebase. For cross-platform support, the CPUID intrinsic can provide some topological information, while the Windows* API provides several methods, such as GetLogicalProcessorInformation and GetSystemCPUSetInformation, that allow you to fully enumerate logical processors.
In addition, for cross-platform support, the CPUID intrinsic can provide some topological information, while the CPUID intrinsic and the GetLogicalProcessorInformation functions can be used together to provide more detailed information about a target system’s CPU.
GetLogicalProcessorInformation (GLPI / GLPIEX)
The Windows API offers several methods for determining logical processor topology; these include GetLogicalProcessorInformation (GLPI) and GetLogicalProcessorInformationEx (GLPIEX). With GLPI/GLPIEX you can determine the topological relationships between logical processors, caches, non-uniform memory access (NUMA) nodes, processor groups, and packages. This information helps determine which logical processors share the same resources.
For example, if the system contains a physical core and a simultaneous multithreading (SMT) core on an Performance-core (or P-core) processor, GLPI returns a SYSTEM_LOGICAL_PROCESSOR_INFORMATION structure which contains a Relationship field and ProcessorMask field for each node.
The Relationship field from SYSTEM_LOGICAL_PROCESSOR_INFORMATION will hold a value of RelationCache (2) or RelationProcessorCore (0) and there are additional values for RelationNumaNode (1) and RelationProcessorPackage (3). When the Relationship field is set to RelationProcessorCore (0) the Processor Core field of the SYSTEM_LOGICAL_PROCESSOR_INFORMATION struct will be populated with processor Flags, while a RelationCache (2) Relationship will populate the Cache field with a CACHE_DESCRIPTOR struct containing cache characteristics.
The ProcessorMask field is a 64-bit mask for each logical processor and cache. The ProcessorMask field only represents processors in a single Group. For CPUs with more than 64 logical processors, you should use GLPIEX to obtain Group Masks for each logical processor and cache. Each bit in the mask represents a single logical processor and at least one bit will always be set. You can compare the processor masks using bit manipulation to determine the relationships between each mask. For example, to determine if a core mask is associated with a cache mask you can use the “&” operator to compare the processor masks.
The following pseudo-code demonstrates how to compare bit masks in C++.
GLPI only supports 64 logical processors. However, you can use SetThreadGroupAffinity to find the 64 active processors for a specific group of CPUs with more than 64 logical processors. If the target system has more than 64 logical processors, you can use GLPIEX or GetSystemCPUSetInformation instead.
GetLogicalProcessorInformationEx (GLPIEX) returns a SYSTEM_LOGICAL_PROCESSOR_INFORMATION_EX struct for each active processor, cache, group, NUMA node, and package. The Relationship field of the struct will report an additional RelationGroup (4) for Group nodes. When the Relationship is set to RelationGroup (4) the SYSTEM_LOGICAL_PROCESSOR_INFORMATION_EX will populate the Group field with a GROUP_RELATIONSHIP structure.
Unlike for GLPI, the SYSTEM_LOGICAL_PROCESSOR_INFORMATION_EX structures returned from GLPIEX will not return a ProcessorMask. Instead, they will contain a reference to either a PROCESSOR_RELATIONSHIP structure, a NUMA_NODE_RELATIONSHIP structure, a CACHE_RELATIONSHIP structure, or a GROUP_RELATIONSHIP structure. Each of the above structures will contain a GroupMask of type GROUP_AFFINITY. GroupMask contains a group ID and a KAFFINITY mask which is a 64-bit bit-field like the ProcessorMask from GLPI.
On a hybrid CPU when the Relationship returned from GLPIEX is of RelationProcessorCore (0) the PROCESSOR_RELATIONSHIP structure will return an EfficiencyClass value. This value represents the power-to-performance ratio of a logical processor. Cores with a higher Efficiency Class value in the EfficiencyClass field have higher performance but lower power efficiency. You can use the EfficiencyClass value returned from GLPIEX to group logical processors into homogeneous CPU clusters. This can be useful when you need to schedule tasks with specific power or performance requirements.
GetSystemCPUSetInformation
There are several advantages to using GetSystemCPUSetInformation. First, it can query more than 64 logical processors per CPU, and second, it is group-aware and will report group information. It also breaks out additional flags not reported by GLPIEX.
GetSystemCPUSetInformation returns a SYSTEM_CPU_SET_INFORMATION array which contains data for each active logical processor on the target CPU. You can iterate through each logical processor to obtain the CPU set ID, Group, LogicalProcessorIndex, EfficiencyClass, and SchedulingClass, plus Allocation and Parking flags.
Like GLPIEX, GetSystemCPUSetInformation also returns an EfficiencyClass value for each logical processor. The EfficiencyClass represents the ratio of performance to power, with higher values representing higher processor performance and lower power efficiency. You can use the EfficiencyClass to sort logical processors into groups.
GetSystemCPUSetInformation is similar to GLPI and GLPIEX. However, it will only return processor information, and will not report cache topology, other than a last-level cache index. If you need additional topological information about a CPU, you can combine GetSystemCPUSetInformation with GLPI or GLPIEX.
CPUID Intrinsic
As of March 2020, the Intel® Architecture Instruction Set Extensions And Future Features Programming Reference provides the details necessary for using the CPUID intrinsic to determine hybrid topology on a target system.
There are two new flags defined:
- The Hybrid Flag can be obtained by calling CPUID with the value “07H” in the EAX register and reading the 15th bit of the EDX register.
- The Core Type Flag can be obtained by calling CPUID on each logical processor with a value of “1AH” in the EAX register; this will return each processor’s type in bits 24-31 of the EAX register.
You can use the core type to determine if a logical processor is either an Efficient-core (E-core, also known as “Gracemont”) (20H), or a Performance-core (P-core, also known as “Golden Cove”) (40H). However, the return value for Core Type does not differentiate between physical and SMT cores for Intel Core processor. Both will be represented as Intel Core (40H). E-core processors are not hyperthreaded and do not require special detection of logical cores per physical processor. Alternatively, you can use the “efficiency class” returned by GetSystemCpuSetInformation to differentiate between Physical Core, SMT Core, and E-core processors.
Table 2. CPUID Functions for the Hybrid flag and Core Type
| CPUID Hybrid Function Table | ||||||
|---|---|---|---|---|---|---|
| Name | Function (EAX) | Leaf (ECX) | Register | BitStart | BitEnd | Comment |
| Hybrid Flag | 07H | 0 | EDX | 15 | 15 | If 1, the processor is identified as a hybrid part. Additionally, on hybrid parts (CPUID.07H.0H:EDX[15]=1), software must consult the native model ID and core type from the Hybrid Information Enumeration Leaf. |
| Core Type | 1AH | 0 | EAX | 24 | 31 | Hybrid Information Sub-leaf (EAX = 1AH, ECX = 0) EAX Bits 31-24: Core type 10H: Reserved 20H: Intel Atom® 30H: Reserved 40H: Intel® Core™ |
There are a few caveats that you should consider when using CPUID to detect hybrid topology in your application.
- The Hybrid Flag and Core Type will not be supported for legacy homogeneous CPUs. Applications running in Application Compatibility Mode in Windows may not report the correct values due to the operating system not intercepting the CPUID intrinsic call. CPUID will return results as signed integers, so you should cast to unsigned integers or use std::bitset<32> for reading the 32-bit values returned in the CPUID registers.
- When checking Core Type you should momentarily “pin” the target logical processor to get the specific Core Type of the pinned logical processor. For these reasons, it may be necessary to employ additional methods of topology detection such as GetLogicalProcessorInformationEx or GetSystemCpuSetInformation.
Binning Logical Processors
When detecting CPU topology, developers may want to create groups of logical processors that share an EfficiencyClass, or another characteristic—such as a shared cache. Grouping your logical processors effectively can help you segment work more easily when a target architecture is desired. The method chosen for grouping processors will depend on the method of topology detection you have selected for your application, as well as the data structures used to store your logical processor topology.
If your strategy for topology detection uses CPUID you can use the Core Type value returned from the Hybrid Information Sub-leaf. Using Core Type creates a hard dependency on specific types of processors such as P-cores or E-cores, which makes cross-platform support more complex. For this reason, the use of EfficiencyClass is recommended for the most fine-grained grouping of logical processors.
If you use GLPI you can group ProcessorMasks into your own custom 64-bit masks using bit manipulation. However, GLPI does not return an EfficiencyClass, and you may need to pair GLPI with CPUID or GLPIEX and correlate the Core Type or EfficiencyClass with the processors from GLPI. The use of GLPIEX is preferred over GLPI for this reason.
The best strategy for grouping logical processors is using EfficiencyClass, which can be obtained by using GLPIEX or GetSystemCPUSetInformation. GLPIEX will require the use of GroupMasks, which requires bit manipulation for binning into custom masks for logical clusters. GetSystemCPUSetInformation will give an unsigned integer identifier to track for each logical processor. Create a vector or array to store the list of CPU set IDs. For a quick way of creating logical clusters, use an std::map grouped by EfficiencyClass as the first template parameter, and an std::vector of ULONGs as the second template parameter.
Hybrid Operating System (OS) Detection
With the release of Windows 11, you can automatically have your threads scheduled by the OS using hardware hints from Intel Thread Director. If your strategy is to allow the OS and Intel Thread Director to do the heavy lifting for your thread scheduling, you will need to detect which version of Windows your application is running on. Without the updates for Windows 11, Intel Thread Director will not be supported. Some Intel Thread Director features will be backported, but it is essential to check for a minimum supported version of Windows. You can use VerifyVersionInfo API, which will allow you to include Service Pack Minor and Build Number in your version specification.
Thread Scheduling
To get the highest optimized power and performance utilization on a processor that supports a hybrid architecture, you need to understand two things: how the OS schedules individual threads and the APIs available to provide additional hints or to take full control if required. For the Windows OS, the goals of the scheduler on 12th Gen Intel Core processors are as follows:
- Use the most performant cores first for single-thread and multi-thread performance.
- Ensure spill-over multithreaded work uses lesser performant cores for MT-performance.
- Use SMT siblings last to avoid any contention that could impact performance.
- Use Intel Thread Director to leverage performance differences in threads, and pick the right core for the right thread—at the same time minimizing thread context switches.
- Leverage the most efficient cores to opportunistically save power.
- Ensure that background work occurs on efficient cores to reduce the impact on MT performance.
- Provide APIs to opportunistically characterize threads to better leverage 12th Gen Intel Core Processors for performance and efficiency differences.
It is important to understand that the OS and hardware are working at a platform level to maximize performance. Selecting the appropriate logical processor to perform a task could vary depending on the environment. For example, devices running on limited power may benefit by prioritizing a certain class of processor or even parking some processors to boost available power.
Due to the complexity of the system, you should note a subtle difference from previous thread-detection solutions. Instead of taking the bottom-up approach of trying to find where a thread should be scheduled, it is more effective on hybrid architectures to take a top-down approach and provide the OS with enough contextual information that it knows which gaming threads are time-sensitive or performance-critical.
Thread Priority
Thread priority has been used historically by game developers for two main purposes:
- A high thread priority is used to denote interrupt-style work, for example where a thread servicing audio has to run frequently and any thread starvation would lead to audio dropout. In this case, the work itself is only a small proportion of the over-work being done in a game.
- Another area where thread priority is used is to denote threads critical to the game’s frame-rate, such as the rendering thread. Unlike interrupt-style work, these are potentially very long-running, and the aim of setting a high priority is to ensure that if they do get context-switched out due to over-subscription, they quickly get resources reassigned.
On hybrid cores, thread priority takes on an extra meaning. Threads marked as high priority will naturally be assigned to higher performance cores, but this is a secondary consideration. The primary use is still to denote the frequency at which the OS schedules work on the thread, so time-critical work is serviced as quickly as possible.
This has the potential to lead to suboptimal behavior if a gaming engine has been built around the assumption that thread priority can be used to denote the importance of a thread’s work to the player’s visual experience. The following case study highlights some challenges to consider:
- A game creates two thread pools such that each has the same number of threads as logical processors.
- Each thread pool has a different priority, one marked high, one marked normal. All background tasks such as file input/output (I/O) and procedural content generation go to the lower-priority thread group, while all rendering work goes on the high-priority threads.
- On a non-hybrid system, any time a high-priority task is scheduled its thread will wake up and the OS will force one of the low-priority threads to be suspended.
- On a hybrid system, the same suspension will happen. However, if there are more low-priority threads than physical performance cores, but fewer active low-priority threads than the total logical processors, the OS will potentially wake up one of the Efficient-cores to do the work.
- Whether or not the OS decides to switch a low-priority thread to an Efficient-core so that a high-priority thread can use the performance core will come down to internal heuristics, including the cost of context switching and expected thread run time.
As illustrated above, current assumptions that all cores are equal, and priority alone is enough to ensure critical work is always done ahead of background tasks, may not be enough on a hybrid system.
Thread Affinity
To get the most optimized power- and performance-utilization on a processor that supports a hybrid architecture, you must consider where your threads are being executed, as discussed above. For instance, when working with a critical path thread, you may prefer it to prioritize execution on the logical Performance-cores. However, it may be more optimal to run background worker threads on the Efficient-cores. The API references in the next section lists many of the functions available, ranging from those providing OS level guidance through weak affinity hits, such as SetThreadIdealProcessor() and SetThreadPriority(), through stronger control like SetThreadInformation() and SetThreadSelectedCPUSets(), to the strongest control of affinity using SetThreadAffinityMask().
In general, the guidance is to avoid hard affinities, as these are a contract between the application and the OS. Using hard affinities prevents potential platform optimizations, and forces the OS to ignore any advice it receives from the Intel Thread Director. Hard affinities can be prone to unforeseen issues, and you should check to see if middleware is using hard thread affinities, as they can directly impact the application’s access to the underlying hardware. The issues with hard affinities are particularly relevant on systems with more Efficient-cores than Performance-cores, such as low-power devices, as hard affinities limit the OS’s ability to schedule optimally.
Determining the right affinity level for your application is critical to meet power and performance requirements. If you prefer letting the operating system and Intel Thread Director do most of the heavy lifting for your thread scheduling, you may prefer a “weak” affinity strategy. You can utilize a “stronger” affinity strategy for maximum control over thread scheduling—but use caution as the application will end up running of a wide range of hardware with differing characteristics. Careful design of the underlying threading algorithms to allow for dynamic load balancing across threads and varying hardware performance characteristics is preferable to trying to try to control the OS behavior from within the application.
When choosing your affinity strategy, it is important to consider the frequency of thread context switching and cache flushing that may be incurred by changing a thread’s affinity at runtime. Many of the strong affinity API calls, such as SetThreadAffinityMask, may immediately be context switched if the thread is not currently residing on a processor specified in the affinity mask. Weaker affinity functions, such as SetThreadPriority, may not immediately force a context switch, but offer fewer guarantees about which clusters or processors your threads are executing on. Whatever strategy you choose, we recommend setting up your thread affinities at startup, or at thread initialization. Avoid setting thread affinities multiple times per frame, and keep context switching during a frame as infrequent as possible.
SetThreadIdealProcessor
SetThreadIdealProcessor() allows you to weakly affinitize a thread to a single processor. However, the system does not guarantee that your thread will be scheduled on its ideal processor, only that it will schedule on the ideal processor whenever possible. This means your thread will be more likely to be scheduled on an ideal processor more frequently but, if performance is critical, choosing a stronger affinitization strategy may be necessary. Alternatively, you can use the SetThreadIdealProcessorEx() function to set an ideal processor as well as retrieve the previously assigned ideal processor for a thread. Avoid using SetThreadIdealProcessor in most scenarios for high-performance computing.
SetThreadPriority
SetThreadPriority() is one of the “weaker” ways to affinitize threads. It does not guarantee that your thread will be scheduled on a specific cluster or processor. It does allow you to control how frequently your thread is scheduled by the OS, and how large a time-slice it will be assigned when executing. By default, all threads are assigned THREAD_PRIORITY_NORMAL when first created. You can use the GetThreadPriority() function to determine the current priority of any thread in your application.
If you need to create background workers, you can use priorities THREAD_MODE_BACKGROUND_BEGIN and THREAD_MODE_BACKGROUND_END to transition your threads in and out of background mode. Alternatively, critical path threads can be set with a higher priority such as THREAD_PRIORITY_ABOVE_NORMAL, THREAD_PRIORITY_HIGHEST, or THREAD_PRIORITY_TIME_CRITICAL. Setting a thread priority extremely high may cause your thread to consume all available resources on a CPU, so be sure your priority values are balanced to reduce CPU overutilization. Additionally, the REALTIME_PRIORITY_CLASS can prevent disk caches from flushing, cause the keyboard or mouse input to stop responding, and so on. Only set your thread priority to the highest settings when you can ensure there will be no detrimental side effects.
The operating system may at times boost the priority when a thread is assigned a dynamic priority class. If you need to control thread priority boosting, you can use the SetThreadPriorityBoost() function to enable or disable priority boost as needed by your application. Use GetThreadPriorityBoost() to determine the current status of priority boosting for a given thread at runtime.
SetThreadInformation
SetThreadInformation() will allow you to control a thread’s power throttling and/or memory priority. It falls into the class of “weak affinity” API functions but has several modes of operation that control how the operating system handles your threads. First, SetThreadInformation can control power throttling for a given thread which allows you to control the power-to-performance ratio of a thread. There are three possible modes for power throttling, Enabled, Disabled, and Automatic. If power throttling is enabled, the OS increases power efficiency by capping the performance of a logical processor and may selectively choose a more power-efficient logical processor such as an Efficient-core. To enable power throttling you need to create a THREAD_POWER_THROTTLING_STATE structure and assign a ControlMask and StateMask of THREAD_POWER_THROTTLING_EXECUTION_SPEED.
Important Note If you are writing your own scheduler, you are likely to be focused on totally controlling where threads are run and ensuring they run at top speed. If you need higher performance and are less concerned about power efficiency, you can choose to disable power throttling. To disable power throttling set the ControlMask to THREAD_POWER_THROTTLING_EXECUTION_SPEED and set the StateMask to zero.
By default, the system will choose its own strategy for determining power throttling, unless you explicitly choose to enable or disable power throttling. To return a thread to the default “automatic” power throttling state, you can set both the ControlMask and StateMask to zero.
SetThreadInformation can control memory priority for a given thread. Memory priority allows you to control how long the operating system keeps pages in the working set before trimming. Lower-priority pages will be trimmed before higher-priority pages. Several situations may benefit from lower memory priority, such as background worker threads that access files or data infrequently, texture streaming, or threads that read settings or game files from the disk.
Memory Priority is another area where developers may want to completely control their threading logic. For example, AI systems tend to utilize considerable bandwidth but often dump the cache early, while threads that work through vertices may hold the thread for longer times. Fine-tuning these operations can greatly enhance gameplay.
SetThreadSelectedCPUSets
CPU Sets provide APIs to declare application thread affinity in a “soft” manner that is compatible with OS power management (unlike the ThreadAffinityMask APIs). Additionally, the API provides applications with the ability to reaffinitize all background threads in the process to a subset of processors using the Process Default mechanism to avoid interference from OS threads within the process. SetThreadSelectedCPUSets() takes a list or array of CPU ID numbers stored as unsigned longs. The CPU ID for each logical processor can be obtained by calling GetSystemCpuSetInformation(). SetThreadSelectedCPUSets can exceed the 64 logical processor limits imposed by SetThreadAffinityMask.
Creating logical clusters works similarly to SetThreadAffinityMask, except, instead of storing 64-bit masks, you store a CPU ID array or vector that represents the logical clusters your application is targeting.
SetThreadAffinityMask
SetThreadAffinityMask() is in the “strong” affinity class of Windows API functions. It takes a 64-bit mask to control which of up to 64 logical processors a given thread can execute on. You can use a GroupMask to exceed 64 logical processors. However, other options, such as CPU Sets, would be preferable. SetThreadAffinityMask is essentially a contract with the operating system, and will guarantee that your threads execute only on the logical processors supplied in the bitmask. By reducing the number of logical processors that your thread can execute on, you may be reducing the overall processor time of the thread. Be cautious when using strong affinities with SetThreadAffinityMask, unless you want full control over thread scheduling. Improper use of SetThreadAffinityMask may result in poor performance since the operating system will be more constrained in how it schedules threads and it may be in conflict with the OS scheduler.
You can use SetThreadAffinityMask to segment your threading system into logical processor clusters. Using SetThreadAffinityMask you may choose to create a thread scheduler with two logical thread-pools that consist of a logical P-core cluster, and a logical E-core cluster. The operating system will still schedule within the specified cluster mask, but will not benefit from Intel Thread Director power or performance optimizations. It can also be used to pin a thread to a single processor. Pinning is not ideal, however, and should only be used in extremely rare cases, such as executing an atomic operation or reading the CPUID intrinsic for a logical processor. Avoid setting affinity masks at runtime since they can force an immediate context switch. If possible, set your affinity mask only during initialization time. If you do need to swap affinity masks at runtime, try to do it as infrequently as possible to reduce context switching.
Logical processor clusters do not need to be limited to a single type of processor. You may choose to create several affinity masks for different purposes. These may include cache-mapped masks, system/process masks, cluster masks, and novel masks for specialized use-cases. The figure below shows a typical bit mask-map with affinity masks.

Figure 4. Bit mask-map for cores and caches
Logical Topologies
When designing your threading system for processors that support a hybrid architecture, you should consider what types of logical topologies to divide your logical processor into. The most obvious choice for the 12th Gen Intel Core processor is to create a split topology that divides the P-core processors from the E-core processors. However, there are other logical topologies to consider, based on the needs for your specific application. Alternative options may include P-core processors only, E-core processors only, or you may choose to cluster P-core and E-core processors together in a single logical cluster. Furthermore, you can extend the split topology into three topologies if you need to differentiate between P-core, E-core, or SMT cores. In rare cases, you can also create novel logical topologies for specialized purposes.
If cache coherency is essential for your application, you could choose to create logical clusters based on cache topology, instead of processor EfficiencyClass. This design pattern is known as “cache mapping”, and can help reduce the cost of cache coherence by grouping processors according to commonly associated caches. With the 12th Gen Intel Core processor, the logical E-core processor’s Level 2 Cache is shared in banks of four logical processors. Clustering around L2 caches for E-core processors may offer improved L2 cache coherence over LLC. If you need to share the cache between logical P-core processors and logical E-core processors, you will be limited to last-level cache coherence.
When creating threads that target logical clusters, consider mixing weak and strong affinities, depending on the use-case of the thread. For instance, a background thread may benefit from a lower memory priority and power throttling and may prefer to run on E-core processors. Alternatively, a real-time thread may need a real-time thread priority, higher memory priority, and power throttling disabled, while preferring P-core processors. You can create a simple affinity table, such as the example below, to help categorize your threads when designing your application.
Table 3. Sample thread affinity table.
| Thread | SetThreadPriority | SetThreadInformation (Memory Priority) |
SetThreadInformation (Power Throttling) |
SetThreadSelectedCPUSets |
|---|---|---|---|---|
| Main Thread | THREAD_PRIORITY_NORMAL | MEMORY_PRIORITY_NORMAL | Disabled | Core Threadpool |
| Audio Thread | THREAD_PRIORITY_BELOW_NORMAL | MEMORY_PRIORITY_BELOW_NORMAL | Auto | Any Threadpool |
| Render Thread | THREAD_PRIORITY_TIME_CRITICAL | MEMORY_PRIORITY_NORMAL | Disabled | Core Threadpool |
| Worker Thread | THREAD_PRIORITY_NORMAL | MEMORY_PRIORITY_MEDIUM | Auto | Any Threadpool |
| Background Thread | THREAD_MODE_BACKGROUND_BEGIN | MEMORY_PRIORITY_LOW | Enabled | E-core Threadpool |
Performance Optimizations
Since the 12th Gen Intel Core processors represent a significant change in CPU architecture, you may need to fine-tune applications to take full advantage of both core types. That will be particularly important for multithreading applications with complex job managers, and multiple-use middleware. Elsewhere, the OS Scheduler is optimized to account for the 12th Gen Intel Core processor performance hybrid architecture, and the impact may be minimal.
Analysis of games on hybrid architectures has shown the majority of games perform well, with older, or less demanding, games favoring the Performance-cores. Games that were already built to heavily utilize multithreading, and that can scale to double-digit core counts, were found to benefit from hybrid architecture due to better throughput. However, there are inevitable performance inversions, attributed to either poor multithreading game architectures, poor OS scheduling, or increased threading overhead. Such issues were addressed by introducing optimizations using the Intel Thread Director technology, HW hints to the OS scheduler (in collaboration with Microsoft*), and their respective threading libraries. Make sure you keep your development environment current, with the operating system, tools, and libraries all updated regularly, to achieve the best performance on 12th Gen Intel Core processors and other hybrid architectures.
General Hybrid Enabling Guidance
The performance hybrid architecture present on 12th Gen Intel Core processors offers unique opportunities and challenges for developers during the software enabling process. Below are some guidelines and opportunities for maximizing performance on the new CPU family.
Lack of Scalability with Increased Core Count
Testing has revealed that some legacy software can show a performance inversion as you increase core counts. This is not an issue specific to 12th Gen Intel Core processors, but more of a scalability challenge. As the number of threads increases, so does the overhead of managing them. If there isn’t enough work for the threading system, the overheads can become greater than any benefit derived from increased work distribution. Developers shouldn’t naively scale to the available core count on the system, but instead scale to the point where benefits decrease below a threshold decided by the programmer. This allows the OS more opportunities to manage hardware resources, parking unused cores and diverting power to the parts of the system that need it, potentially increasing frequency. In the future, applications could create their own feedback systems within the game’s threading code and adjust how wide the threading goes depending on whether the work is affecting timing on the game’s critical path. As PCs start to have a wider range of system configurations, core counts can scale upwards according to a game’s maximum hardware requirements. Similarly, checking minimum system requirements will become increasingly important.
Targeting Specific Instruction Set Architectures (ISAs)
This is typically not recommended. Even though there is a performance difference among various ISAs, Intel Thread Director can provide the OS with the current run-time status of each core, and so let the OS choose the right cores at given power/thermal constraints to run that ISA at its most efficient.
Dynamic Balancing/Work Stealing
If you are creating your own thread pools, you should optimize for the hybrid nature of CPUs in the 12th Gen Intel Core processor timeframe, where some cores might finish the task faster than others. In such cases, dynamic load balancing and work stealing can bring further gains, since the two core types will have some performance differences.
Replacing Active Spins with UMWAIT or TPAUSE
Active spins are present in many client applications (across both Creator/Productivity and Gaming segments). From both power and performance considerations, developers should replace these active spins with MWAIT (UMWAIT) or Timed Pause (TPAUSE) instructions, whose usage is described in Intel’s ISA Software Developer Manual (SDM).
The instructions UMWAIT and TPAUSE cause the core to enter a lower-power active C-State (C0.1 or C0.2), which saves power and doesn’t require a spin on the client (for example, a pause instruction consumes 140 core cycles on the client). UMWAIT/TPAUSE and PAUSE instructions will increase C0.1 or C0.2 cycles, which will be detected by Intel Thread Director.
The spin-time increases as cores are scaled with the hybrid architecture, due to the threading libraries spinning on parallel_for and other parallel constructs. The active spins tend to occur in the following situations:
- When waiting for a hardware resource
- When one thread is waiting for another, in the Producer/Consumer model
- When backing off a lock due to contention
- When the system detects a thread imbalance in thread pool after the thread pools have finished working
Thread pools that are created with parallelism, such as closing out a parallel_for, will often spin anticipating another parallel construct.
Hybrid Architecture Enabling Implications For Games
Games are a critical segment and no performance loss is acceptable. While many games are GPU-bound, top AAA titles operating on high-end discrete GPUs are often CPU-bound. The games will generally be CPU-bound on one or two critical threads, and they will feature a tasking system enumerated to either the logical or physical processor counts. As it is difficult to remove work from the critical game threads, Amdahl’s Law often prevents core-count scaling beyond six to eight cores, but this does not mean that games do not use more than six to eight threads/cores.
Analysis has shown performance inversions attributed to multithreading issues, OS scheduling, or increased threading overhead.
Critical Path
The extended critical path is defined as all of the executed code segments of a program that, when reduced with a small ∑, will reduce the completion time on a given number of processors.

Figure 5. Critical-path illustration showing four cores. P-cores are colored blue, and E-cores are colored gray. The critical path is in yellow, while the non-critical tasks are in dark blue.
Shared resources on a physical core affect the IPC of Logical Processors (LP). Function Call time will be affected by the Core type it is scheduled on. Long-tail tasks in a thread pool will degrade performance if scheduled on an Efficient-core:
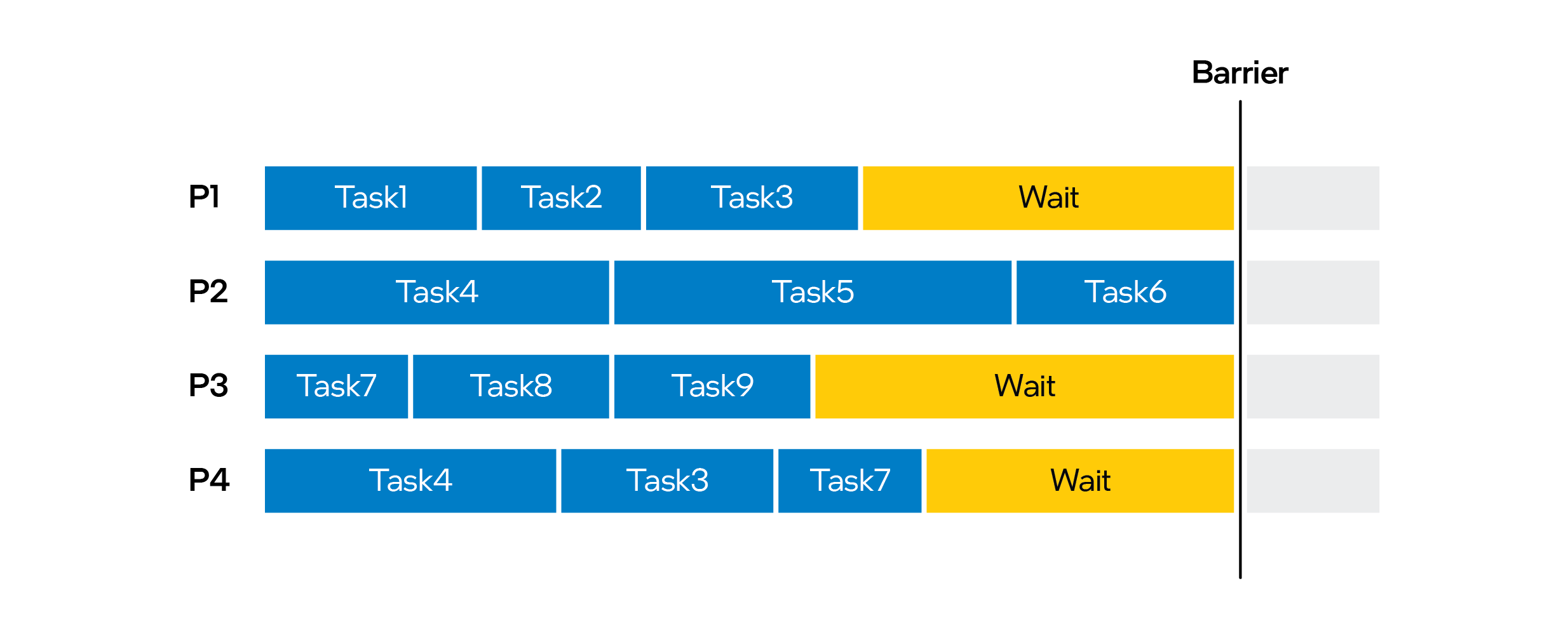
Figure 6. Long-tail tasks with wait times degrade threading performance
Choosing an Optimization Strategy—Desktop
Consider the following scenarios when developing an optimization strategy for desktop systems.
No Optimizations
Based on Intel Thread Director feedback, the OS Scheduler intelligently schedules threads, and workload is distributed dynamically. This removes overhead on the developer side to handle scheduling tasks in software. If no optimization is done for the application, Intel Thread Director will try to distribute workloads based on its algorithm. This distribution typically delivers increased performance, but in some cases, it is possible that some non-critical tasks may get assigned to Performance-cores, and some critical-path tasks may get assigned to Efficient-cores. That is especially possible if the application uses multiple middleware components with their own threading created by developers who are not aware of possible conflicts. Developers should review the application-threading algorithm, and choose one of the following scenarios.
“Good” Scenario
The “good” scenario includes minimum steps for creating hybrid awareness for the applications and does not require a complex rewrite of the tasking system.
- The primary workload should target the Performance-cores:
○ Enumerate the tasking system based on Performance-core count or a maximum number of threads required for the workload.
○ Ensure that the task system can load-balance.
- Use thread priorities/quality of service (QoS) APIs to target the right work to the right core:
○ Set the priority for Game/Render threads higher than normal to target Performance cores.
○ Set the tasking system threads at normal priority to trend to Performance-cores.
○ Set the background threads at lower than normal priority, if required, to target the Efficient-cores.
“Best” Scenario
To ensure the best performance, and build a fully hybrid-aware tasking system, it might be preferable to create two thread pools:
- Primary thread pool targeting Performance-cores. It will execute jobs that are required or preferred to be executed only on Performance-cores.
- Secondary thread pool targeting Efficient-cores. This pool will execute jobs that are a good fit for Efficient cores, such as:
○ Shader Compilation
○ Audio Mixing
○ Asset Streaming
○ Decompression
○ Any other non-critical work
To further optimize the system and increase load balance and utilizations, you should implement the task-stealing algorithm to “offload” tasks from the primary to the secondary thread-pool if Performance-cores are overloaded, and there is capacity on Efficient-cores. That is particularly important on Notebook SKUs, where the number of Performance-cores is further limited.
Choosing an Optimization Strategy—Laptop
Mobile SKUs are usually Thermal Design Power (TDP) limited, and power-specific optimizations should be considered to enable optimal performance on laptop computers. This is true particularly on Ultrabook and convertible designs, which use Intel® Graphics as the primary GPU.
Tools and Compatibility
The 12th Gen Intel Core processor platform will be supported by Microsoft, and other operating systems and system software developers, as well as by leading game engines. The following list continues to grow:
Runtimes
- .NET
- JS
- MSVC++
Performance Tools
- MSVC++
- Intel® VTune™ Profiler
- Intel SEP/EMON
- Intel® SoC Watch
- Intel® Implicit SPMD Program Compiler (Intel® ISPC)
Threading libraries for UMWAIT support
- Intel® Threading Building Blocks (Intel® TBB)
- MSVC++
- OpenMP*
* Intel TBB users will have to move to the newest OneTBB API to get full 12th Gen support.
Intel® VTune™ Profiler
The Intel® VTune™ Profiler will get full 12th Gen Intel Core processor support with the ability to see core grouping—where events and metrics can be grouped by core types. A set of predefined groupings will be available with the ability to create custom sets.
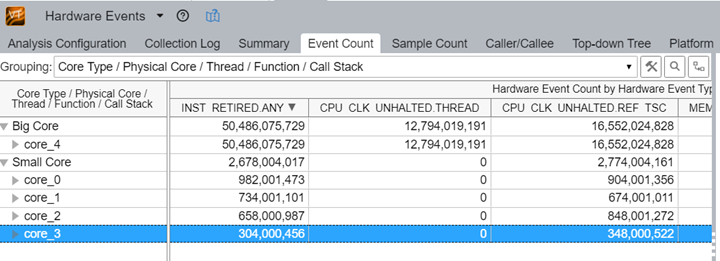
Figure 7. Intel VTune Profiler with predefined groupings
Specific Optimizations and Scenarios for Game-Engine Subsystems
The main benefit of the 12th Gen Intel Core processor platform for game developers is having high-performance cores running at a higher frequency, which allows an optimized system to run critical-path tasks as fast as possible. Choosing which tasks to prioritize is a key decision tree for taking full advantage of the architecture to handle critical-path tasks.
The main game thread starts the other threads and manages the other tasks. For efficient performance, developers should make the main thread as light as possible. One step toward efficient performance on the 12th Gen Intel Core processor architecture involves moving all workloads that can be parallelized to the “worker threads.” This idea is not new, as most developers have experience with managing parallel execution. The new consideration with the 12th Gen Intel Core processor performance hybrid architecture is that you now need to make sure that the main thread, which usually includes a job manager, is fully aware of the 12th Gen Intel Core processor architecture, and appropriately distributes tasks to the Performance-core or the Efficient-core cluster.
Render Thread
The Render Thread runs at its peak performance when running on P-Cores, and it handles the logic of submitting information to the GPU for rendering. It is a tremendous workload to parse through all of the lists of objects for each render pass, and set up their data in a way that the GPU can understand. Most rendering engines try to process these tasks as early as possible. For example, as soon as the engine can determine that the intensity of a light source is blocked by some objects, or where the light intensity is near zero, the engine will try to reject that light because it will add nothing to the scene, even if the GPU itself is able to reject it early in the pipeline. By rejecting it early in the render thread, you save a lot of the CPU processing work needed to get all of the data for that light into GPU data structures.
Scene Visibility, Including CPU Occlusion Culling
Understanding scene visibility is extremely important for efficient rendering and high performance. These tasks must typically occur as fast as possible, at the beginning of the frame, to allow the engine to start creating rendering work, and submit this work to the GPU. Therefore, you would want these tasks executed on high-performance cores. There are two major types of scene visibility:
- Hierarchical engine scene visibility, based on a variety of algorithms, such as BSP, Portals, AABB trees, and scene clusters, which are usually deeply connected with engine architecture
- CPU occlusion culling, such as masked occlusion culling (MOC)—a second stage of scene visibility where developers use a second pass to minimize the number of objects which were selected for elimination by the first stage, but still could be invisible and should be excluded from rendering with another review.
Occlusion Culling
Occlusion culling (OC) is the “fine-tune” opportunity to drop fully covered objects from being sent to the GPU for unneeded rendering. Modern OC could be done on the GPU and CPU, using occlusion test results in the next, or same, frame. Usually, the OC algorithm includes a very fast rasterization algorithm, often in small resolution, to see if any pixels of the tested geometry will pass the depth test, and will be rendered on the screen. In a case where there are zero pixels passing the test, the object can be defined as “covered”, and can be dropped from the main rendering. In CPU algorithms, such as Masked Occlusion Culling (MOC), rasterization is done on the CPU with very efficient vectorized code, which saves GPU time and is well-optimized for Intel® architecture.
Hierarchical Engine Scene Visibility
In every frame, a game needs to determine the list of objects that are visible from the camera’s point of view. Objects in the game world are usually organized in some kind of data structure to make searching easier, but these data structures sometimes struggle to deal with objects that move through the scene. If there are lots of dynamic objects, maintaining these data structures can be expensive for the CPU. On top of that, maintenance may be required for every camera view in the game.
In a given frame, there are often multiple camera views used to put a scene together. The main player’s view is the primary camera, but other cameras are often used in games—for example for security footage in spy games, or for shadows and lighting purposes.
Environment maps often make lighting more realistic. Usually, an environment is created from a specific location in a world by rendering that world six times to the sides of a cube. That’s six camera views. Many lighting models use dozens of environment maps in an area for accurate lighting. For example, Rockstar Games* wrote a system for environment map lighting that used 16 environment maps in one area for GTA Online: Los Santos Tuners. Because of the cost of computing scene visibility on the CPU for so many different locations, they could only update two environment maps per frame. Their solution was to update the 16 environment maps in a round-robin fashion, requiring eight frames to update all environments. Rockstar added logic to share what items were visible between different environment maps, and also to give preference to updating environment maps that were closer to the direction the player was looking in, or when there was a camera transition from a cutscene. The overall point is that there was not enough CPU power to update all of the environment maps in each frame, but, by making certain assumptions, they could handle the costs.
Efficient-Cores
E-cores run at a lower frequency, and thus execute instructions with lower performance, but have higher power efficiency. In mobile SKUs, E-cores are likely to be a major MOC workhorse. Thus developers will want to move most noncritical parallel workloads to these cores.
These workloads are described below and usually meet the following criteria:
Required:
- Asynchronous
- Outside of the critical path
Optional:
- Don’t load Performance-cores up to 100%
- Don’t overuse vector instructions.
AI
Since AI calculations can be done asynchronously and do not depend on frame rates, they are a natural fit for moving to E-cores.
In early versions of the Assassin’s Creed* franchise, crowds of non-player characters (NPCs) walking around interacting with each other put avoidable stress on the CPU. Additional stress comes from the random access nature of the AI data, causing excessive use of resources or conflicts in the caching system. When the player interacts with these crowds, the behavior of each NPC has to be modeled based on whatever rules the designers have come up with. Are the NPCs fearful, curious, or intrigued? How do they reach these states, and what actions do they take once they get to these states? How do the NPCs move to the next state, such as from calm to alert, to attack, to searching, to calm? Do they interact with each other while in these states? AI is used to deal with these questions during gameplay. Answering them for many NPCs can be a heavy task for the CPU, depending on how many unique NPCs are involved. Moving AI calculation to E-cores can lighten the CPU load.
Character Animation
Most games have animated characters, and a majority of the animation is now done with skinning, primarily utilizing the GPU. However, many games also use additional CPU processing to create more realistic animation.
For example, within the Frostbite* game engine, the CPU decompresses large volumes of high-quality animation data. Many game studios use motion-capture to create high-quality animation for game characters, and this data can be efficiently compressed. Then the data must be decompressed on the fly, before being sent through the pipeline to the GPU. Frostbite handles this process with high-quality animation, which can take quite a lot of time when there are many characters on the screen, each moving in a different way.
Game engines such as Frostbite and CRYENGINE* adjust animation data for terrain and collisions, combining with “Inverse Kinematics” for precise weapons-adjustment. Weapon aiming is typically a blend between four animations: upper, lower, left, and right poses. High-quality motion-capture data for events is usually done in one environment, such as on a flat surface, while, in the game, characters are moving on very diverse environment surfaces. Developers, therefore, have to adjust the animation to make sure the engine performs properly. Developers must also check that legs are on the ground, the body is rightly positioned on any surface angle, and so on. Creators want the character to point a weapon directly at its target, and when it collides with other objects it should realistically react. All these things are usually done on the CPU. And all these adjustments can usually be done asynchronously, which means such tasks are strong contenders for execution on the E-core array.
Physics
Physics calculations are usually asynchronous and run at their own frequency, which makes them excellent candidates to switch to the E-core array. Physics simulation is a key component for every 3D game since immersive experiences depend on complex physics-based interactions between objects, environments, characters, and effects. This includes collision detection and moving objects.
The game engine can implement physics simulation functionality on its own, or use a third-party physics engine such as Havok* Physics, Bullet, etc. Physics engines such as Havok use their own job-manager to perform multithreaded physics simulations, so expect middleware developers to make sure their engines are fully aware of the 12th Gen Intel Core processor architecture.
Physics calculations use a system of equations that must balance out. Typically, the physics engine works with its own frequency, or the frequency of the world/server, not connected with a rendering frame rate. That makes physics a good candidate to be moved to E-cores.
The core of a physics engine is usually called a “solver”. The solver tries to balance a system of equations describing the physical state of objects. When it is able to do this, and the equations are balanced, the physical objects come to a “resting state”. When the solver can’t do this, physical objects look like they’re twitching.
Often you can’t solve these equations directly, but you can take incremental steps towards the theoretical solution, and, once you get “close enough”, you can call it done. In most cases, the “close enough” state is within 0.001% of the real answer, and, in a fast-moving game, this situation works because players will never detect the difference. In other cases, however, the system isn’t able to get close enough to the real answer, and the twitching behavior displayed by the game degrades immersion. You can avoid these cases by adding more restrictions on how certain objects can move or interact with other objects. One example where restrictions help reduce twitching is a ragdoll with joints that can only bend so far.
When gameplay happens inside physical interiors—such as within trains, trucks, planes, or boats—the workload can be a burden for the CPU. Every gameplay object in this interior is automatically a physical object that the physics engine has to keep track of and solve for every frame.
Exterior environments are just as likely to have an overload of dynamic objects that need to be simulated but over a larger space. The trick is balancing the number of objects in either case to ensure performance. You can learn to take shortcuts by disallowing interaction until absolutely necessary, or stopping interaction after a certain amount of time.
Pathfinding
Pathfinding is another common algorithm which is particularly important in strategy games with hundreds and thousands of AI units, but also exists in many other games. It involves plotting the shortest route between two points, starting at one point and exploring adjacent nodes until the destination node is reached, generally with the intent of finding the cheapest route. Two primary problems of pathfinding are to find a path between two nodes in a graph and to find the optimal shortest path. Basic algorithms such as breadth-first and depth-first searches address the first problem by exhausting all possibilities; starting from the given node, they iterate over all potential paths until they reach the destination node. Since the calculations are repetitive and short and usually re-calculated in “world” frequency rather than per-frame, pathfinding is an excellent candidate to move to E-cores.
Collisions, Including Ragdoll Physics
One of the essential core functionalities of any physics engine is tracking movement, collision detection, and collision resolution between in-game objects. Ragdoll physics is a type of procedural animation that replaces traditional static death animations in video games, and when done properly, contributes to immersion. It is an operation that is suitable for moving to E-cores.
Destruction
Destruction engines simulate solid object destruction, providing important inputs that determine how realistic game-playing experiences get. The complex overhead of the destruction algorithms derives from the fact that destruction can spawn new objects on the fly, creating nested simulations that are extremely complex, requiring explicit thread scheduling. You can overcome this complexity by using “pre-broken” objects, then swapping instances out with the broken one and putting it under physics control with proper impulses. For environment deformation, such as terrains, you can implement deforming height maps or other similar constructs. An additional complexity for environment deformation is the rebuilding of the navigation mesh.
Fluid Dynamics
Fluid dynamics are complicated in general, but most physics engines try to simplify the problem by implementing custom solutions for specific effects such as water, clouds, weather, fire, etc. The use of such custom solutions depends on the type of game, whether it requires immersive fluid dynamics, and how critical the setup is. If water simulation is crucial to a game, developers may choose to de-prioritize the CPU time allocated to realistic weather simulations. Similarly, in some titles, precisely accurate fire simulations may not be required, and simple fire animations can suffice.
Particle Physics
Smoothly implementing particle physics is an essential part of almost any game and game engine. Particle systems can be very basic, and, if so, the GPU can execute them efficiently. Stateless particle systems also run efficiently on the GPU. However, as soon as you have complicated effects which interact with the environment and objects in complex collisions, the CPU becomes the better solution for managing such particle systems. Some particle systems can transition between CPU and GPU depending upon load. Animations can be done this way as well.
Sound
Sound systems are a great example of asynchronous workloads which can be moved to the Efficient-core (E-core) array. Sound workloads are usually scalable for quality and available capabilities and can run with various frame-rates.
Games usually use middleware to enable various sound effects, music, and other features. You should check with middleware companies to determine how these products implement 12th Gen Intel Core processor awareness. You will want to avoid cases where sound middleware becomes a 12th Gen Intel Core processor issue when it does its own thread/core management and pins exclusively to high-performance cores.
Summary
Developers must fully enumerate the available logical processors on a system to optimize for power and performance. You should design your software with performance hybrid architectures (such as the 12th Gen Intel Core processor) in mind. Prepare your code to support performance hybrid architectures by completing these steps:
- Enable hybrid topology detection.
- Implement architecture choices that optimize performance.
- Plan your thread scheduling in advance.
To familiarize you with the coding decisions you will face to optimize for hybrid architectures using both Performance-cores and Efficient-cores, Intel has developed a robust sample application and released the source code for you to inspect. Download the application from the link at the top of this document.
Frequently Asked Questions (FAQ)
The following is a list of Frequently Asked Questions to help developers understand specific issues around how to optimize games for the 12th Gen Intel Core processor performance hybrid architecture.
The 12th Gen Intel Core processor platform is expected to be launched in Q4 2021 & Q1 2022, worldwide.
Will the 12th Gen Intel Core processor only be available on desktop PCs, or will it also be available in notebooks and other form-factors?
The 12th Gen Intel Core processor platform will be available for entry workstation, desktop, notebook, Ultrabook, and convertible form-factors with various SKUs.
No. All cores will be available for applications without using any API. Developers might want to use the Microsoft API, however, (an example is provided in this paper) to detect the number and type of cores available for optimizing their applications to take the best advantage of each configuration.
Will the 12th Gen Intel Core processor platform be supported by Unreal* Engine, Unity*, and other common game engines and middleware?
Intel is working with leading middleware companies to ensure that the platform will be supported in future releases.
Yes. Hyperthreaded Performance-cores will share an L1 cache, while each of the Efficient-cores will have a dedicated L1.
Start with a cache map. You can associate caches with cores using GroupID/Mask, otherwise known as a group mask. This situation is demonstrated using the HybridDetect sample using GetLogicalProcessor/GetLogicalProcessorEx. See the screenshots below.

Figure 8. Associating caches with cores using GroupID/Mask, otherwise known as a group mask.

Figure 9. Associating a data cache with the associated cache on a logical processor.
If your existing or upcoming game uses a DRM middleware, you might want to contact the middleware provider and confirm that it supports hybrid architectures in general, and the 12th Gen Intel Core processor platform in particular. Due to the nature of modern DRM algorithms, it might use CPU detection, and should be aware of the upcoming hybrid platforms. Intel is working with leading DRM providers such as Denuvo* to make sure their solutions support new platforms.
Additional Resources
Intel Atom® processor family
Intel Atom® processor specifications
Intel Press Release for New High-Performance Graphics
Intel VTune Profiler Performance Analysis Cookbook
Intel® Parallel Studio Documentation
Intel® Architecture Instruction Set Extensions And Future Features Programming Reference
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Intel® oneAPI Rendering Toolkit
CES 2021 Intel Press Release including 12th Gen Intel Core Processor
Announcement
Detecting CPU Capabilities Using Unreal* Engine 4.19
How to Create Cache Maps by Microsoft
World of Tanks* 1.0+: Enrich User Experience with CPU-Optimized Graphics and Physics Article