Deep learning algorithms are widely used in the industry today – from detecting defects in parts on the factory production line to recommending products to shoppers on e-commerce websites. These algorithms proved their high accuracy and efficiency and have driven significant innovations in businesses utilizing them. These successes and promises have inspired everyone to utilize them in their projects: from a student in a lab project and an enthusiast, who wants to detect his cat in the home camera footage, to a developer from the corporation, looking to ensure that workers wear safety gear.
However, in the field of deep learning for computer vision, most of the academic research studies tend to provide the highest accuracy on the well-known industry standard – COCO benchmark, tuning features directly to this dataset. But, when applied on a more realistic dataset, that is neither perfect nor balanced, such solutions built on standard COCO benchmarks in general, perform unsatisfactorily.
Additionally, a model and training pipeline carefully optimized for a specific dataset rarely generalizes well to training on a different dataset. This problem in the AI field is called a “domain shift”. Moreover, fine-tuning and optimizing models and training pipelines for each use case is simply unrealistic, that requires extensive data science, developer, and compute resources – making AI initiatives unrealistic and cost-prohibitive in many cases.
In this article, our focus is to highlight the challenges in building such a pipeline for object detection computer vision models and discuss our approach to solving these challenges.
Essential Elements and Associated Challenges for Creating an Object Detection Model
There are 3 key elements that impact the overall deep learning model accuracy on a specific dataset and should be carefully tuned for each use cases:
- Architecture. Architectures define the structure of the neural network, enabling these networks to learn how to identify the influence of specific input components to achieve a specific output. These setups ultimately affect how accurate or efficient a deep learning model will be in final application at runtime. Additionally, new architectures are being developed frequently which adds the need to continuously evaluate them to develop the best model for specific use cases.
- Image preprocessing pipeline. Augmenting the dataset during pre-processing stages, such as by adjusting contrasts, perspectives, input sizes, etc. during preprocessing stages become important to make a model robust. However, it also makes finding a balance for efficient model training challenging.
- Training pipeline. Optimizing various learning parameters, such as learning rate, number of epochs, etc. – such technical details require expertise and make model training slow and computationally expensive.
Expert resources are needed if we are to build these model training pipelines for every use case. The resources and expertise needed to balance these aspects, while building an object detection model, make it challenging for broader adoption. It becomes further challenging if one intends to develop a broadly applicable and efficient model training template that can be applied across various use cases, with varying dataset sizes and complexities.
How Does Geti™ Software Solve these Challenges?
To address these challenges, we have developed an alternative approach: a dataset-agnostic template solution for object detection training. It consists of carefully chosen and pre-trained models together with a robust training pipeline for further training. Such a solution works out-of-the-box and provides a strong baseline across a wide range of use-cases.[1] It can be used on its own or as a starting point for further fine-tuning for specific use cases when needed. This solution forms the backbone of Geti™ software, Intel’s computer vision platform for model development, and enables users of Geti software to efficiently build object detection models.
For users who want to get a ready-to-use solution without diving into technical details, architectures, and various combinations of training parameter experiments, we have carefully chosen 3 templates, based on our research, to train on any dataset, each in different performance-accuracy trade-off regime at inference runtime[1]:
- The fastest model (SSD)
- The most accurate model (VFNet)
- The balance between speed and accuracy one (ATSS)
These final candidates can be deployed on supported hardware with the OpenVINO toolkit and even further optimized with OpenVINO’s Neural Network Compression Framework (NNCF) for optimal performance.
Template Solutions
These templates are the result of parallel training experiments on a corpus of 11 datasets, as described in the paper.[1] We optimized the choice of architectures and training tricks with respect to the average results on the whole corpora of datasets, as mentioned above, and performance-accuracy trade-offs.
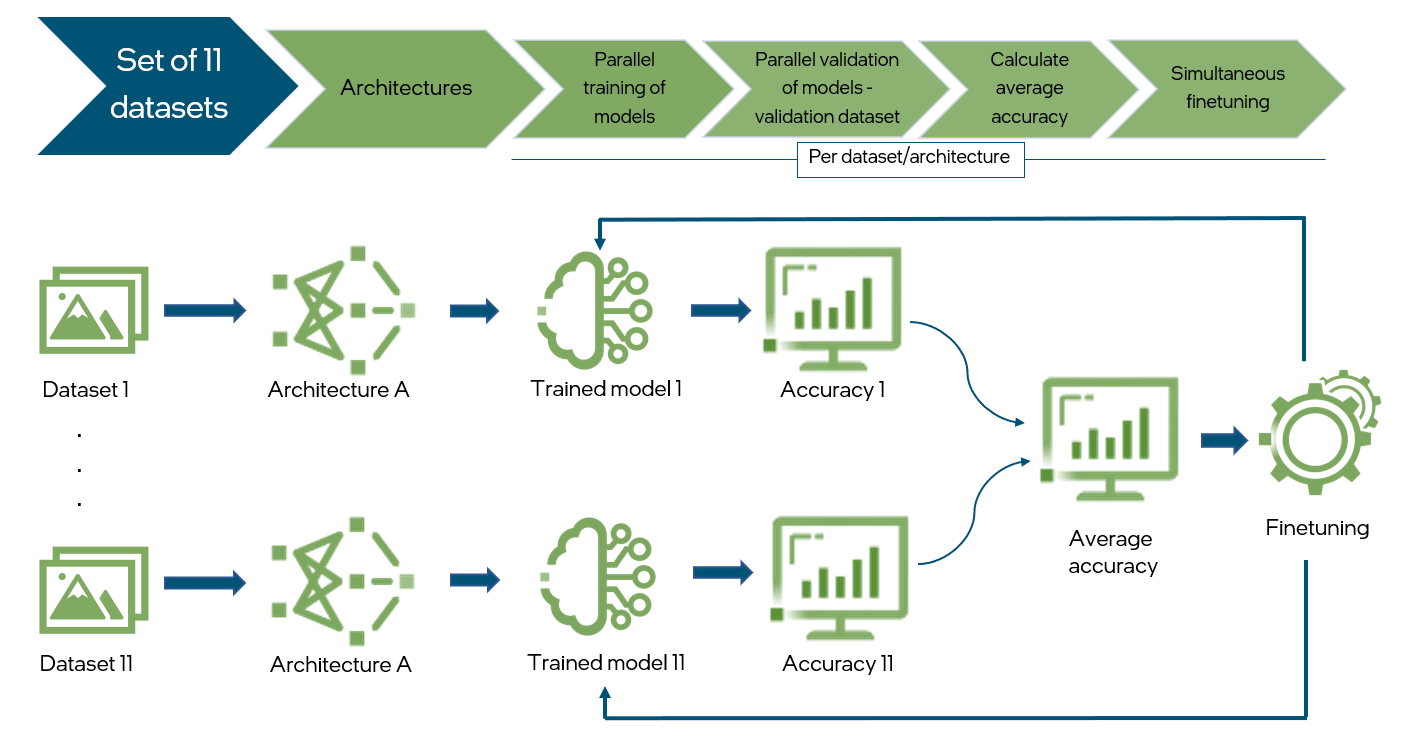
Workflow of the research methodology
Here are the most important elements considered when developing these solutions:
- Variability of datasets. To make sure that this solution achieves expected performance-accuracy trade-offs, we collected a set of 11 public datasets. They vary in terms of the domains, number of images, classes, object sizes, difficulty, and horizontal/vertical alignment. During experiments, we focused on the overall accuracy and behavior on each subset and each dataset particularly to make sure, that tricks work well in any use case.

Datasets used in the research. [1]
- Architecture choice. We conducted experiments on several different architectures for each of the 3 different regimes of accuracy-efficiency trade-off. Some of the results, including the “finalists” architectures, are shown in the table below:
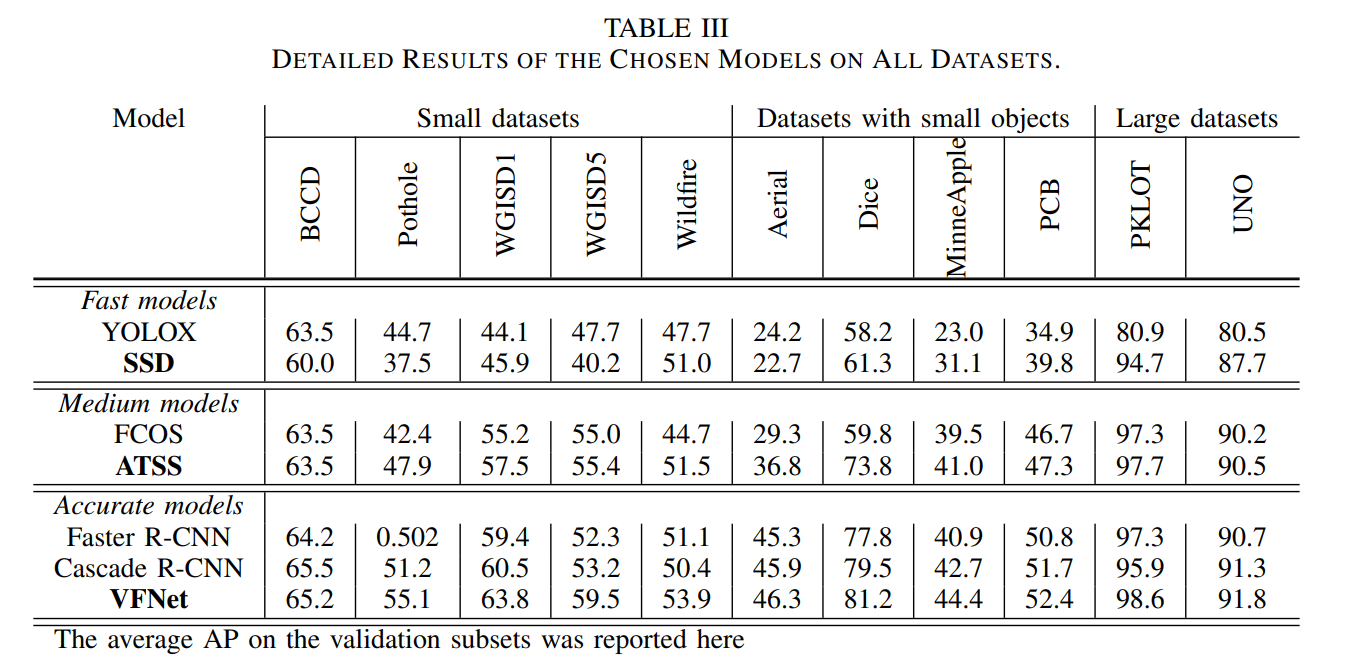
Detailed performance of chosen models across all datasets. The relative performance relies on specific model architecture recommendations for various performance-accuracy trade-off regime. [1]
These architectures were further optimized during the experiments.
- Data preprocessing. For data augmentation, we used classic methods that have gained the trust of researchers: random crop, horizontal flip, multiscale training, and brightness and color distortions. We also carefully tuned the resolution characteristics for each model to achieve the best quality results.
- Training pipeline: We introduced an “Early Stopping” mechanism to dynamically determine the number of epochs to train the model, based on the desired accuracy while reducing the training time. This allowed our training pipeline to balance itself based on the varying complexity of different datasets. We also introduced “ReduceOnPlateau” parameter to dynamically adjust the learning rate in our training pipeline, and iteration patience dynamically adjusts the amount of training based on the dataset sizes. [1]
Conclusion
The object detection training templates developed with this approach provide an efficient and broadly applicable model training pipeline, across use cases, dataset sizes, and accuracy-performance tradeoff needs. This template solution powers Geti software, Intel’s computer vision platform for model development, and enables users of Geti software to efficiently build object detection models. We have chosen model architectures for Geti software by evaluating the trade-off on various accuracy-performance regimes as described in this research. This enables users of the platform to easily select model architectures and efficiently train them for their use case taking advantage of the training template described in this research, without spending time evaluating themselves.
For more technical details on our experiments, check out the published research[1].
Reference
1. Galina Zalesskaya, Bogna Bylicka, Eugene Liu, “How to train an accurate and efficient object detection model on any dataset”, arXiv:2211.17170
Technical Details
System configuration for running parallel experiments described in the blog: 1 node, Intel® Core™ i9-10980XE CPU, 18 cores, HT On, Turbo On, Total Memory 128GB, Ubuntu 20.04.5 LTS, Kernel 5.15.0-56-generic, gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0, GPU NVIDIA Corporation GA102 [GeForce RTX 3090], driver version: 470.161.03, CUDA version: 11.4, 2TB NVMe SSD
1